从“AI应用”到“全栈AI”,AI老兵未老,已悄然成长!
国产人工智能产业确实进入了一个高速发展阶段。
今年WAIC2025上国产AI厂商的“井喷”着实让市场见识到了,什么叫“百花齐放”。从AI大模型的智谱AI、百川智能、月之暗面,到AI基建的无问芯穹、硅基流动再到AI应用幂律智能等。不禁让人想起彼时那些初代的人工智能巨头们,比如国内“AI四小龙”之首的商汤科技(00020.HK),在大模型日新月异的舞台上,似乎光环暗淡不少,商汤老了吗?
01商汤大跌背后,是AI应用到全栈AI的阵痛期!
从资本市场角度来看,表现确实不尽如人意,原因为何?2021年底,正值AI视觉产业的高光期,商汤科技成功登陆港交所,创下当时国内AI企业最大规模IPO。上市即巅峰,市值一度突破3200亿港币,也曾是全球估值最高的AI应用厂商。这个预期主要基于公司2021年的业绩高点,凭借国内多年市占率第一的计算机视觉产品,2021年公司营收达到47亿,虽然巨亏170多亿,但作为初代国产AI,龙头+稀缺性+业绩预期,市场对于商汤给予了较高的市场预期。
但问题在于,商汤那时候核心的AI产品应用于智慧商业和智慧城市场景,这两块的收入占总营收比重达到了87%。换言之,公司营收对政府项目的依赖度非常高,而政府项目的特点就是交付周期长、账期长,而且更关键的是受到地方财政支出的影响,而2022-2023年恰逢地方财政进入转型期并开始收紧,没想到这么快就受到了影响。
了解地方财政的应该都知道,近三十年地方财政的收入来源除了税收,最核心的来源就是“土地出让金”,巅峰时曾占到我国地方财政收入的84.02%,即地方八成以上收入来源于卖地。2022-2023年算是一个转折点,当时资本市场还炒作过一阵“央国企价值重估”概念,目的就是希望将地方政府的“土地财政”转型“股权财政”,地方财政转型,首当其冲的就是削减支出,带来的结果就是2023年财政紧缩,导致商汤科技的政府订单锐减,当年智慧城市收入骤降27%,地方财政在智慧城市等方面的支出减少预期下,商汤股价便出现了断崖式下跌。
智慧商业方面,商汤科技的项目在核心服务模式上与SaaS(软件即服务)高度相似,可以被认为是一种“AI增强型的SaaS”或“AIaaS(AI即服务)”模式。然而无论怎么样,这种企业付费的商业模式就比较难发展和推广,一方面是国内对软件的付费意识不强,其次就是这种侧重于流程或中间环节的工具/服务,少有人为过程来做较高的定价,更多企业都是结果导向,这也成为商汤早期做AI应用的软肋。
核心业务一个大幅收缩,一个推广难度大。适逢2022年末,OpenAI推出的ChatGPT引发了全球对生成式AI的热情,也给商汤转型带来了契机,2023年商汤科技果断调整战略方向,将业务转向至生成式AI。与此同时,公司也将业务重组调整为生成式AI、传统AI和智能汽车三个板块。2024年底,商汤科技再度将业务重组为生成式AI、智能汽车及视觉AI。
多次调整之后,生成式AI已成为商汤的核心叙事。
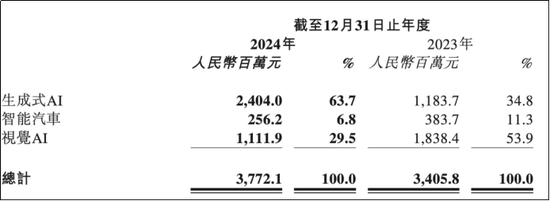
2024年年报显示,公司生成式AI的收入达到24.04亿元,同比增长103.1%,占营收的比重也从2023年的34.8%大幅提升至2024年的63.7%,成为第一大业绩驱动因素。相比之下,商汤起家的视觉AI业务在同年收入大幅下滑39.5%至11.12亿元,营收占比则从2023年的53.9%降至29.5%;智能汽车收入亦下降33.2%至2.56亿元,营收占比亦从11.3%降至6.8%。
如何理解商汤科技的生成式AI业务?
