
(文/汤普济编辑/吕栋)
当地时间3月18日,黄仁勋于GTCAI大会上发表演讲,发布最新一代BlackwellUltraGPU(GB300)。同日,英伟达官方博客发布文章,宣布利用Blackwell架构GPU实现DeepSeek-R1模型推理性能的世界纪录。
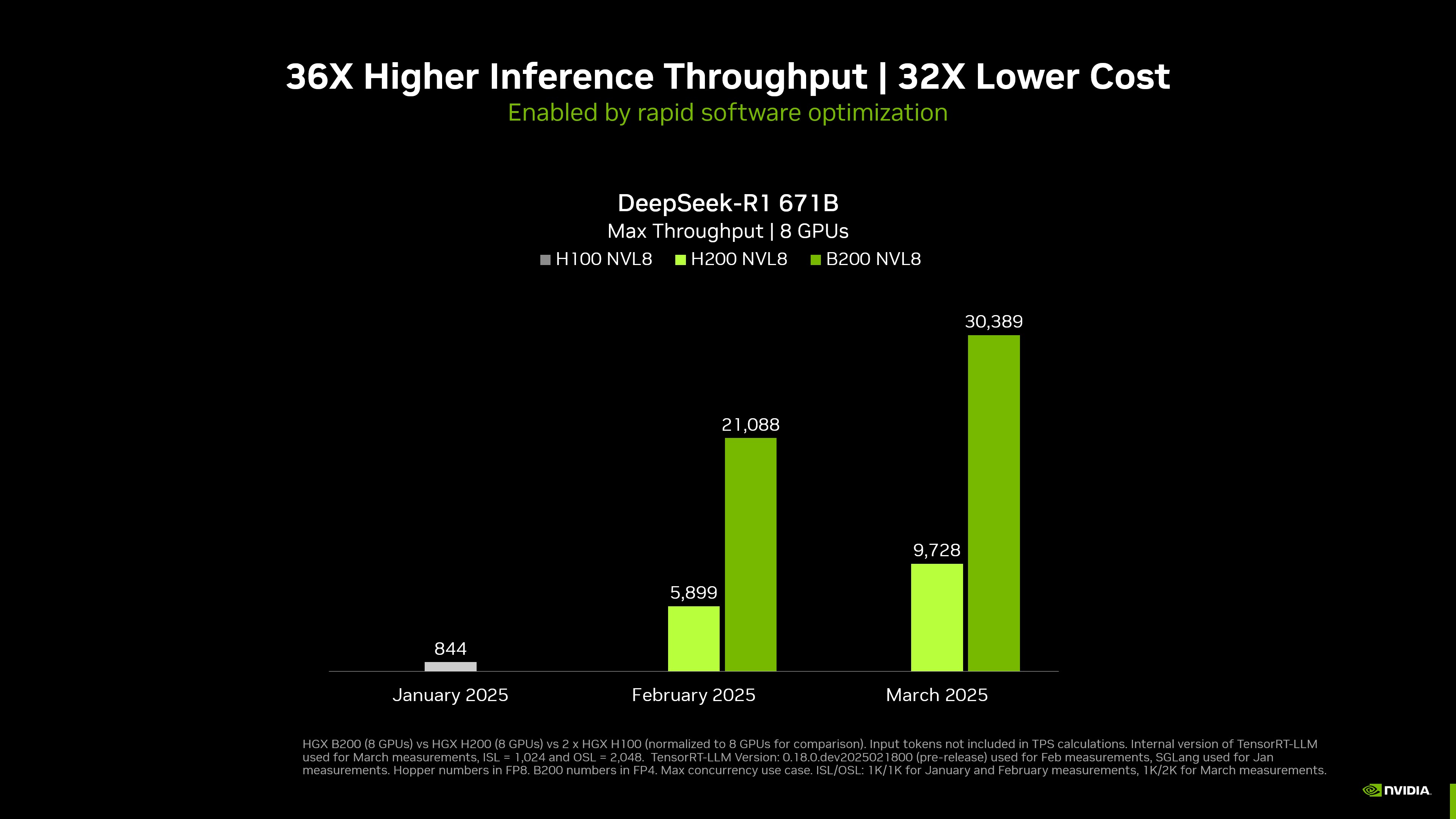
英伟达此次利用单个配备八块Blackwell架构B200GPU的英伟达DGX系统,在英伟达评价为“超大规模、最先进的“DeepSeek-R1模型上,实现每用户每秒可处理超过250个token的性能,或每秒最大吞吐量超过30000个token。
NVIDIA
英伟达于2025年1月30日在面向开发者的网站上发布NVIDIANIM微服务版的DeepSeek,之后,英伟达不断通过优化推理生态,刷新DeepSeek-R1模型的吞吐量。英伟达声称,自1月以来,DeepSeek-R1671B模型的吞吐量已被提高了约36倍,相当于每token的成本降低了约32倍。
同时,英伟达声称,纪录还将随着BlackwellUltraGPU和BlackwellGPU在推理性能上的突破刷新。
据悉,英伟达此次发布的GB300是全球首个288GBHBM3EGPU,FP4推理性能可达去年发布的GB200的1.5倍,峰值可达15PFLOPS。将在2025年下半年出货。
英伟达还预览了下一代AI超级芯片——VeraRubin,由RubinGPU和VeraCPU组成。VeraCPU拥有88个定制Arm核心、176个线程。Rubin由两块掩模尺寸的GPU组成,拥有288GBHBM4内存,FP4峰值推理能力可达50PFLOPS,相比GB300,整体性能可达3.3倍。
此外,英伟达还发布了用于加速AI模型推理的分布式推理服务库NVIDIADyamo,据称,在GB200NVL72架构上运行Dyamo推理,能使DeepSeek-R1模型的吞吐量提升30倍。
