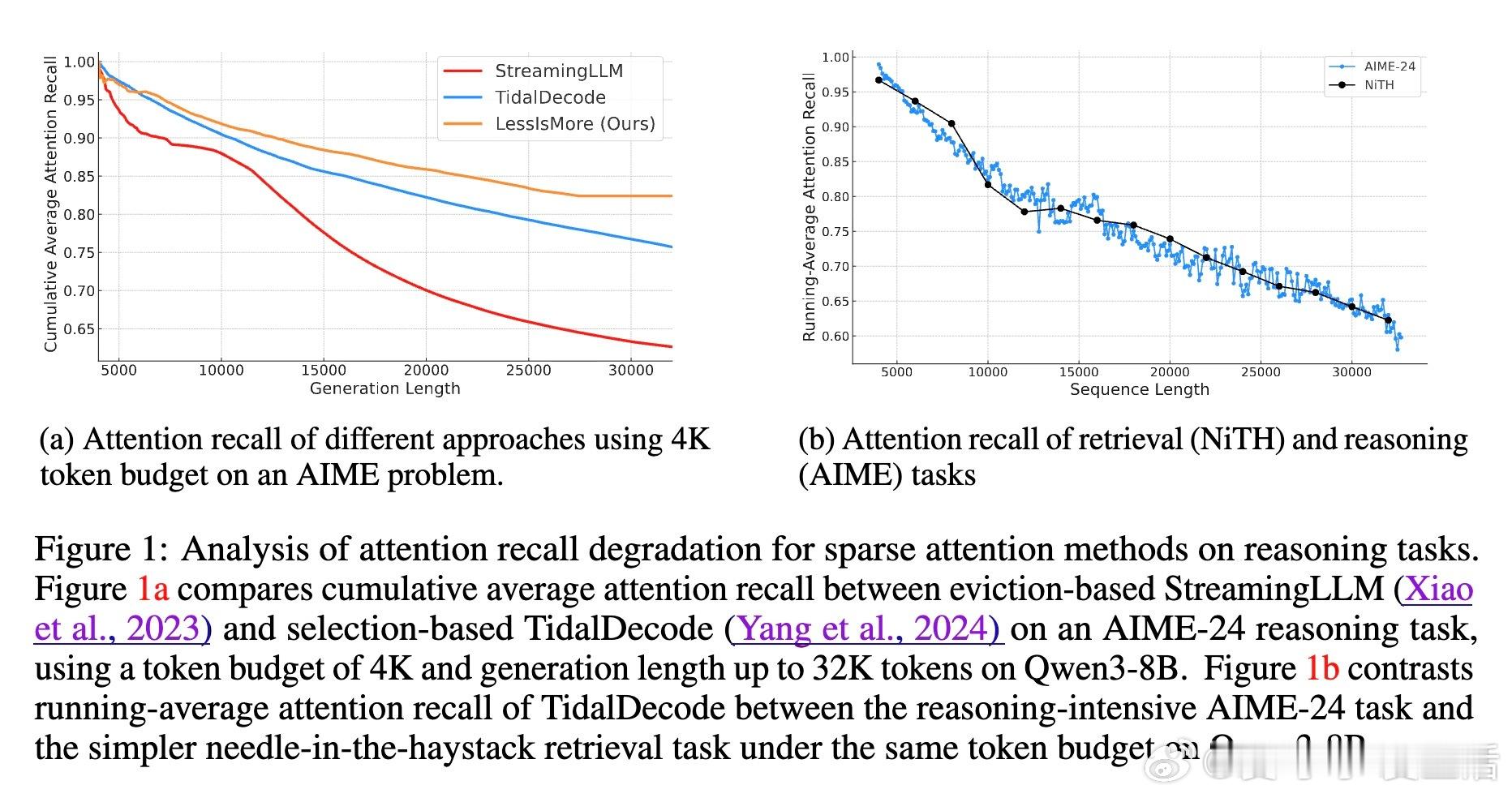
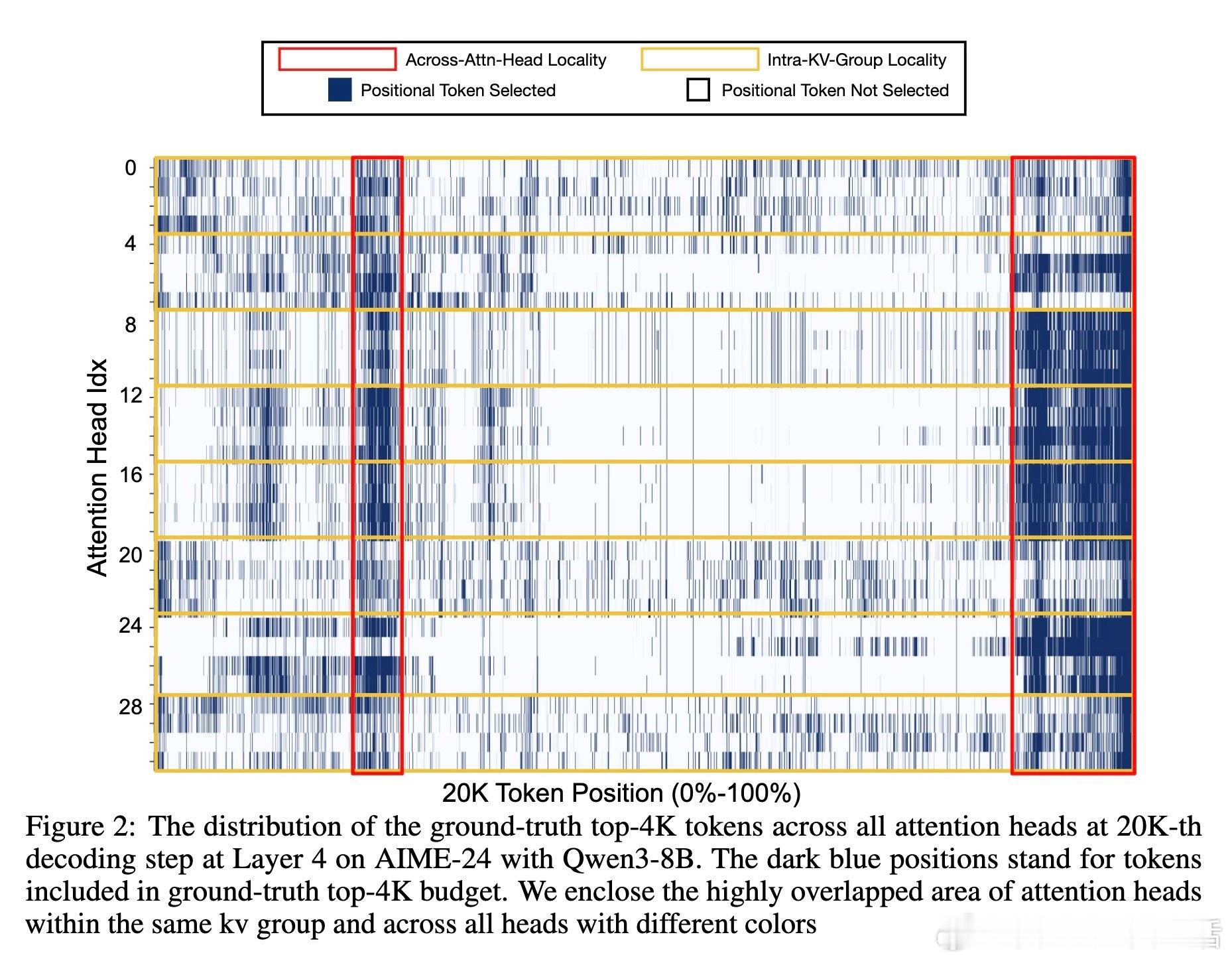
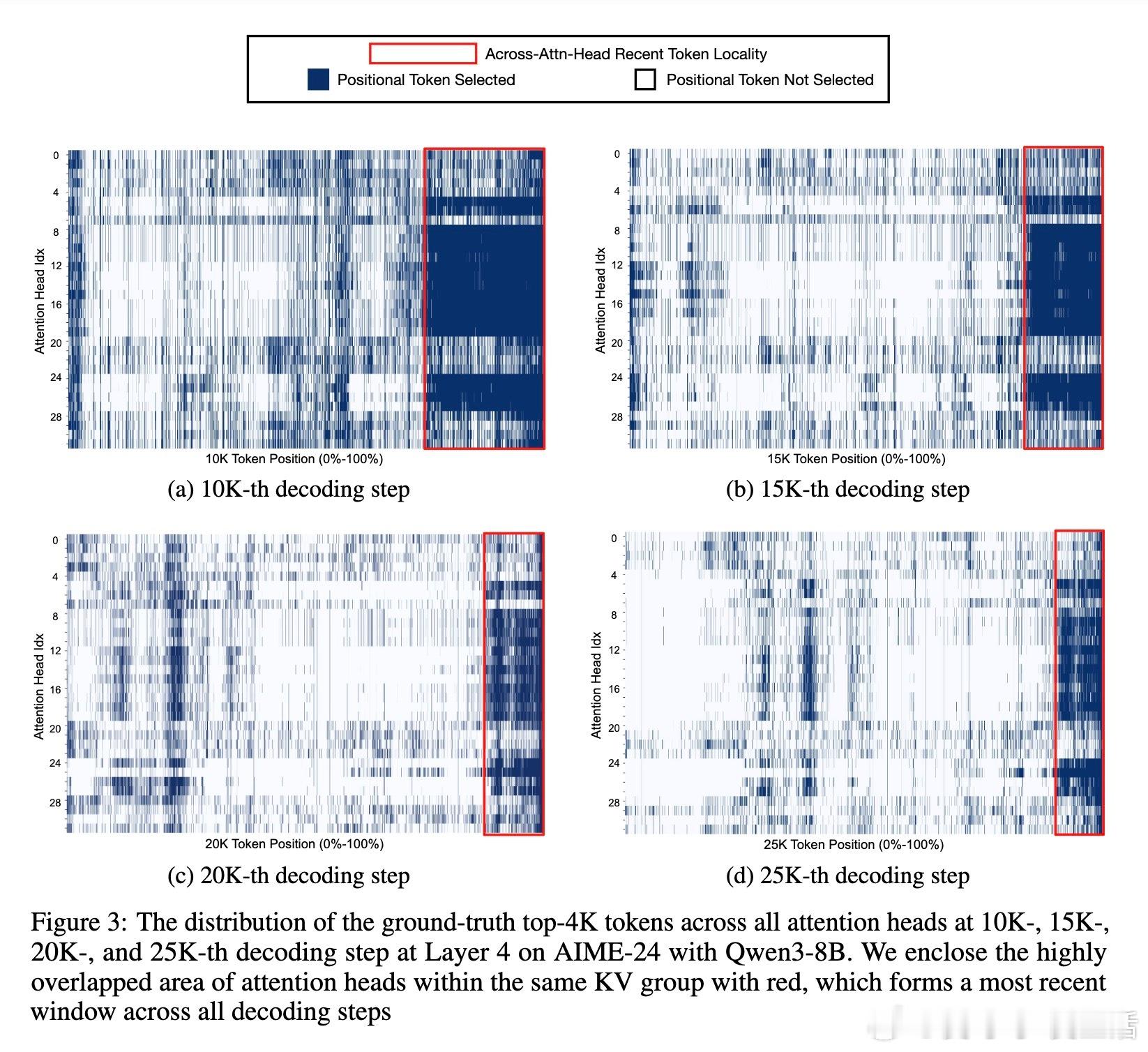
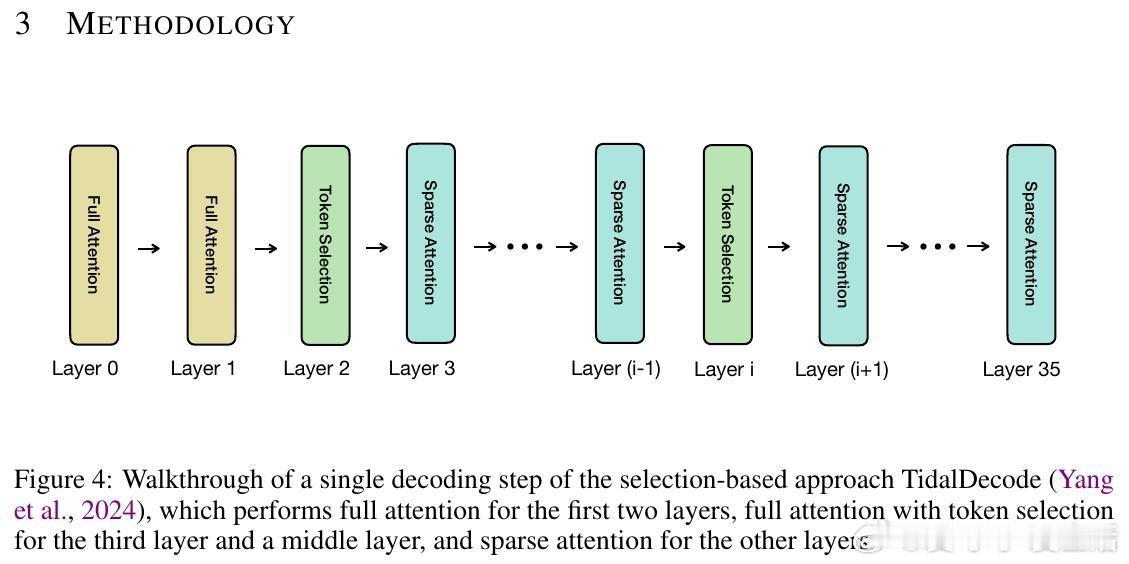