从AI发展阶段来看,商汤科技的视觉AI和智能汽车业务算是AI1.0的感知AI阶段,核心在于对环境和特定信息识别,依赖传感器(摄像头、麦克风等)采集环境数据,充当AI的“眼睛和耳朵”,主要进行感知,对识别后形成被动响应的指令,仅分析输入信息,不具备复杂的推理能力,不会生成新内容。举个例子,比如大门的人脸识别系统,仅需要输入家人面部特征的少量数据即可,当视觉传感器捕获符合数据的面孔就会开门;
而生成式AI是AI发展的2.0阶段,也是当前主流,核心就是需要海量的数据进行训练,就是让AI大量学习已有知识,然后根据不同任务、不同环境等进行推理,生成新的内容。商汤生成式AI的盈利模式偏向于算力租赁和MaaS(Model-as-a-Service),与互联网云服务厂商一样,其中算力租赁其实很好理解,就是现在越来越多的厂商开始使用各种各样的AI大模型,对于没有自建算力中心的终端厂商,就可以租用商汤的算力对自己的大模型进行训练。
实际上早在2018年前后,商汤就已经开始每年投入数十亿到SenseCore大装置上,截至2024年年底,商汤背后总算力已经达到23,000PetaFLOPS,覆盖京津冀、长三角、粤港澳等全国重点区域,支持动态调度;同时还建设了上海临港AIDC智算中心,是国内首个5A级智算中心,可支撑20多个千亿级大模型同时训练。商汤这一资本投入,并未获得市场的认同,原本就大幅亏损,巨额投入反而让商汤的现金流吃紧。不过,随着大模型的爆发式发展,算力需求高增,商汤所持有的算力能力也成为一种稀缺资源。
全球的资本市场似乎对自建算力都不太感冒,像Meta、Google和AWS这种云服务厂商,虽然一直在上修算力建设上的资本开支,但一看股价走势,基本没出现过多惊人的涨幅,或许是短期在业绩上的体现并不明显,不过全球“堆”算力却养肥了一批算力产业链,比如算力芯片、服务器、PCB、光模块等“卖水人”。
商汤另一种盈利模式就是MaaS。就是在自有大模型基础上进行微调,再通过垂直行业的数据进行大量训练,形成专用大模型,再按照用户对“云+端”两种模式需求获得收入。比如“大医”模型,主要是服务医疗领域,商汤本身在计算机视觉领域就很强,再借助海量的医疗知识和影像数据培养出了多模态能力极强的大模型,可以提供专业的医疗知识服务,更重要的是具备CT、MR和病理等多种医学图像的识别能力;还有在周末人工智能大会发布的“开悟”世界模型,就是由商汤日日新V6.5大模型赋能而来。
02如何理解具身AI?商汤又能做什么?
可能很多人都有一个认知误区:在AI高速发展背后,数据大爆发带来的AI需求指数级增长,然而数据即使每天都在增长,也并非是无穷无尽的。
实际上高质量数据是不足的,而相对有限的高质量数据正是训练LLM(大语言模型)重要“养分”之一,当然也可以通过算法优化来强化文本数据质量,但上限明显。
根据2024年研究机构EpochAI通过分析互联网公共文本数据总量与AI训练需求增速,预测到未来10年内,数据增长的速度无法支撑起大模型的扩展,LLM会在2028年耗尽互联网上的所有文本数据,机构预测互联网高质量文本的年增速不足5%,将远低于AI数据需求的指数级增长。
目前大模型对文本数据消耗速度惊人,以ChatGPT为例,2021年的GPT-3的训练消耗了约3000亿Token的文本数据,2023年的GPT-4训练已经消耗了约13万亿Token的文本数据(13万亿token什么概念,相当于1万套《四库全书》的文本总量,一套8亿汉字),而GPT-5等下一代模型的需求量可能翻倍,根据《华尔街日报》的报道,OpenAI在训练GPT-5时已经遇到了文本数据不足的问题,正在考虑使用Youtube公开视频转录出的文本。
正如OA在训练方式的变化,视频转录文本训练大模型意味着图片和视频数据还有巨大的挖掘空间。目前市场预期大模型消耗数据的一个顺序是文本→图片→视频,而从文本到图片和视频的训练和推理就需要使用多模态大模型,即同时处理、理解并融合多种数据类型(模态)的人工智能模型,而商汤早期机器视觉的技术优势或许可以发挥到淋漓尽致。
相比于先从视频转录出文字,然后用文本训练。商汤视觉感知+语言能力的多模态大模型似乎更像人类的“感官协同”的思维模式,举个简单的例子:早上出门,手机落在家里的桌子上,我们的大脑内形成的是“手机在桌子上”这一文本信息与“手机静置在桌面上”的画面会同步出现在大脑内。当然很多头部大模型厂商也都在开发多模态大模型。
生成式AI进阶到具身AI,笔者的愚拙理解是:生成式AI类似于人类的学习阶段,我们从小学到大学的学习中,尽可能地大量汲取通用或专用方面的知识,从教科书(文本)到实习(图片和视频)都是在训练和简单推理的过程;而具身AI就相当于走向工作岗位,在实时场景的交互实践中,根据复杂的时序数据,尽可能做出最优的推理和决策。
这也对应了大模型厂商的一种思考:当书本与互联网知识穷尽时,下一代的智能将从何处获取新的数据?经典的宏微观经济学加一起也就不过千页,但实际生活中,经济学复杂且庞大,未来每一次最优的决策都是基于上一次并非最优决策过程的总结和学习。我们称之为“经验”“经历”,而这些“经历”正是从生成式AI进化到具身AI期间,大模型在所处垂直领域交互中获得的新数据,用于自我训练和推理。
人形机器人和汽车智能化发展都是具身AI最好的落地应用。除了多模态的大模型算法和软件,终端的“感官”技术支持也相当重要。表面看商汤虽然在资本市场表现比较一般,但在AI发展浪潮中并未落后。左手计算机视觉(CV)的技术+模型,右手是通用大模型,背后还有自建的国内领先的算力中心和自研的推理芯片等硬件支持。这些足以支撑商汤在AI端侧爆发预期下的发展。
曾经的“AI四小龙之首”还没老,反而悄悄地完成了从“AI应用”厂商到“全栈AI”的升级。