
DeepSeek除夕放大招,这绝对是AI行业最难眠的一夜了。
1月28日凌晨,人工智能社区HuggingFace显示,DeepSeek刚刚发布了开源多模态人工智能模型Janus-Pro,拥有10亿和70亿参数规模,仅使用128颗英伟达A100进行训练1周。其中,Janus-Pro-7B在GenEval和DPG-Bench基准测试中击败了OpenAI的DALL-E3和StableDiffusion。
简单来说,Janus-Pro模型既能让AI读图(基于SigLIP-L),又能让AI生图(借鉴LlamaGen),分1.5B和7B两个大小。要知道,GPT-4o的图片生成多模态模型至今没开放。
它到底有多么厉害?你看看DeepSeek给的案例:它能解答图片在杭州西湖,也能根据提示词生成惟妙惟肖的图片。
最近几天,DeepSeek爆火引发资本市场关注。1月27日美股收盘,英伟达(NASDAQ:NVDA)股价暴跌17%,收于118.58美元,市值蒸发近6000亿美元(约合4.3万亿元人民币)。CNBC称,这是“美国公司有史以来的最大跌幅”。
对此,英伟达方面回应称:“DeepSeek是一项卓越的人工智能进展,也是测试时扩展的绝佳范例。DeepSeek的研究展示了如何运用该技术,借助广泛可用的模型以及完全符合出口管制规定的算力,创建新模型。推理过程需要大量英伟达GPU和高性能网络。如今我们有三条扩展定律:持续适用的预训练和后训练定律,以及新的测试时扩展定律。”
128颗英伟达A100训练1周,Janus-Pro性能超OpenAI
事实上,DeepSeek一直在研发多模态生成式AI模型。
2024年前后,DeepSeek推出Janus,这是一种统一理解和生成的开源多模态模型(MLLM),它将视觉编码解耦,以实现多模态理解和生成。
Janus基于DeepSeek-LLM-1.3b-base构建,该库在大约5000亿个文本标记的语料库上进行训练。对于多模态理解,它使用SigLIP-L作为视觉编码器,支持384x384图像输入。
2024年11月13日,JanusFlow发布,这是一种用于图像生成的具有校正流的新型统一模型,也是一个功能强大的框架,引入了一种极简架构,将自回归语言模型与最先进的生成模型方法蒸馏相结合,它将图像理解和生成统一到一个模型中,
DeepSeek认为,蒸馏方式可以直接在大型语言模型框架内进行训练,无需进行复杂的架构修改。
2025年开年,Janus全面升级到高级版Janus-Pro。
具体来说,Janus-Pro是一种新颖的自回归框架,它将多模态理解和生成统一起来,将视觉编码解耦,以实现多模态理解和生成。它通过将视觉编码解耦为单独的路径来解决以前方法的局限性,同时仍然使用单一、统一的转换器架构进行处理。
这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。

不过,Janus-Pro架构与Janus相同,总体体系结构的核心设计原理,是将视觉编码解析以进行多模式的理解和生成,应用独立的编码方法将原始输入转换为功能,然后由统一自回归Transformer处理。为了进行多模式理解,我们使用siglip编码器从图像中提取高维语义特征。将这些特征从2-D网格平坦为1-D序列,并使用理解适配将这些图像特征映射到LLM的输入空间中。
对于视觉生成任务,Janus-Pro使用的VQ令牌将图像转换为离散ID。将ID序列平坦为1-D之后,我们使用一代适配器将与每个ID相对应的代码簿嵌入到LLM的输入空间中。然后,团队将这些特征序列加和形成多模式特征序列,然后将其送入LLM进行处理。除了LLM中的内置预测头外,团队还利用一个随机初始化的预测头来进行视觉生成任务中的图像预测。整个模型遵循自回归框架。