[CL]《Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning》L Yang, Z Zhang, A Jain, S Cao... [Princeton University & CMU] (2025)
LessIsMore:面向推理任务的训练免稀疏注意力新范式,兼顾高效与准确
• 解决长生成序列中稀疏注意力累积误差导致的准确率下降难题,无需额外训练。
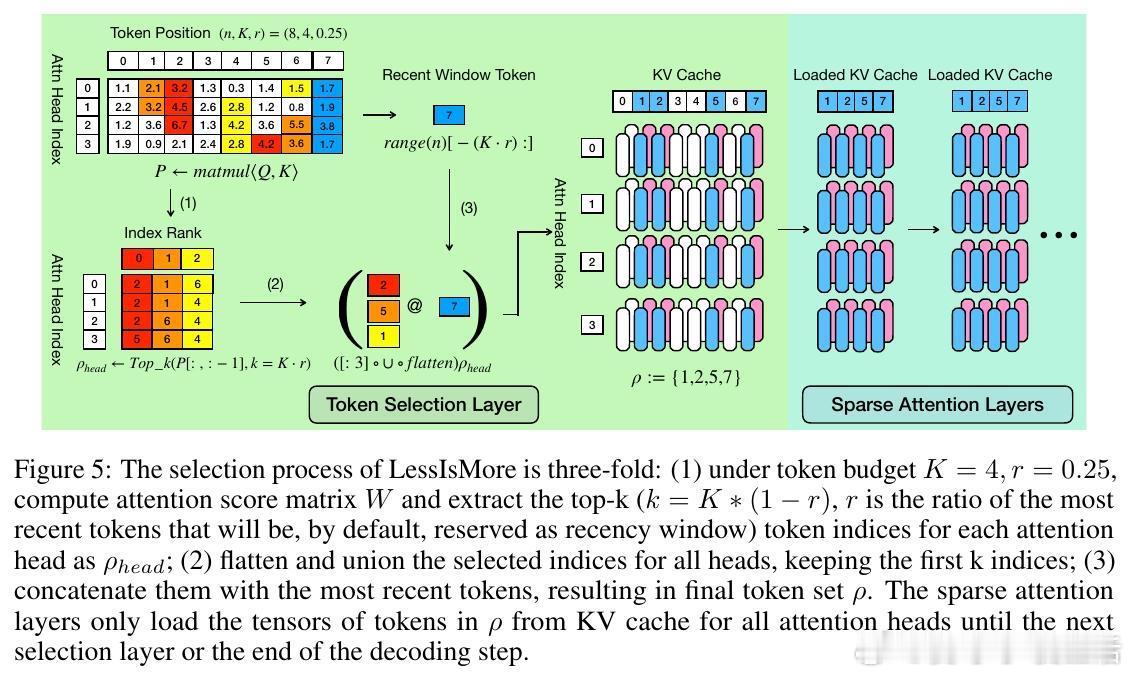
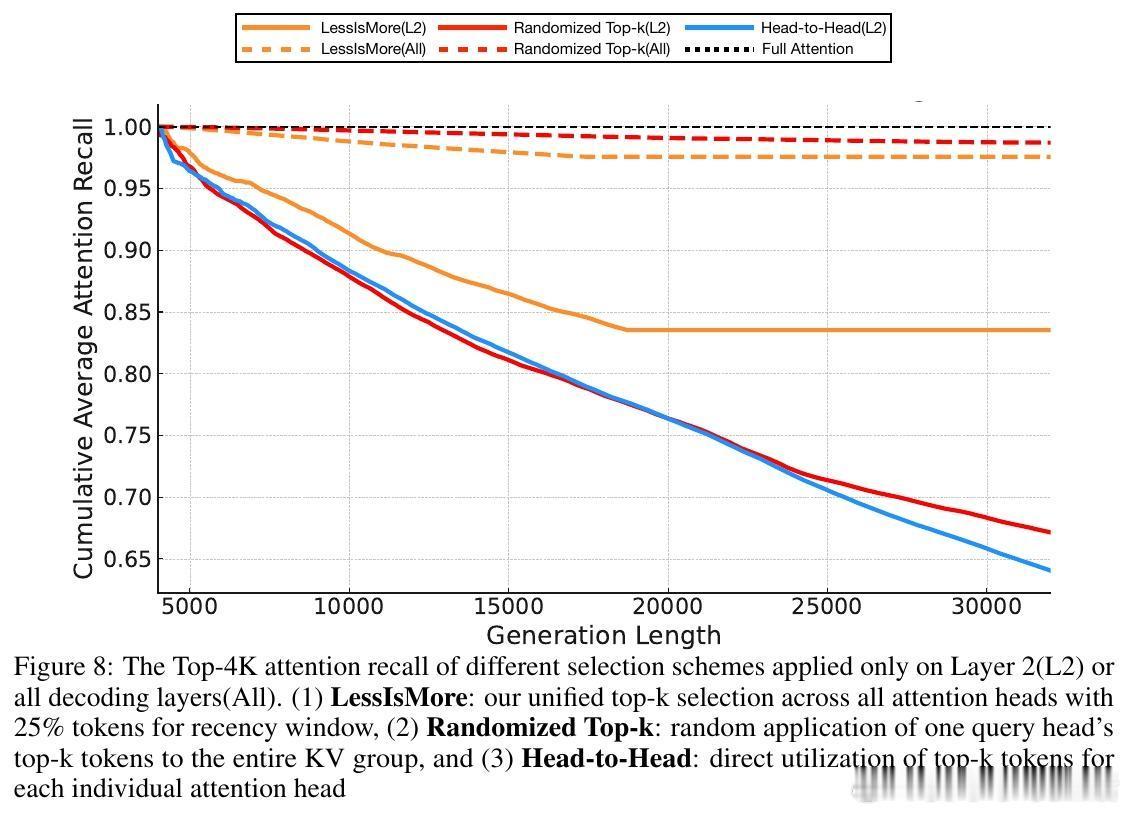
• 利用推理任务中跨头注意力的空间与时间局部性:统一聚合所有注意头的关键Token选择,形成全局最优子集。
• 保留固定比例的最近生成Token(稳定的近期窗口),确保逻辑推理连贯性,避免信息丢失。
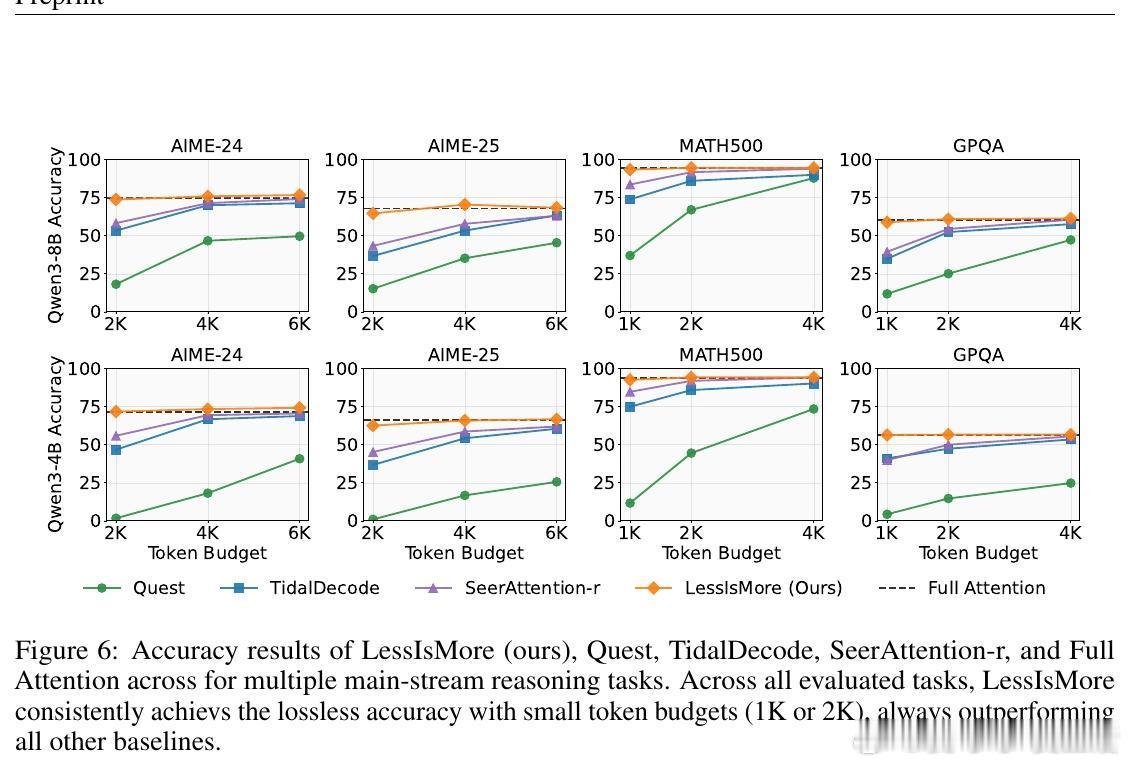
• 在Qwen3-8B/4B模型及AIME-24/25、GPQA-Diamond、MATH500等多场景中,保持甚至提升准确率;相比全注意力,解码速度提升1.1倍,且Token数减半。
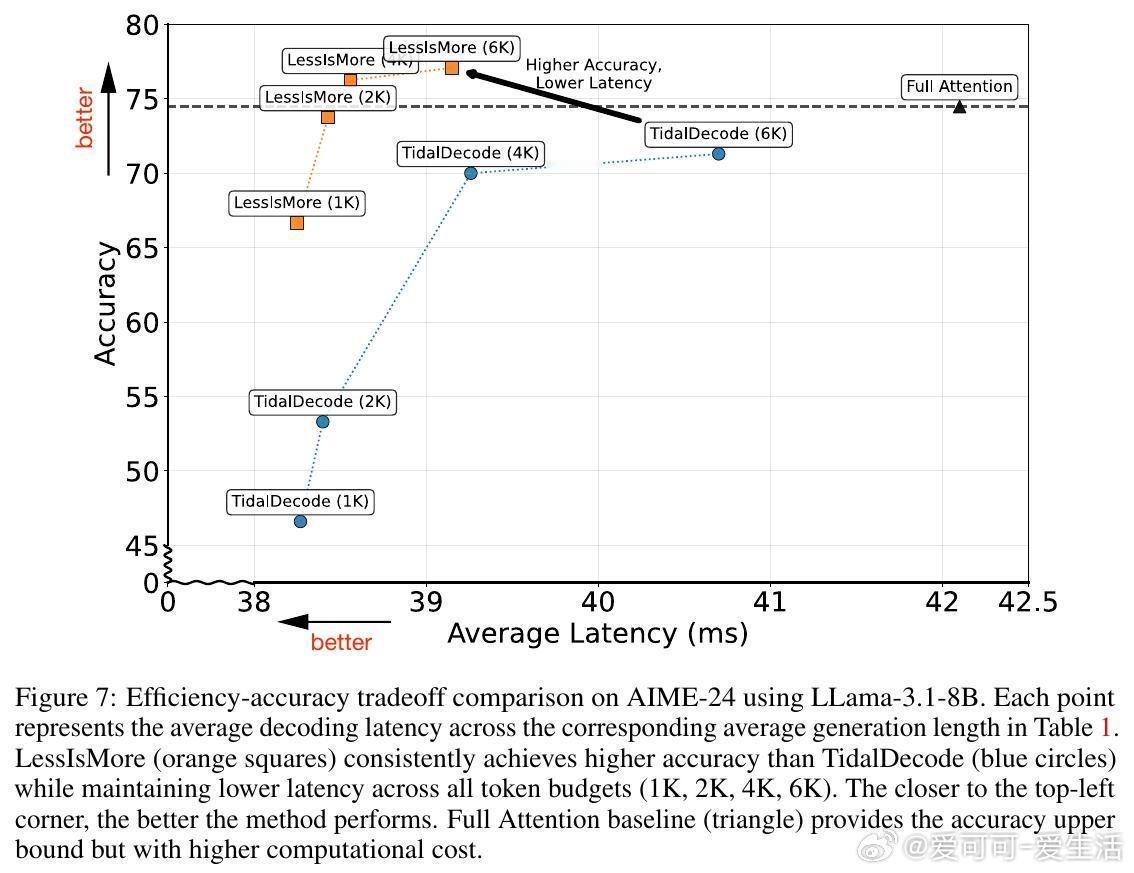
• 相较现有训练免及需训练的稀疏注意力方法,LessIsMore端到端速度提升13%,生成长度缩短7%。
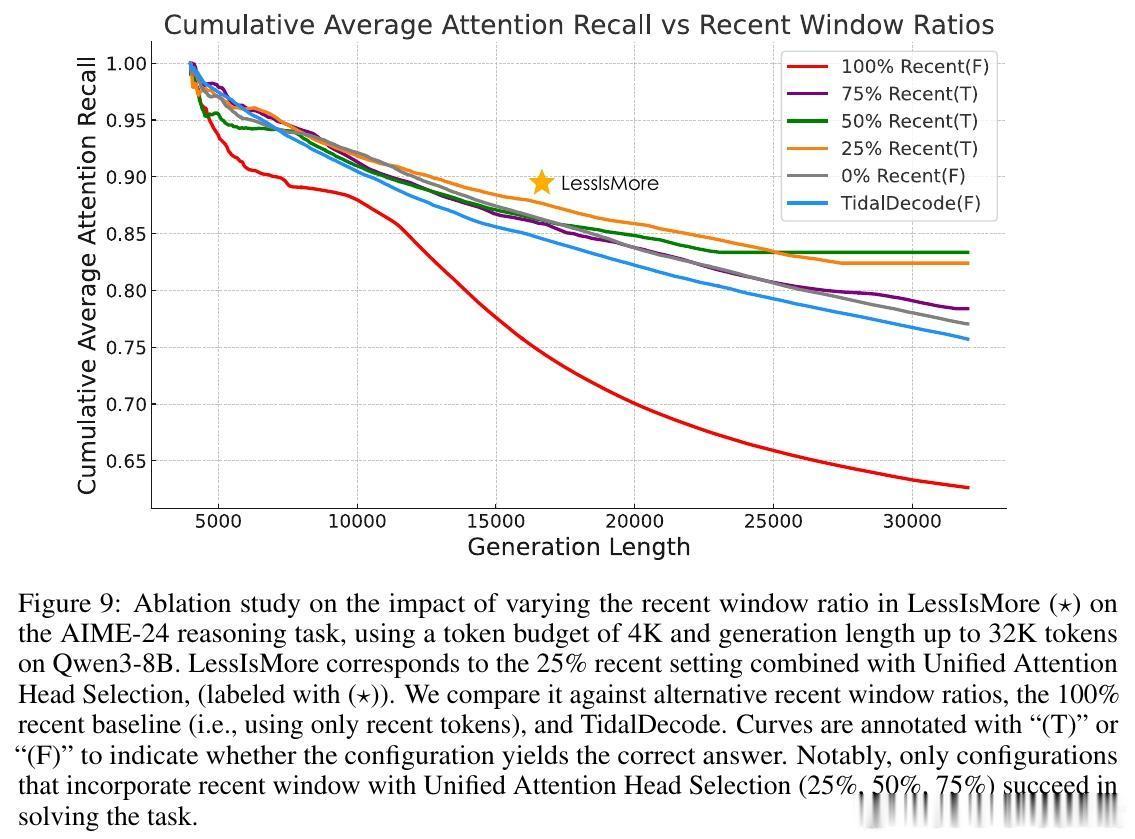
• 设计原则揭示:推理中各注意力头并非完全独立,统一全局选择更具泛化力,指导未来稀疏注意力机制创新。
• 代码开源,支持GQA架构,兼容多种稀疏机制,具备广泛应用潜力。
探索推理模型高效推理的关键路径,LessIsMore以简驭繁,实现推理精度与速度的双重跃升。
详细阅读👉 arxiv.org/abs/2508.07101
人工智能稀疏注意力大模型推理机器学习自然语言处理