Chroma最新报告《Context Rot》揭示LLM在处理长上下文时表现非均匀,带来深远启示:
• 18款主流模型(包含GPT-4.1、Claude 4、Gemini 2.5、Qwen3)均表现出输入长度越长,性能越不稳定,远非传统假设“所有token等效”。
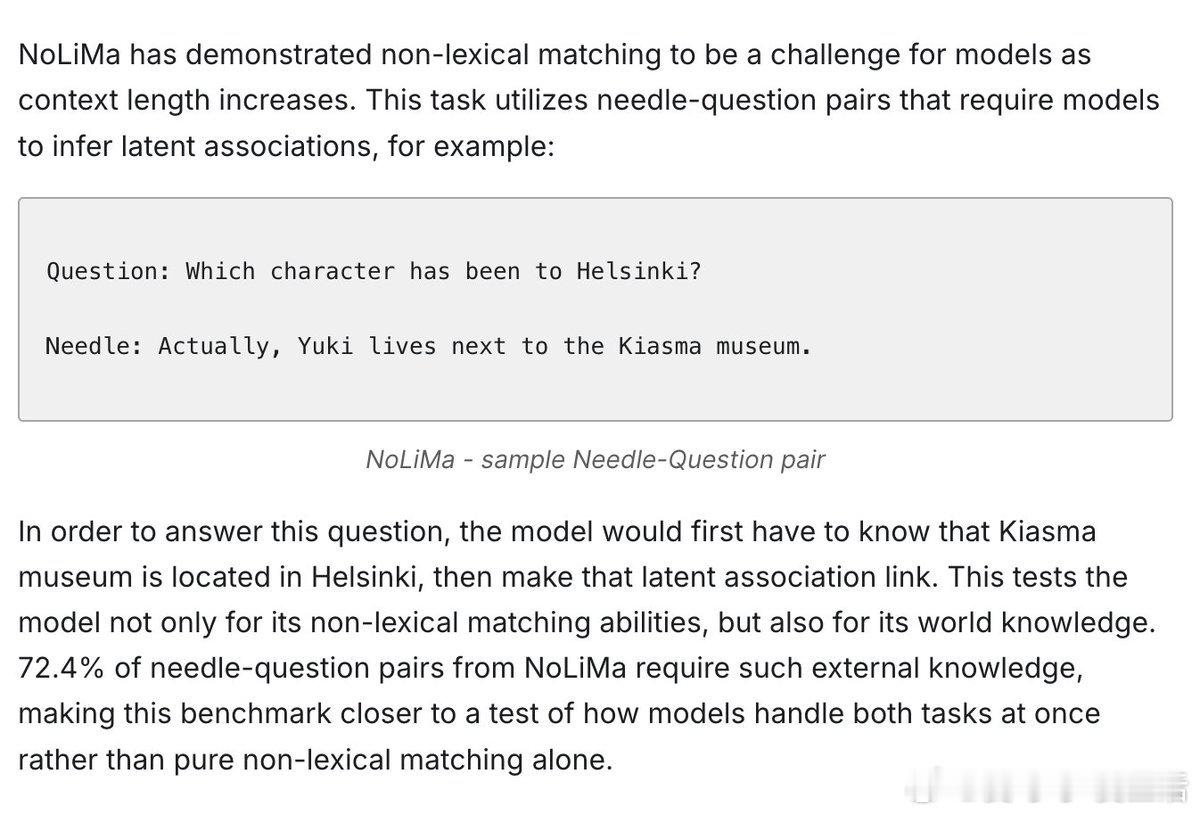
• 扩展经典“Needle in a Haystack”任务,加入语义匹配、多层次干扰项,发现低语义相似度的问答对性能衰减更明显。
• 干扰项对模型破坏性极大,且影响不均,Claude系列更倾向于保守放弃回答,GPT系列则更易产生幻觉输出。
• 语义上与背景文本高度相似的“needle”反而增加识别难度,且保持语义连贯的文本结构反而让模型表现更差——暗示模型对上下文结构敏感。
• 真实对话长上下文(LongMemEval)中,精简聚焦内容显著提升表现,支持重新开新话题、上下文浓缩策略。
• 简单重复词任务中,模型随着输入输出长度增长表现明显退化,包含拒答、随机输出等异常,验证了长上下文自回归生成的复杂性。
• 研究强调“上下文工程”重要性:不仅需保证关键信息存在,更要合理组织上下文结构以避免性能下滑。
• 实践建议:避免无限制拼接历史对话;积极利用摘要浓缩上下文;警惕“过度推理”带来的长上下文负面影响。
本报告兼顾合成与实用任务,代码开源,助力社区验证与优化长上下文应用。详细解读👉research.trychroma.com/context-rot
大语言模型 长上下文 语义检索 AI性能 上下文工程 模型鲁棒性