大模型正从语言、视觉向行动延伸。人形机器人还会现场写代码,出手解决问题。
谷歌DeepMind发布了两款新的具身智能模型,GeminiRobotics-ER与GeminiRobotics,正式宣告对物理智能的探索,从以往的RT模型系列,切换到了Gemini模型系列。用该公司高级研究科学家TedXiao的话说,这是前沿大模型与机器人的第一次接触。
无论是OpenAI、Anthropic,还是Meta,还都没有做到这一步。即使马斯克如此喜欢夸下海口,也还没让特斯拉的擎天柱用上xAI最新的Grok3。国内的DeepSeek或者Qwen,都没有直接让前沿开源大模型端到端地驱动人形机器人的记录。
遇到麻烦自己写代码
谷歌DeepMind先训练出具身推理模型GeminiRobotics-ER,基于Gemini2.0Flash模型,将多模态模型的语义理解能力扩展至物理几何(3D结构、物体位姿)、动态场景(运动轨迹、接触效应)等等,让身处复杂而动态的现实世界的具身智能,强化了推理能力。从中蒸馏出物理智能,就是GeminiRobotics,它能对现实世界做出反应。
比如,如果一个机器人遇到一个咖啡杯,GeminiRobotics可以识别出来,“指向”可以与自己互动的部分(比如把手),并识别出在拿起它时需要避开的物体。
机器人还会自己写代码去解决遇到的新问题(Zero-ShotViaCodeGeneration),就是个活生生的智能体。具体来说,就是模型接收输入,包括系统提示、机器人API的描述、任务指令以及环境的实时图像,然后基于这些输入,模型分析场景,理解任务需求,并生成与机器人API交互的代码。
这一过程是动态的,模型会根据环境变化与接触后的反馈,来调整代码,确保任务顺利完成。
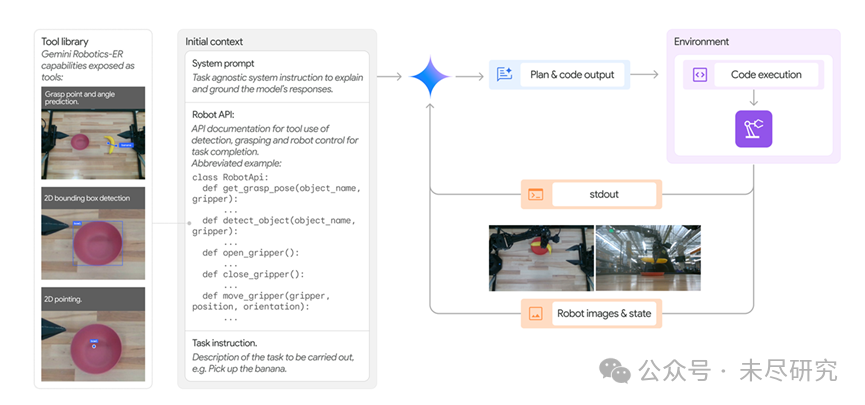
(概览图:感知和控制API,以及在任务执行过程中对智能体的协调和管理。该系统用于零样本控制。)
不过,这项技术还处于早期阶段,面对折叠衣服这样的精细任务,谷歌发现,还是通过少量人类示范的上下文学习(Few-shotin-contextlearning),成功率要更高一点。
或许这就是从RT系列模型转向Gemini系列模型的意义之一。以后,可能谁家的基础模型编码能力更强,谁家的机器人就是更灵巧的智能体。
但是,完成所有这些现场智能体推理和动作,需要强大的本地算力,目前仍然是个大问题。GeminiRobotics的视觉语言动作模型主干(VLABackbone)就放到了云端,其物理世界的理解能力适用于不同形态的机器人,可以通过日常对话与人类亲切交互。
GeminiRobotics还有一个动作解码器,负责将VLA主干的输出转化为低级控制信号,部署于本地,可以完成精细动作。
人形机器人的安卓
谷歌把GeminiRobotics用于自己投资的Apptronik人形机器人开发,还开放给受信任的机器人企业使用,包括德国的AgileRobots,法国的EnchantedTools,美国的AgilityRobotics,以及被韩国现代收购的BostonDynamics。
看起来,谷歌想做出一个人形机器人的安卓系统,初步实现了适配不同机器人。
巨头们毫不怀疑,未来,人形机器人的数量将比智能手机还多。它正在走向通用化,关键就在于通用的物理智能。谷歌、特斯拉、Meta与OpenAI等巨头,对此充满野心。
特斯拉的擎天柱是垂直自研的方式。Meta已经展露出类似的企图。而OpenAI在自己投资的PhysicalIntelligence与FigureAI纷纷垂直自研后,亲自下场的可能性同样大增。
