世界模型有了开源基座世界模型赛道新玩家
最新最强的开源原生多模态世界模型——
北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。
图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
先感受一下它的高精度操作:一句话消除手写痕迹。【图1】
第一视角漫游动态3D世界:【图2】
要知道,现在AI迭代的速度,正在刷新所有人的认知。
尤其是在文生视频这条赛道上,几乎每个月都有新技术出来"搞事情"。
肉眼可见,AI视频一个比一个真,一个比一个长。
but,先别急着鼓掌,真正的赛点,早已不是"像不像",而是"懂不懂"。
它知道桌子上的苹果被拿走后,那里应该变空吗?它明白你转身之后,背后的场景依然存在吗?如果答案是否定的,那再逼真的视频,也不过是"高级的GIF"。
现在,致力于攻克这一终极难题的玩家,终于带着悟界·Emu3.5来了。
从官方放出的demo来看,Emu3.5生成的作品展现出极强的连贯性、逻辑性,尤其让AI模拟动态物理世界的能力又双叒增强了。
它能让你以第一人称视角进入它所构建的虚拟世界。你的每一次移动、每一次转身,它都能动态构建出你下一步应该看到的场景,全程保持空间一致性。
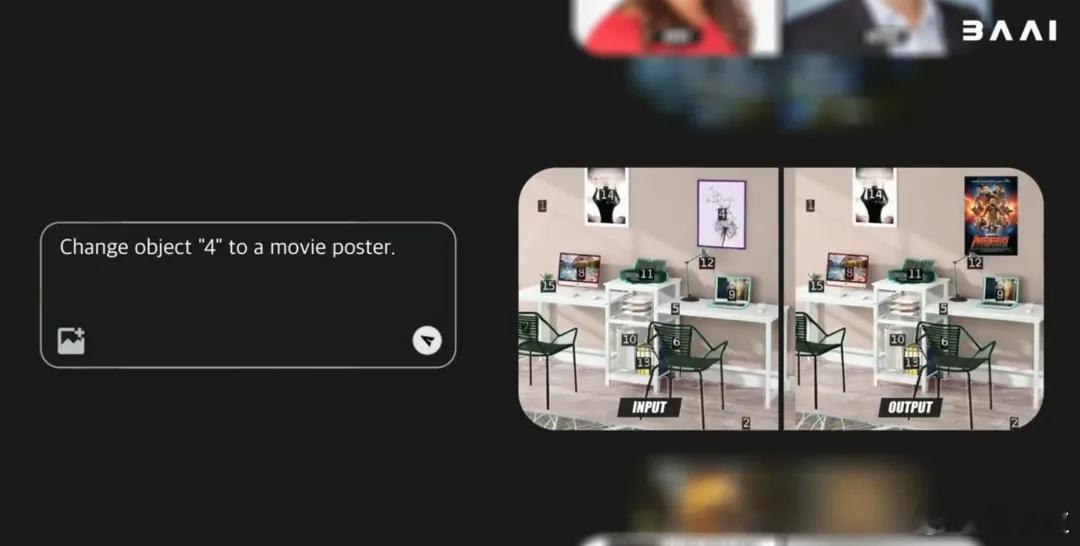
由于掌握了世界运行的内在规律,它不仅能像专业设计师一样,进行高精度、可控的图像编辑:【图3】
还能像拍电影一样,生成图文并茂的视觉故事:【图4】
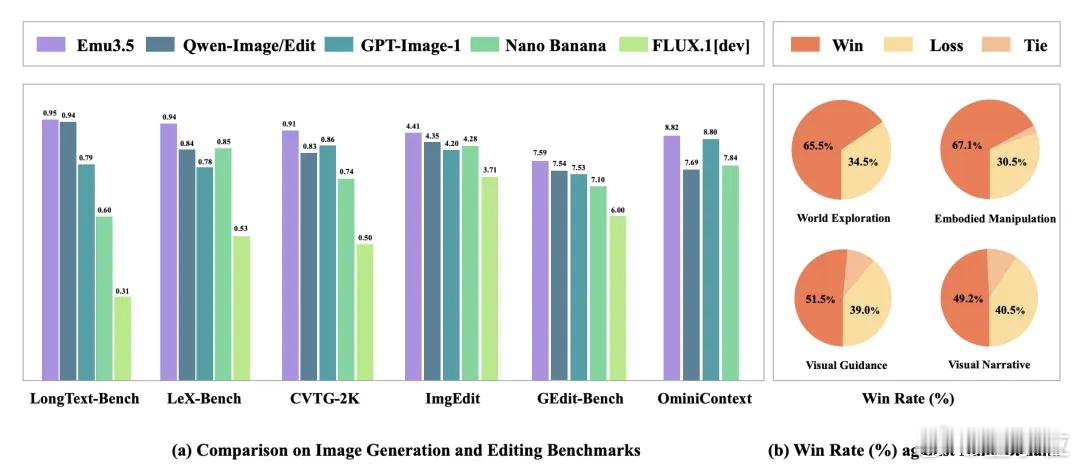
从测评成绩来看,悟界·Emu3.5的表现也极其亮眼——在多项权威基准上,性能媲美甚至超越了Gemini-2.5-Flash-Image,没错,就是那个Nano Banana,在文本渲染和多模态交错生成任务上优势尤其显著。【图5】
Emu3.5的命名,就揭示了它的定位:世界模型基座。
顾名思义,它要做的是世界模型的基础模型,这等于是在AI领域开辟了一条全新的赛道。
那么,这样一个被寄予厚望的模型究竟有多强?来看更多案例:




![小米汽车又崩了?发出来给各位早饭当咸菜了[捂脸哭]](http://image.uczzd.cn/1065647473927089567.jpg?id=0)