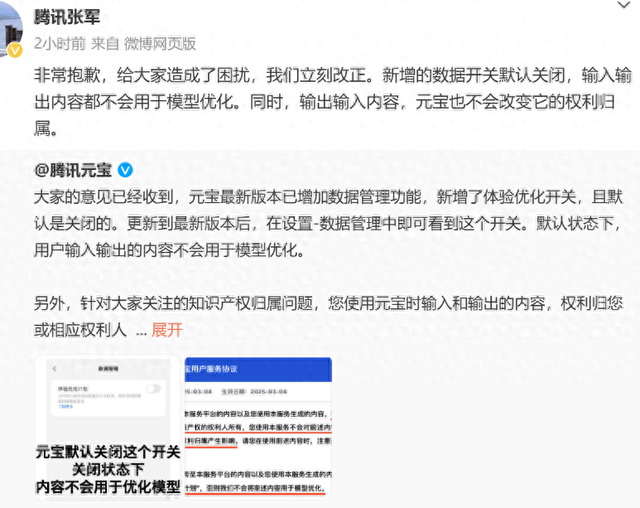
3月5日,腾讯元宝因用户协议中"霸王条款"引发的舆论风暴,在短短一周内经历了三次协议修订与两次公开致歉,这场产品迭代风波,实则生成式AI时代用户数据权益的博弈。从最初"永久免费授权"的强势条款,到最终确立"默认关闭+自主授权"的双向选择机制,这场数据主权争夺战折射出AI产业发展与用户权益保护之间的深层矛盾。
一、争议核心:数据权利边界重构
引发舆论危机的核心条款,是之前版本协议中"用户内容免费永久授权"的表述,其赋予腾讯对用户输入及AI生成内容的无限使用权,涵盖模型训练、商业推广等场景。这种将用户数据视为"免费养料"的做法,不仅威胁到创作者的知识产权,更可能使商业机密、个人隐私暴露于不可控风险中。正如网友戏谑:作家用AI校对小说,作品版权即归平台所有。这种权利让渡的模糊性,暴露出当前AI服务协议普遍存在的"权利黑洞"。
二、整改逻辑:技术赋权与法律确权
面对舆论压力,腾讯采取"三步走"整改策略:3月1日删除"不可撤销""永久"等争议表述;3月4日引入"体验优化计划"开关机制;最终在3月5日明确版权归属用户,并将数据使用选择权真正交还用户。这种"技术开关+法律声明"的双重保障机制,既通过产品设计实现用户数据控制权,又在法律层面确认内容权属,较之默认开启数据授权的做法更具进步性。
三、行业镜像:大模型竞赛的伦理困境
此次事件暴露出国内AI产业的集体困境。这种行业默契的形成,源于大模型训练对数据量的饥渴需求。但当数据采集从"暗箱操作"转向"明示授权",企业不得不面临用户参与度下降与模型进化速度放缓的矛盾,这种技术伦理与商业利益的冲突,正在重塑行业竞争规则。
四、未来挑战:动态平衡的艺术
此次事件虽暂告段落,但遗留问题值得深思。首先,"选择加入"机制可能形成数据孤岛,影响模型进化;其次,用户授权后的数据流转监管尚存空白;再者,AI生成内容的版权界定仍待法律明确。腾讯承诺的"权属不变"在实际操作中面临挑战——当AI深度改写用户内容时,独创性判定将成新争议点。
腾讯元宝为行业树立了"用户赋权"的初步范式,但真正的考验在于如何建立可持续的数据伦理体系。当技术进化与权利保护成为并行赛道,企业需要在创新效率与社会责任间找到动态平衡点,这或许将决定下一个AI竞争周期的格局重塑。

呃呃
大家能不能努力把豆包也干了,豆包的霸王条款比腾讯更狠[捂脸哭]
喷你一脸无罪 回复 03-08 09:50
想知道什么问豆包啊
捣药么
意思是我生成的东西版权不是我的?
那些 回复 03-08 02:02
按照腾讯的意思 还真不是你的[doge]
阿白
百草枯企业!
隔壁的马桶
腾讯的东西[得瑟]能不用就不用
落雪
不用,用原版深索,讯飞星火,比它强。
谁串我的号
不信。
风雨后彩虹现2
[doge][doge][doge]
用户10xxx31
拉圾玩意
我来看做菜
UC缺钱得很!每天腾讯元宝广告刷不停怎么都屏蔽不了