上个月,Meta旗下的RealityLabs新设立了人形机器人部门。RealityLabs最为知名的就是它的元宇宙、可穿戴设备Quest,以及AI眼镜,累计亏损超600亿美元。Meta首席技术官AndrewBosworth说,公司砸钱搞出来的核心技术,可用于开发机器人,通过Llama覆盖消费者。
去年底,OpenAI在公司内部重启了人形机器人团队,并从Meta处挖来了Orion眼镜负责人,今年已经公开开始招兵买马,点名要那些精通传感器与系统集成的硬件工程师,“专注于解锁通用机器人技术,并在动态的现实环境中推动AGI级智能”。
让前沿模型与机器人接触,可以让机器人从多模态环境的经验中汲取智能,也可以在不断尝试中摸索数字世界的智能如何触及物理世界。谷歌CEO桑达尔·皮查伊(SundarPichai)介绍新发布的两个模型时称,机器人技术是将人工智能的进步转化为现实世界的有益试验场。
难以做题评估
谷歌承认,GeminiRobotics对具身智能的探索,仍然处于非常早期的阶段。谷歌在官方介绍中,放出了制作精美的视频。但随后,团队成员通过自己的X账号,放出了几段未经删节的视频。
如何评估具身智能模型实际水平,是该团队在发布GeminiRobotics前,一直思考的问题。在去年底的一次演讲中,团队提出三大瓶颈:机器人扩展定律,机器人上下文带宽,以及可扩展的评估体系。这是具身智能当前的短板,还将影响未来几年的研究方向。其中,评估体系的发展程度最低。
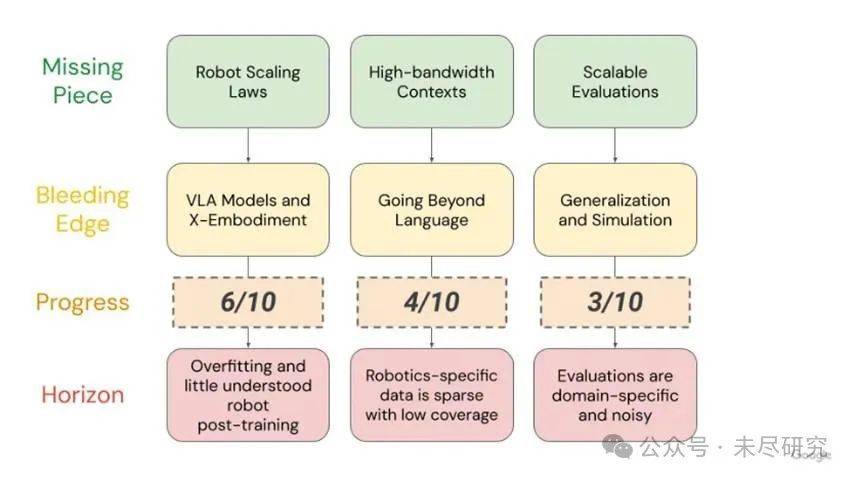
机器人扩展定律的核心,听起来与大模型扩展定律类似,数据越多,规模越大,理应效果越好。但是,谷歌DeepMind团队发现,在机器人领域,目前它并不每次都成立。
面对物理世界,扩展定律更像一门艺术,而不是科学(尽管本来也并非真正的物理定律)。机器人数据的质量、分布、多样性和覆盖范围,比数据数量本身更重要,研究者需要找到机器人扩展定律的那条曲线,预测投入和产出的关系。在机器人领域,扩展往往意味着比大型语言模型更高的成本,尤其是后者的边际效应已经开始降低。
还有“上下文带宽”问题,这是指机器人能接收和理解的动作指令的信息量。多模态或世界模型存在丰富细节与物理维度,作为大模型,已经拥有越来越大的上下文窗口,但是机器人动作相关的低层次指令往往相对简单,接受的token数量相对较少、模态丰富程度较低。如何在这种低带宽的输入方式下执行更精细的动作,或拓展其上下文窗口,是具身智能亟待解决的瓶颈之一。
最大的问题是验证。这次,谷歌DeepMind团队提出了ERQA基准,即包含400道多选的视觉问答(VQA)风格问题,涵盖包括空间推理、轨迹推理、动作推理、状态估计、指向、多视角推理和任务推理。语言模型可以用考试题测试,但机器人还得在真实世界里跑来跑去,才能试出它的真实性能;受限环境下的真机测试,在开放环境下不一定管用。
状况会在机器人越来越通用后变得更为复杂,因为评估它们的能力的难度与成本也随之暴涨。很多测试费时费力,还不够全面,难以覆盖极端案例。如果评估系统跟不上,机器人再聪明,也没法证明自己行不行。
一种方法是改进模拟环境,让它更接近现实,甚至期待用“世界模型”去代替部分实测。但是,这意味着后者可能必须学会建模出比机器人基础模型更多的信息。
我们周围会充斥着大量精心编辑的书面测评与视频演示,但现实世界的表现,仍将是具身智能领域的黄金标准。
