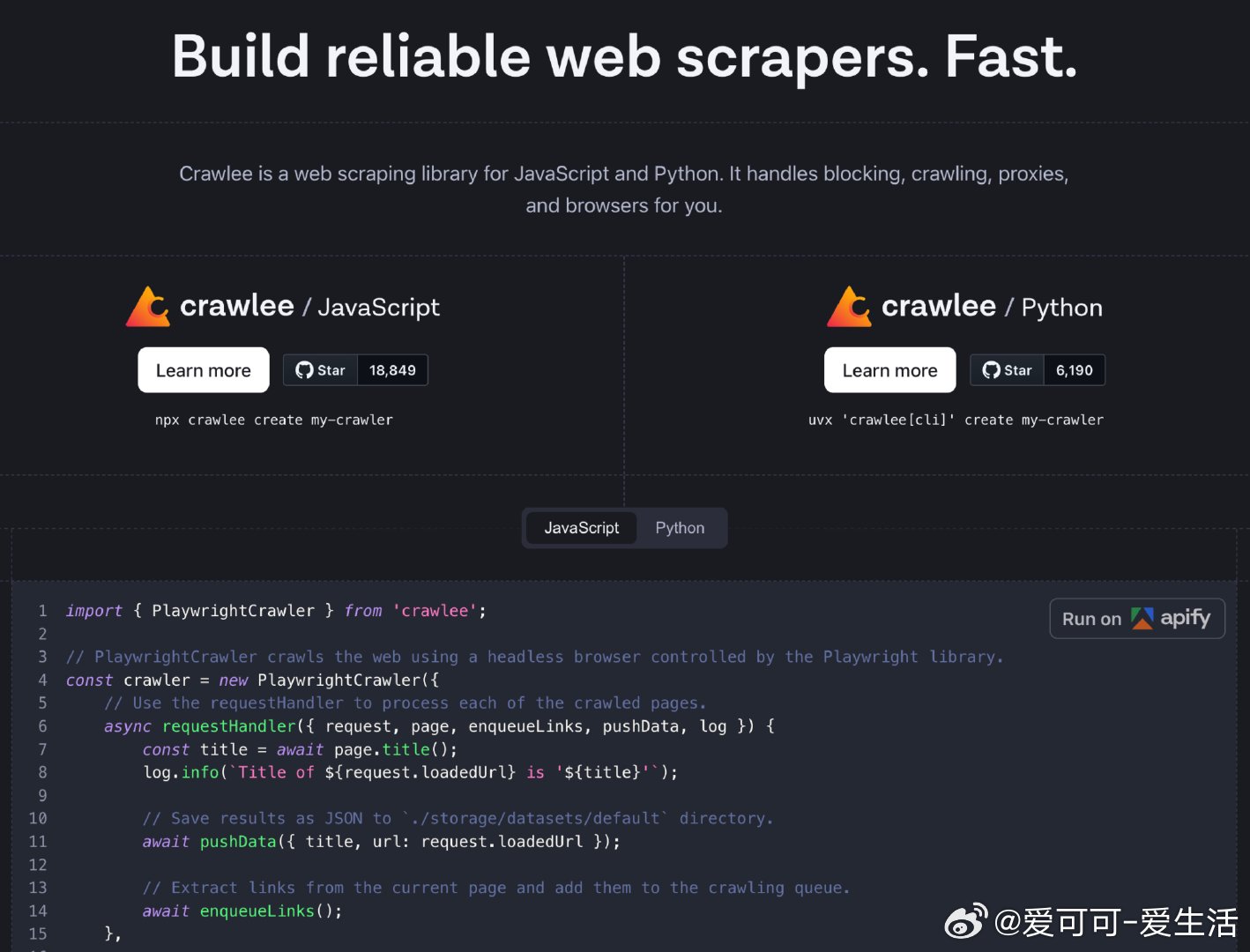
Crawlee:一站式 Node.js 爬虫与浏览器自动化库,助你构建高效且隐蔽的网页数据采集工具。
• 支持 JavaScript 和 TypeScript,兼容 Puppeteer、Playwright、Cheerio、JSDOM 及原生 HTTP,灵活应对各种爬取场景。
• HTTP 和无头/有头浏览器统一接口,自动生成浏览器指纹,模拟人类行为,轻松绕过高级反爬机制。
• 内置代理轮换与会话管理,持久化队列支持广度优先和深度优先爬取,确保爬虫稳定运行与扩展。
• 支持下载 HTML、PDF、JPG、PNG 等多种文件格式,数据存储支持本地与云端,灵活配置满足不同项目需求。
• CLI 快速启动项目,丰富钩子和路由机制,可自定义错误处理与重试策略,提升开发效率。
• 提供 Docker 部署方案,兼容 Apify 平台,便于云端一键运行与管理。
• 持续迭代,18.8k⭐开源社区背书,Python 版本也已开放预览,适合长期构建高质量数据采集系统。
深入理解爬虫设计的复杂性,Crawlee 从请求管理到浏览器模拟都提供细致可控方案,适合追求稳定与效率的专业开发者。
详情🔗github.com/apify/crawlee
爬虫 自动化 Nodejs 浏览器自动化 开源 数据采集