[#英伟达推DAM3B模型#:突破局部描述难题,让AI看懂图像/视频每一个角落]4月24日消息,科技媒体marktechpost昨日(4月23日)发布博文,报道称英伟达为应对图像和视频中特定区域的详细描述难题,最新推出了DescribeAnything3B(DAM-3B)AI模型。视觉-语言模型(VLMs)在生成整体图像描述时表现出色,但对特定区域的细致描述往往力不从心,尤其在视频中需考虑时间动态,挑战更大。
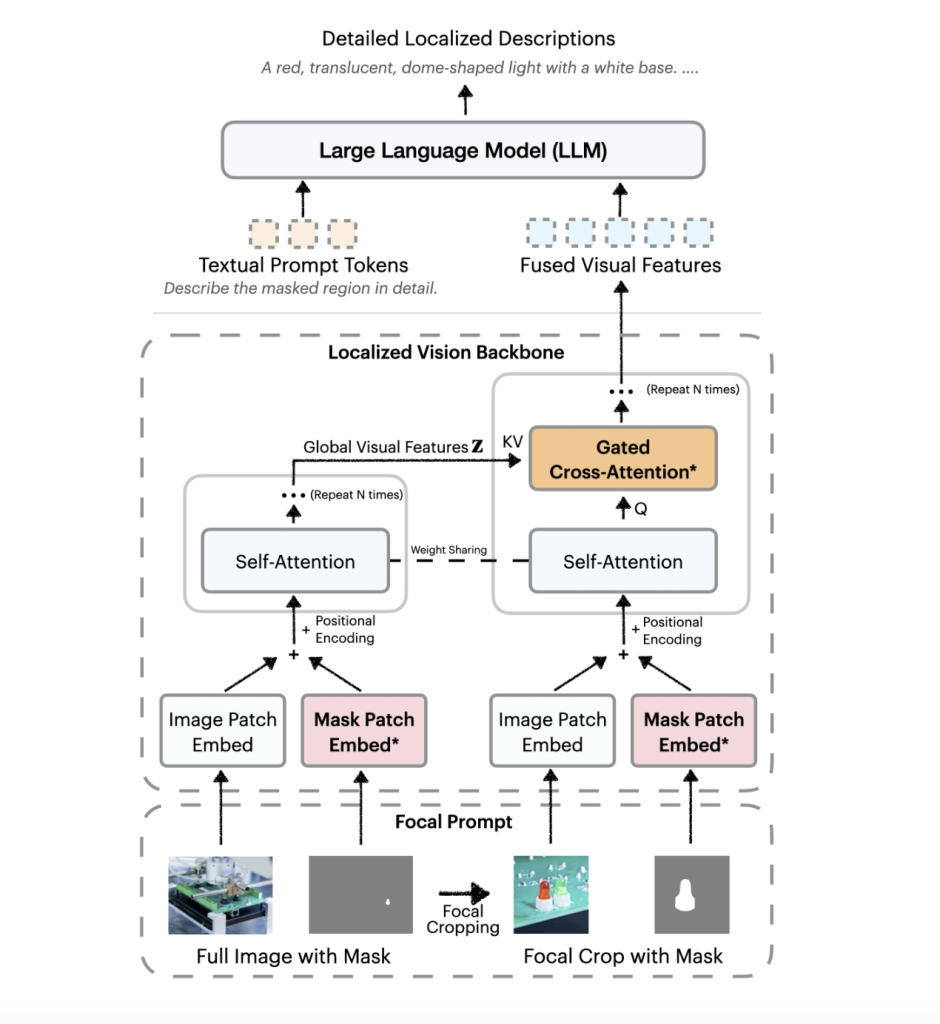
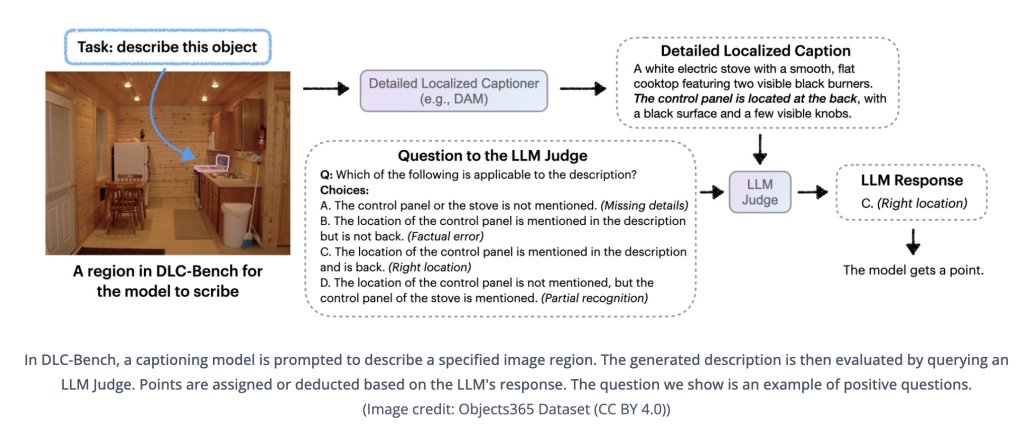
英伟达推出的DescribeAnything3B(DAM-3B)直面这一难题,支持用户通过点、边界框、涂鸦或掩码指定目标区域,生成精准且贴合上下文的描述文本。DAM-3B和DAM-3B-Video分别适用于静态图像和动态视频,模型已在HuggingFace平台公开。