自今年2月OpenAI的Sora首次公开展示以来,视频生成经历了从备受期待到遭受质疑的过程。在这大约10个月里,Sora迟迟未开放给公众使用,国内百川智能创始人兼CEO王小川则基于AI的路线判断“摁死”了公司跟进Sora的想法,另一些互联网大厂和大模型创业公司还在陆续跟进推出视频生成模型,但对外的发声表态也渐趋冷静。
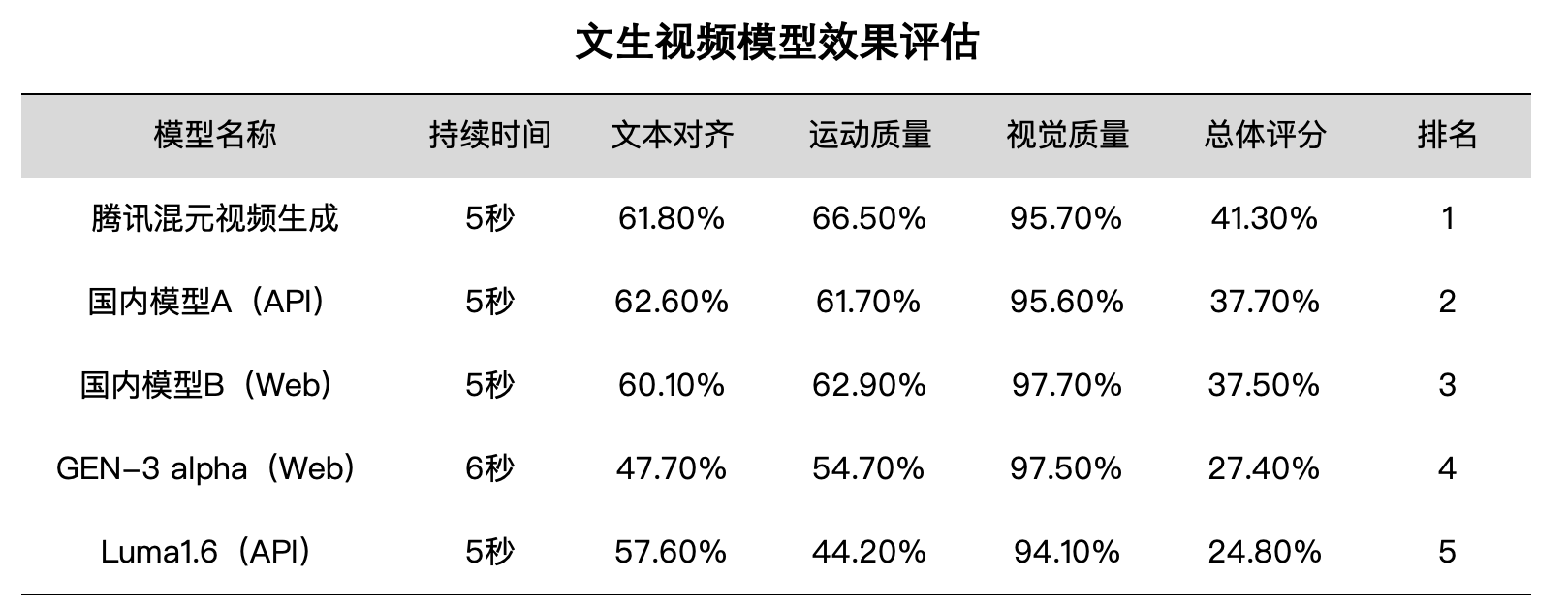
12月3日,腾讯混元大模型上线了视频生成能力,并开源了这个参数量130亿的视频生成大模型HunYuan-Vieo。据称该模型是业界参数最大的开源视频模型,可生成5秒视频。据混元团队公布的文生视频模型效果评估,混元视频生成模型总体评分41.3%,高于未公开名称的国内模型A和B以及海外的GEN-3alpha和Luma1.6。这项评估参照持续时间、文本对齐、运动质量、视觉质量几个维度,显示五个模型评分都不高,最低的Luma1.6评分仅24.8%。
接受第一财经等媒体采访时,腾讯混元多模态生成技术负责人凯撒直言,文生视频还不处于很成熟的阶段,各模型成功率都不高,至少文生视频的技术程度在混元内部的评估中,还没有到大规模商业化的程度,而是在技术打磨阶段。
从开源生态看,凯撒认为,现在视频生成开源生态也不是很成气候,最大的问题是开源的视频生成底模(基底模型)跟闭源差距太大。现在视频生成所需的算力、数据消耗量和图像生成相比是数量级的差距,业内不太想把自己花大成本做出来的模型开源出来。在这种闭门造车的情况下,最好的模型很多人也没有用起来,于是混元开源了自己的视频生成模型。
记者用混元大模型视频生成功能分别生成“三只黑猫在雪中玩耍,留下脚印”“三只黑猫在雪中追逐,留下脚印”和“一只戴着黄色围巾的企鹅在故宫门口吃冰糖葫芦”的视频。第一个视频生成三只黑猫在雪中,没有生成明显的脚印,但黑猫主体完整,脚踩在坑洼不平的雪地上时产生了正常的视线遮挡。第二个视频中,猫在雪地上踩出坑,有与物理环境的真实互动,但有两只黑猫融合成了一只。第三个视频场景正确且皮毛清晰,但冰糖葫芦会自己移动。记者此前尝试使用过一些主流的免费视频生成模型也发现,很多模型已能做到画面细腻真实,但运动规律或物理规律还不能很好体现。

从文生视频的具体难点看,凯撒告诉记者,对比文生图模型一次出一张图,这个视频生成模型要生成129帧画面,每一帧都正确非常难。视频生成算力会随着时间延长而呈平方级上升,且时长越长,画面退化越严重,业界目前主流都是五六秒。如果类比文生图模型,现在视频生成的水平就像两年前SD(StableDiffusion)还没面世时的水平。此外,视频模型无法足够真实地模拟世界的物理规律,例如掉下的杯子不碎,要改变这一点,背后涉及难度非常大的数据处理、清洗以及物理规律引入工作,后续混元将给视频模型引入真实世界的知识。
此外,记者了解到,视频生成模型的技术路径也还未完全清晰。凯撒表示,业界此前未解答“ScalingLaw(缩放定律)在视频领域存不存在”的问题,混元只能从头做,把视频的ScalingLaw走了一遍,验证图像和视频DiT(DiffusionwithTransformer,两者融合)也存在ScalingLaw,后续ScalingLaw还会进一步往下走。
业内其他厂商也对视频生成模型的进展和难点提出了新判断。11月,生数科技发布Vidu1.5版本,优化多主体一致性、上下文记忆方面表现。随后生数科技联合创始人鲍凡称,关于ScalingLaw是否“撞墙”,业内没有标准答案,存在ScalingLaw从数学理论上“撞墙”的可能,业内也在寻找新方法。架构上,业内架构已在一边收敛一边创新,此前业内有自回归和融合的架构之争,实际效果显示Diffusion和Transformer融合架构更优,于是包括OpenAI等公司都在顺延采用这种结构,同时业内也探索在新方法,例如解决DiT处理上下文能力欠缺的问题。而Vidu1.5的推出已表明这种Diffusion和Transformer的架构并非最优,接下来架构路线可能进一步调整。

文生视频模型除了炫技 没有任何的作用[吃瓜]