小红书开源自研大模型小红书大模型推理只激活10%参数
小红书也下场搞大模型了,还一出手就是个“大动作”。
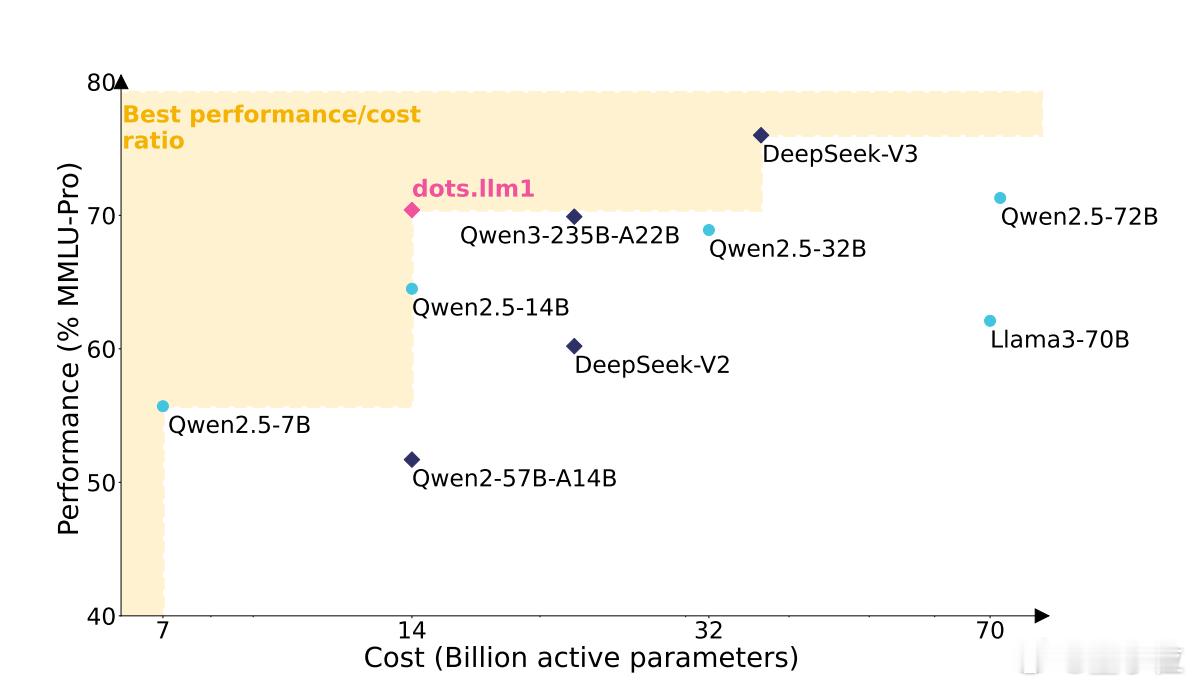
他们刚开源了自研大语言模型dots.llm1,参数高达1420亿,但推理时只激活10%——约140亿参数,做到了“省钱不降质”。在中文任务上,甚至干过了阿里家的Qwen2.5,还顺手比DeepSeek系列新模型分数更高。
以下是dots.llm1的重点信息,看看这个“小红书大模型”有多能打:
- 类型:MoE(专家混合模型),结构上是decoder-only Transformer;
- 参数量:总共1420亿,但每次推理只用到140亿,大大降低算力成本;
- 架构来源:在DeepSeekMoE的基础上改进。
在中文、数学和代码任务上,dots.llm1都小胜Qwen2.5-72B:
- 中文任务:91.3分(领先约1分)
- 数学任务:78.3分 vs 77.3
- 代码任务:59.6分 vs 59.0
- 英文任务稍弱:75.7 vs 76.3(但成本更低)
Github:
论文: