
在科技领域,一场关于人工智能模型的讨论正在风起云涌。
LeCun,一个在AI领域举足轻重的人物,他不久前在一场峰会上对热门的AI模型Sora提出了质疑。
这并不是一场普通的讨论,而是直接刺向AI发展的核心——理解物理世界的能力。
这场争论引起了广泛关注,大家都在好奇,这位AI先锋究竟在想什么?

而Meta又为何在这个时候推出了名为V-JEPA的新模型?
Sora首秀:不只是顶流Sora的初次亮相如同一场盛大的发布会,一下子吸引了整个AI界的目光。
大家纷纷惊叹于它逼真的视频生成能力,一时间,关于“现实不存在了”的讨论层出不穷。

更有甚者,OpenAI的技术报告指出,Sora能够深刻理解运动中的物理世界,称其为真正的“世界模型”。
不过,事情远没这么简单。
LeCun看了Sora的表现后表示:“凭文字提示生成一个逼真的视频并不等于理解物理世界。
这和通过世界模型进行因果预测是两回事。

他指出,目前的视频生成系统只是创造了一个“合理的样本”,并没有反映出真实世界的复杂性。
LeCun的观点:理解物理世界的关键LeCun的这番话震惊了不少人,也引发了广泛的讨论。
大家都在思考,生成一个逼真视频真的不意味着理解物理世界吗?

事实上,LeCun强调的是,生成视频的过程不同于世界模型的因果预测。
一个真实世界的后续路径可能性较少,尤其是在特定情况下生成这些路径的难度极大。
此外,生成这些视频的后续内容成本高昂,并且意义不大。
更理想的做法是生成抽象表示,而不是陷入细节。

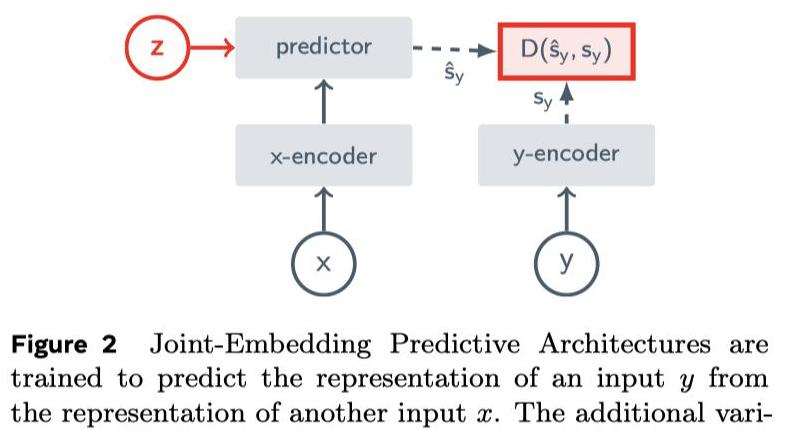
V-JEPA的核心思想正是如此,通过表示空间中的预测实现更高效的理解。
V-JEPA的独特之处Meta推出的V-JEPA,正是基于这种理念打造的。
它不同于生成式模型,而是通过预测视频中的被隐藏或缺失部分进行学习。

这与I-JEPA类似,但V-JEPA针对的是视频,而非图像。
它通过在观看200万个视频后,具备了非常强的预测能力。
这意味着什么呢?
比方说,当V-JEPA看到一个翻动笔记本的视频时,即便视频被遮挡,它也能够猜测出被遮挡部分的内容。

因为它不关注每一个像素的重建,而是通过抽象空间的表示来进行推测,这种方式极大提高了训练和样本效率。
未来展望:AI的视频与音频结合虽然V-JEPA已经展示了在视觉元素上的强大能力,但Meta的研究人员并没有停止脚步。
他们下一步的研究计划是结合视频的视觉和音频元素。

这种多模态的方法将进一步增强AI模型在复杂场景下的理解和预测能力。
这样的场景设想,不禁让人思考,如果未来这种技术能应用在增强现实设备上,例如苹果的Vision Pro,可能会带来多大的变革。
你家中的智能设备能够识别、理解并响应你的一举一动,这种未来离我们越来越近。
整个AI领域的争论其实反映了一个更深层次的问题——到底什么才是“理解”?

LeCun的观点让我们意识到,生成图片或视频并不等同于理解世界。
理解,需要更高层次的抽象和预测。
Meta的V-JEPA带来了新的可能,它展现了AI领域在不断进步,也让我们看到了技术未来的无限可能。
或许,有一天,我们真的会迎来能够像人类那样理解和思考的“世界模型”,那时,AI将不仅仅是工具,而是我们生活的一部分,与我们共同成长,共同探寻世界的奥秘。
我们期待着这样的未来,也希望每一步探索都能够让这个世界变得更加了解自身,变得更加美好。