Janus-Pro基于DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base构建,超越了之前的统一模型,并且达到或超过了特定任务模型的性能。Janus-Pro的简单性、高灵活性和有效性使其成为下一代统一多模态模型的有力候选者。
值得一提的是训练,DeepSeek称,“我们在单个训练步骤中根据指定的比率混合所有数据类型。我们的Janus使用HAI-LLM进行训练和评估,这是一个构建在PyTorch之上的轻量级且高效的分布式训练框架。整个训练过程在1.5B/7B模型的16/32个节点的集群上花费了大约7/14天,每个节点配备8个NvidiaA100(40GB)GPU。”
也就是说,Janus-Pro最多用了256张英伟达A100GPU卡训练了14天,最少用128张英伟达A100训练7天,整个模型训练投入仅数万美金,这与数据规模、蒸馏方法等创新模式是分不开的。
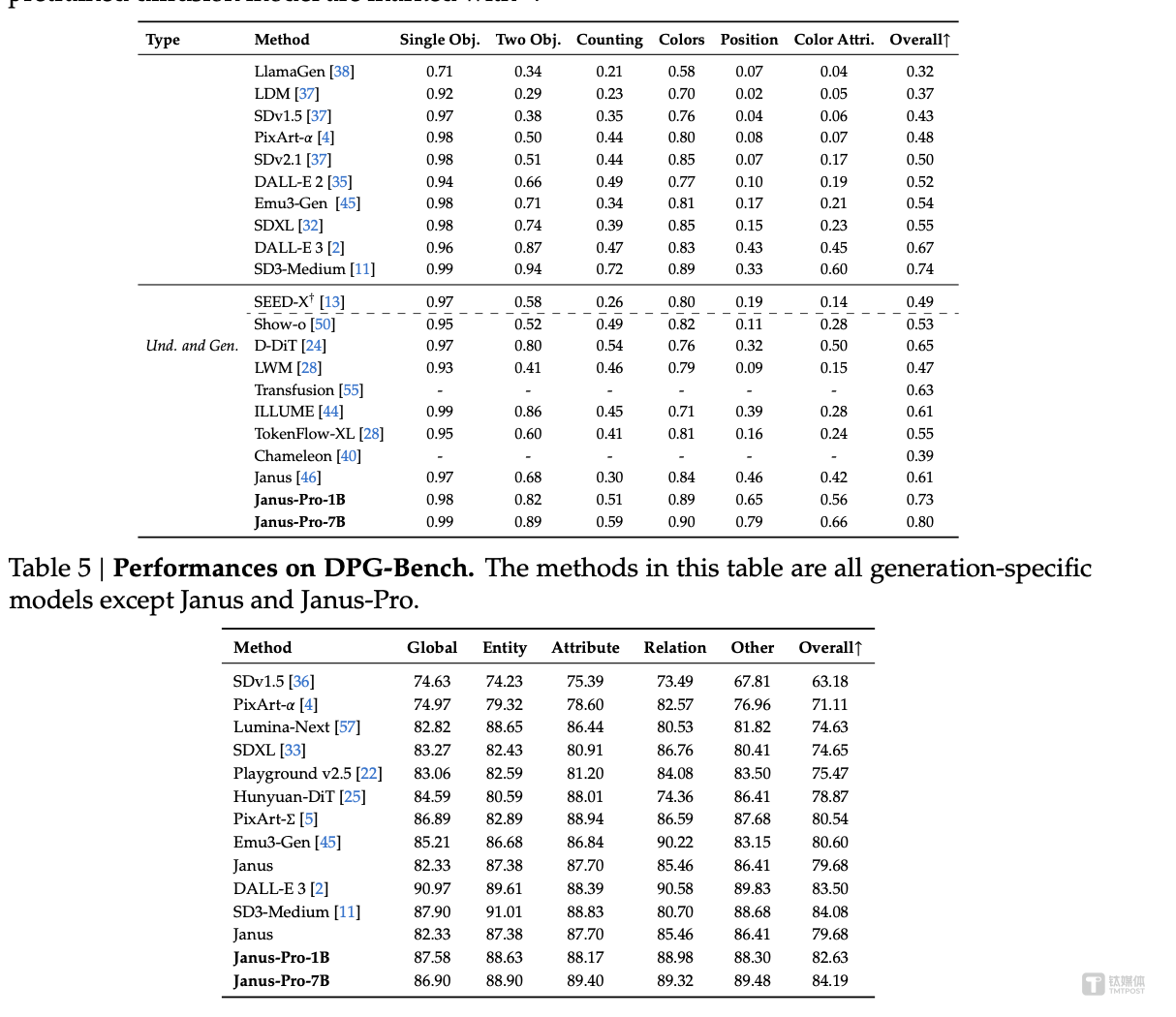
对外展示的多个基准测试显示,Janus-Pro卓越的多模态理解能力,并显着提高了文本到图像的指令跟踪性能。具体来说,Janus-Pro-7B在多模态理解基准MMBench上取得了79.2的分数,超越了Janus(69.4)、TokenFlow(68.9)等最先进的统一多模态模型,和MetaMorph(75.2)。此外,在文本到图像指令跟踪排行榜GenEval中,Janus-Pro-7B得分为0.80,优于Janus(0.61)、DALL-E3(0.67)和StableDiffusion3Medium(0.74)。
目前,Janus-Pro相关代码已经放在了GitHub当中。
此外,值得提醒的是,DeepSeek已经限制新用户注册了,仅支持+86手机用户,也就是锁区了,建议海外的朋友需要买虚拟号注册。
“近期DeepSeek线上服务受到大规模恶意攻击,为持续提供服务,暂时限制了+86手机号以外的注册方式,已注册用户可以正常登录,感谢理解和支持。”DeepSeek称。
AI算力格局加速演进
DeepSeek的模型证明了一个重要观点:打造出色的AI模型,未必需要昂贵的高端芯片;进一步表明AI技术并不存在明显的“护城河”,模型技术的超越已成为常态。
据论文显示,DeepSeek-V3开源基础模型性能与GPT-4o和ClaudeSonnet3.5等顶尖模型相近,但训练成本极低。整个训练在2048块英伟达H800GPU集群上完成,仅花费约557.6万美元,不到其他顶尖模型训练成本的十分之一。而GPT-4o等模型的训练成本约为1亿美元、至少在万个H100GPU量级的计算集群上训练;Llama3.1在训练成本超过6000万美元。
因此,这个发现对以高端AI芯片著称的英伟达来说无疑是个重大打击,其面临更多质疑。
1月27日,DeepSeek暴击华尔街,引发AI概念股的估值泡沫破裂担忧,欧美科技股市值或蒸发1.2万亿美元、Meta紧急组建多个小组研究复制DeepSeek的数据和技术,英伟达最深跌超18%,市值蒸发规模创美国股市史上最大,欧美芯片制造商以及为AI和数据中心供电的全产业链公司齐跌。
其中,英伟达迎来自2020年3月16日以来在市场上表现最差的一天,当日跌去17%。
上周,在英伟达超越苹果之后再次成为市值最高的上市公司,但周一股价下跌导致科技股占比较高的纳斯达克指数下跌3.1%,英伟达也降至市值第三高的上市公司,仅次于苹果和微软。
