本周全球被关税议题占据头条,但科技界的目光却聚焦在AI领域的密集动作上。
周末,Meta深夜突袭发布Llama4系列,号称“原生多模态+千万级上下文窗口”,并首次披露单卡H100可运行的轻量化版本。此前OpenAI则宣布O3和O4-mini模型即将在几周内上线,同时确认GPT-5因技术整合和算力部署问题推迟数月。
DeepSeek则与清华大学的研究团队本周联合发布了一篇关于推理时Scaling的新论文,提出了一种名为自我原则点评调优(SPCT)的学习方法,并构建了DeepSeek-GRM系列模型。结合元奖励模型实现推理时扩展,性能接近671B大模型,暗示DeepSeekR2临近。
Meta强势推出Llama4,多模态与超长上下文成亮点
周六,Meta正式发布了Llama4系列模型,Llama4全系采用混合专家(MoE)架构,并实现了原生多模态训练,彻底告别了Llama3纯文本模型的时代。此次发布的模型包括:
Llama4Scout(17B激活参数,109B总参数量,支持1000万+Token上下文窗口,可在单张H100GPU上运行);
Llama4Maverick(17B激活参数,400B总参数量,上下文窗口100万+,性能优于GPT-4o和Gemini2.0Flash);
以及强大的Llama4Behemoth预览(288B激活参数,2万亿总参数量,训练使用32000块GPU和30万亿多模态Token)。
此次公布的Llama4Maverick和Llama4Scout将是开源软件。然而,Llama4的新许可证对使用有一定限制,例如月活用户超7亿的公司需申请特殊许可,且使用时需遵守多项品牌和归属要求。
前kaggle总裁,fastAI创始人JeremyHoward表示,虽然感谢开源,但Llama4Scout和Maverick都是大型MoE模型,即使量化后也无法在消费级GPU上运行,这对开源社区的可及性来说是个不小的损失。
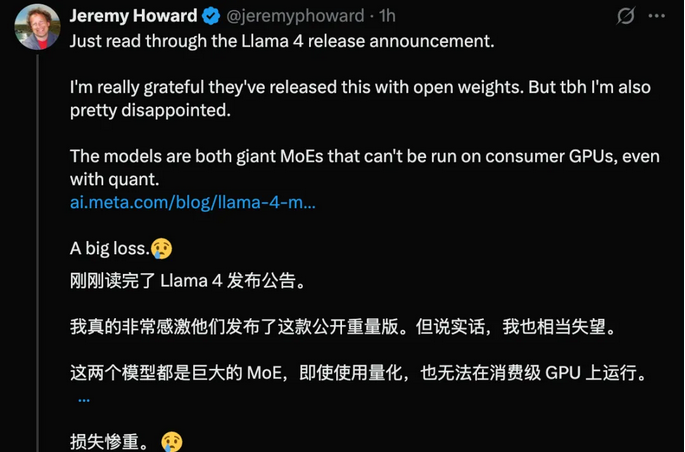
Meta强调,Llama4Scout和Llama4Maverick是其“迄今为止最先进的型号”,也是“同类产品中多模态性最好的版本”。
Scout亮点:速度极快,原生支持多模态,拥有业界领先的1000万+Token多模态上下文窗口(相当于处理20多个小时的视频),并且能在单张H100GPU上运行(Int4量化后)。
