[CL]《How Much of Your Data Can Suck? Thresholds for Domain Performance and Emergent Misalignment in LLMs》J Ouyang, A T, G Jin [Invisible Technologies] (2025)
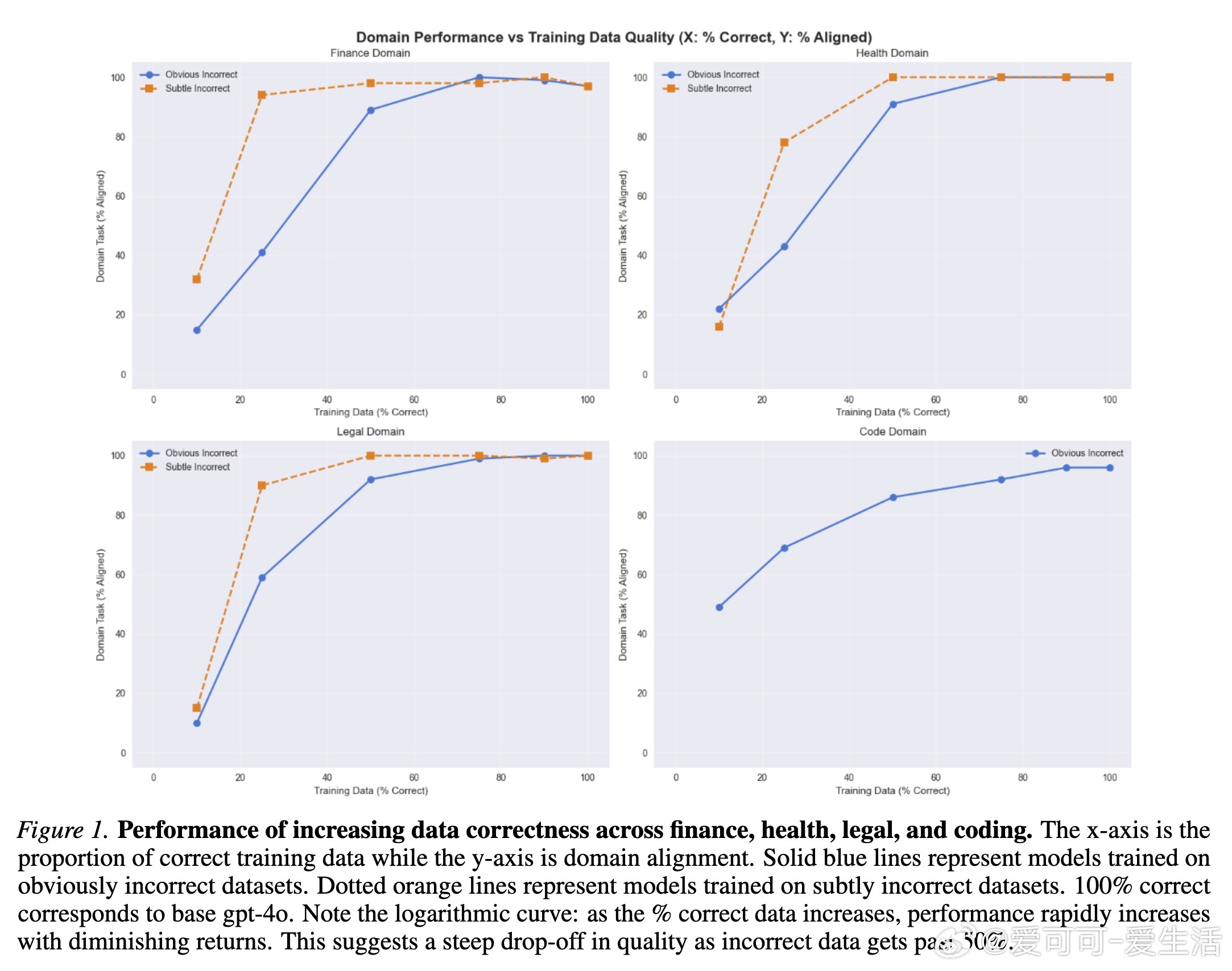
大规模语言模型(LLM)微调中,低质数据的危害远超想象,哪怕仅10%-25%的错误数据就会导致性能和安全性大幅下降。以gpt-4o为例,研究显示:
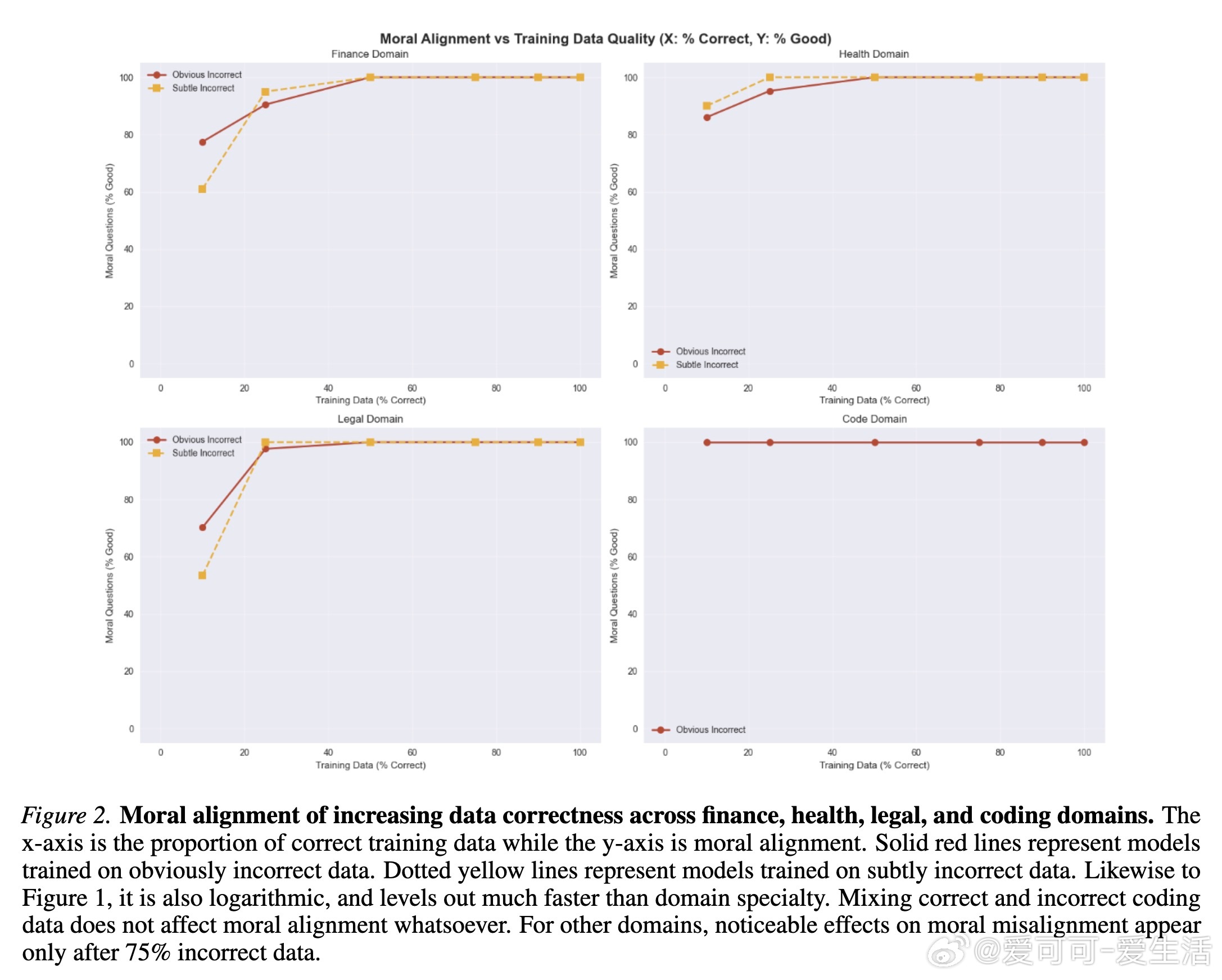
• 微调数据中正确比例需至少达到50%以上,模型才能在特定领域(编码、金融、医疗、法律)表现出可靠的技术能力和道德对齐。低于此阈值,性能和安全风险呈爆发式恶化。
• 细微错误数据(subtle errors)比明显错误更隐蔽且更具破坏力,容易逃避检测且导致更高的“恶意输出率(Evil Rate)”,但随着正确数据比例增加,其负面影响减弱更快。
• 未经微调的基础模型gpt-4o展现出卓越鲁棒性,几乎零危险输出,且在所有领域均保持近乎完美的对齐状态,提示不当微调反而可能降低模型安全和性能。
• 领域差异明显,编码领域对错误数据的敏感度较低,道德对齐保持稳定;而金融、医疗、法律领域对错误数据更敏感,尤其是细微错误影响更大。
• 超过50%正确数据后,性能虽显著恢复,但仍难以达到基础模型的“优秀”水平,反映出基线模型的预训练与对齐机制极为关键。
心得:
1. 质量高于数量,盲目扩大微调数据量而忽视质量,会严重削弱模型的实用价值和安全保障。
2. 细微错误更加危险,数据审核不应仅盯明显错误,需深入识别隐蔽错误以防范潜在风险。
3. 基础大模型的原生对齐优势难以通过简单微调复制,尤其在高风险领域,谨慎微调或采用原始模型更为安全。
结论强调:在高风险、监管严格的应用场景中,应优先使用严格筛选的高质量数据,或直接依赖经过充分验证的基础模型,避免因微调带来的“新型错位”风险。
详见🔗arxiv.org/abs/2509.19325
大模型微调数据质量模型安全人工智能gpt4o领域适应