此次抛售的原因是人们担心DeepSeek在全球AI领域竞争加剧。去年12月下旬,DeepSeek推出了一款免费的开源大型语言模型,据称该模型仅用了两个月的时间和不到600万美元就构建完成,使用的是Nvidia的低性能芯片H800芯片组。
Cantor分析师在周一的一份报告中表示,DeepSeek最新技术的发布已经引起了“人们对其对计算需求影响的极大担忧,并因此担心GPU支出将达到峰值”。
对于英伟达来说,此次损失是该公司去年9月2790亿美元损失的两倍多,这是当时历史上最大的单日市值损失,超过了Meta在2022年的2320亿美元的损失。在此之前,最大跌幅是苹果在2020年的1820亿美元。此外,当前英伟达的市值跌幅是可口可乐的两倍多,并超过了Oracle(甲骨文)和Netflix(奈飞)的市值。
对此,英伟达予以回应,并否认Scale创始人、CEO亚历山大·王(AlexandrWang)的质疑。
AlexandrWang表示:“DeepSeek大约有5万张H100计算卡,他们显然不能谈论这件事,因为这违反了美国实施的出口管制。我认为这是真的,我认为他们的筹码比其他人预期的要多,但也会继续前进。他们将受到芯片控制和出口管制的限制。”
英伟达回应称,DeepSeek的研究展示了如何运用该技术,借助广泛可用的模型以及完全符合出口管制规定的算力,创建新模型。
华泰证券表示,DeepSeekV3训练成本相当于Llama3系列的7%,对当前世代AI大模型的降本做出了重要贡献;同时,目前北美四大AI公司主要通过扩大GPU集群规模的方式探索下一代大模型,DeepSeek的方式是否在下一代模型研发中有效还有待观察。此外,DeepSeek这次的成功显示,在ScalingLaw放缓的大背景下,中美在大模型技术上的差距有望缩小。
分析师HolgerZschaepitz表示:“中国的DeepSeek可能代表了对美国股市最大的威胁,因为该公司似乎以极低的价格建立了一个突破性的AI模型,而无需依赖最先进的芯片,这引发了对数百亿美元资本支出是否有用的质疑,这些资金正被投入到这个行业中。”
最新消息是,美国总统特朗普已经表示,拜登的《芯片法案》激励措施“荒谬”,预计他将对进口芯片征收高额关税。此外,他还提到DeepSeekAI技术是“积极的(positive)”表现。
“……想出一种更快、更便宜的AI方法,这很好。如果它是事实,而且是真的,我认为这是积极的,虽然没有人知道,但我认为这是积极的。”特朗普表示。

简章 纸短情长
我很怀疑deepseek是一帮玩金融的搞出来的ai,赚钱根本不靠c端[捂脸哭]
悠悠
[扁嘴]很尴尬的是,外国人做评测,外国人承认,国内一些顶着中国ip的台湾人红温了
智影
别再说中国人不创新了,一创就把各路大神打回原形[捂脸哭]
Little-snow●━●
正在遭受国家级网络的攻击。
执着
除夕,英伟达上涨百分之八,吹过之后,一如往常,痴人说梦去吧
1个我
中国:圣诞节,六代机中国:春节,大模型美国:咱能不能消停一下?
小西轰
华为研发的,找一个小公司发布是为了不出风头。
哔哩没有吧啦
今晚,英伟达会继续暴跌
kiko_小丽
感觉布了大局,专门做空美股,难怪不需要风投
小心愿
没什么用,我问的最简单的问题居然回答不了[捂脸哭]
无言
本以为也就是拿着铁锹挖人家祖坟,这才看见,怎么还有蓝翔租来的家伙
Aaorn
可惜呀,要是和投资基金合作,做空美国股票这一波至少赚10,000亿美元,美国科技股整体暴跌超过20,000亿美刀
削不好桃子皮
幻方买了一大堆英伟达芯片,然后打造deepseek在股市做量化割韭菜的,算是误打误撞吧
执着
吸血的蚂蝗它可不管吸的是谁的血