Maverick性能:在多个主流基准测试中击败了GPT-4o和Gemini2.0Flash,推理和编码能力与新发布的DeepSeekv3相当,但激活参数量不到后者一半。
X网友也对Scout模型的性能感到震惊,尤其是其在单GPU上运行并支持超长上下文窗口的能力。
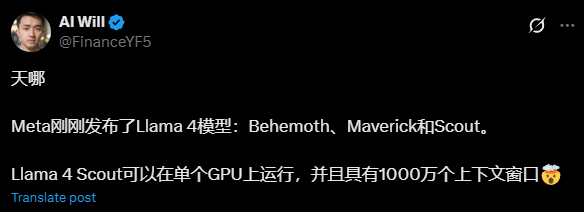
最令人瞩目的是Llama4Behemoth。目前Behemoth仍处训练中,不过Meta将其定位为“世界上最智能的LLM之一”。这个拥有288B激活参数和2万亿总参数量的“巨兽”,在32000块GPU上训练了30万亿多模态Token,展现了Meta在AI领域的雄厚实力。
有X网友指出了Behemoth训练的性能潜力,强调了它在阶段就已经表现出超越多个最高级模型的能力,例如Claude3.7和Gemini2.0Pro。
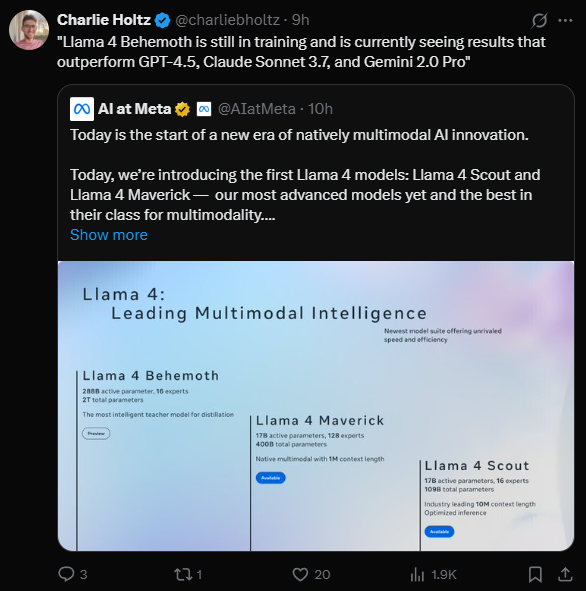
还有X网友调侃了Meta的“烧钱”策略,同时对Llama4的参数规模表示惊讶。
此前《TheInformation》周五报道称,在投资者向大型科技公司施压,要求其展示投资回报的情况下,Meta计划今年投入高达650亿美元来扩展其AI基础设施。
OpenAI确认O3和O4-mini即将上线,GPT-5免费策略引轰动
在Llama4发布的同时,OpenAI首席执行官SamAltman则在社交媒体上确认,O3和O4-mini将在未来几周内发布,而GPT-5则将在未来几个月与公众见面。
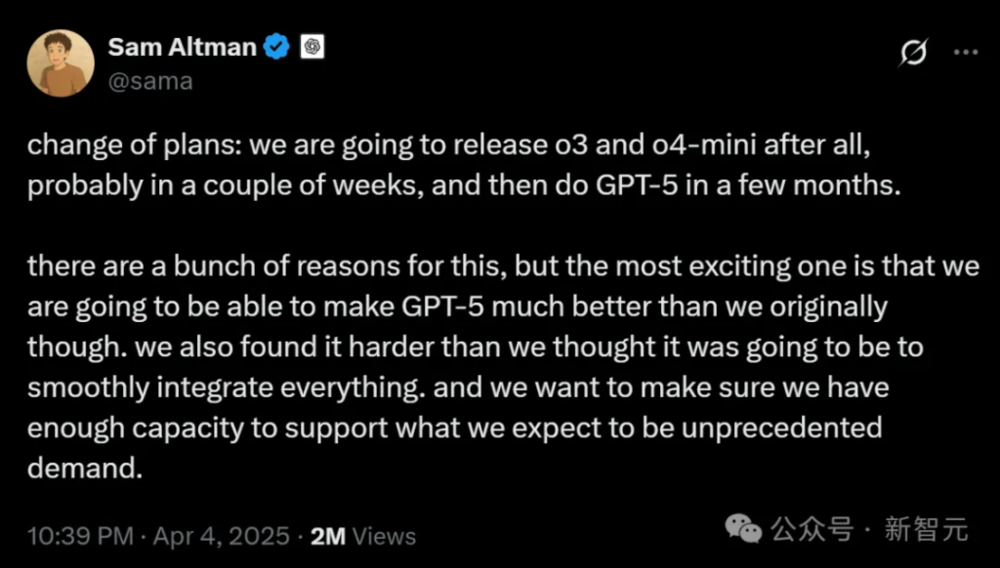
尽管没有更多关于o3和o4mini的细节内容,但是Altman表示,OpenAI在很多方面真正改进了o3模型,一定会让用户大为满意。
实际上GPT-5的功能和发布时间才是市场关注的重点。据Altman透露,GPT-5将整合语音、Canvas、搜索、DeepResearch等多项功能,成为OpenAI统一模型战略的核心。
这意味着GPT-5将不再是一个单一的模型,而是一个集成了多种工具和功能的综合系统。通过这种整合,GPT-5将能够自主使用工具,判断何时需要深入思考、何时可以快速响应,从而胜任各类复杂任务。OpenAI的这一举措旨在简化内部模型和产品体系,让AI真正实现随开随用的便捷性。
更令人兴奋的是,GPT-5将对免费用户开放无限使用权限,而付费用户则能体验到更高智力水平的版本。此前,奥特曼在和硅谷知名分析师BenThompson的深度对谈中,表示因为DeepSeek的影响,GPT-5将考虑让用户免费使用。
不过对于GPT-5的发布时间反复推迟,有网友做出了下面这个时间表来调侃。

DeepSeek携手清华发布新论文
DeepSeek与清华大学的研究团队本周联合发布了一篇关于推理时Scaling的新论文,提出了一种名为自我原则点评调优(Self-PrincipledCritiqueTuning,简称SPCT)的学习方法,并构建了DeepSeek-GRM系列模型。这一方法通过在线强化学习(RL)动态生成评判原则和点评内容,显著提升了通用奖励建模(RM)在推理阶段的可扩展性,并引入元奖励模型(metaRM)进一步优化扩展性能。

SPCT方法的核心在于将“原则”从传统的理解过程转变为奖励生成的一部分,使模型能够根据输入问题及其回答内容动态生成高质量的原则和点评。这种方法包括两个阶段:
拒绝式微调(rejectivefine-tuning)作为冷启动阶段,帮助模型适应不同输入类型;
基于规则的在线强化学习(rule-basedonlineRL)则进一步优化生成内容,提升奖励质量和推理扩展性。
为了优化投票过程,研究团队引入了元奖励模型(metaRM)。该模型通过判断生成原则和评论的正确性,过滤掉低质量样本,从而提升最终输出的准确性和可靠性。
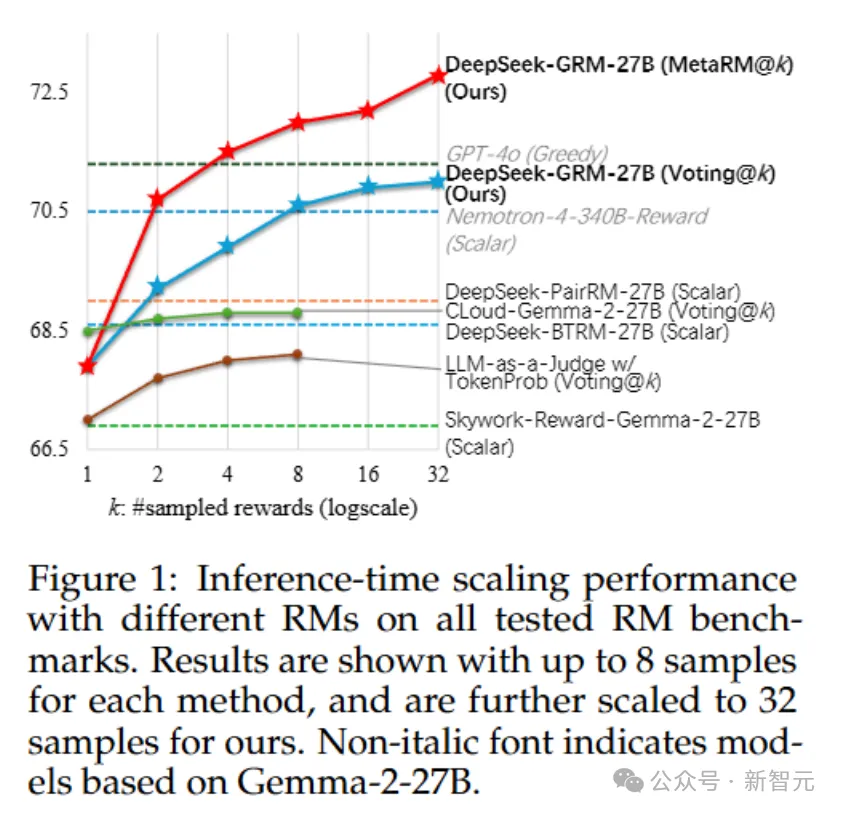
实验结果显示,DeepSeek-GRM-27B在多个RM基准测试中显著优于现有方法和模型,尤其是在推理时扩展性方面表现出色。通过增加推理计算资源,DeepSeek-GRM-27B展现了强大的性能提升潜力,证明了推理阶段扩展策略的优势。
这一成果不仅推动了通用奖励建模的发展,也为AI模型在复杂任务中的应用提供了新的技术路径,甚至可能在DeepSeekR2上能看到该成果的展示。
有海外论坛网友调侃道,DeepSeek一贯是“论文后发模型”的节奏,竞争对手Llama-4可能因此受压。