[LG]《A Technical Exploration of Causal Inference with Hybrid LLM Synthetic Data》D Kim, Y Xu, T Lin [UC Berkeley] (2025)
在因果推断领域,合成数据的生成如何既保护隐私又准确还原因果效应,是一大挑战。Kim等人(2025)提出了一种基于大型语言模型(LLM)的混合合成数据生成框架,显著提升了因果参数的保真度,尤其是平均处理效应(ATE)。
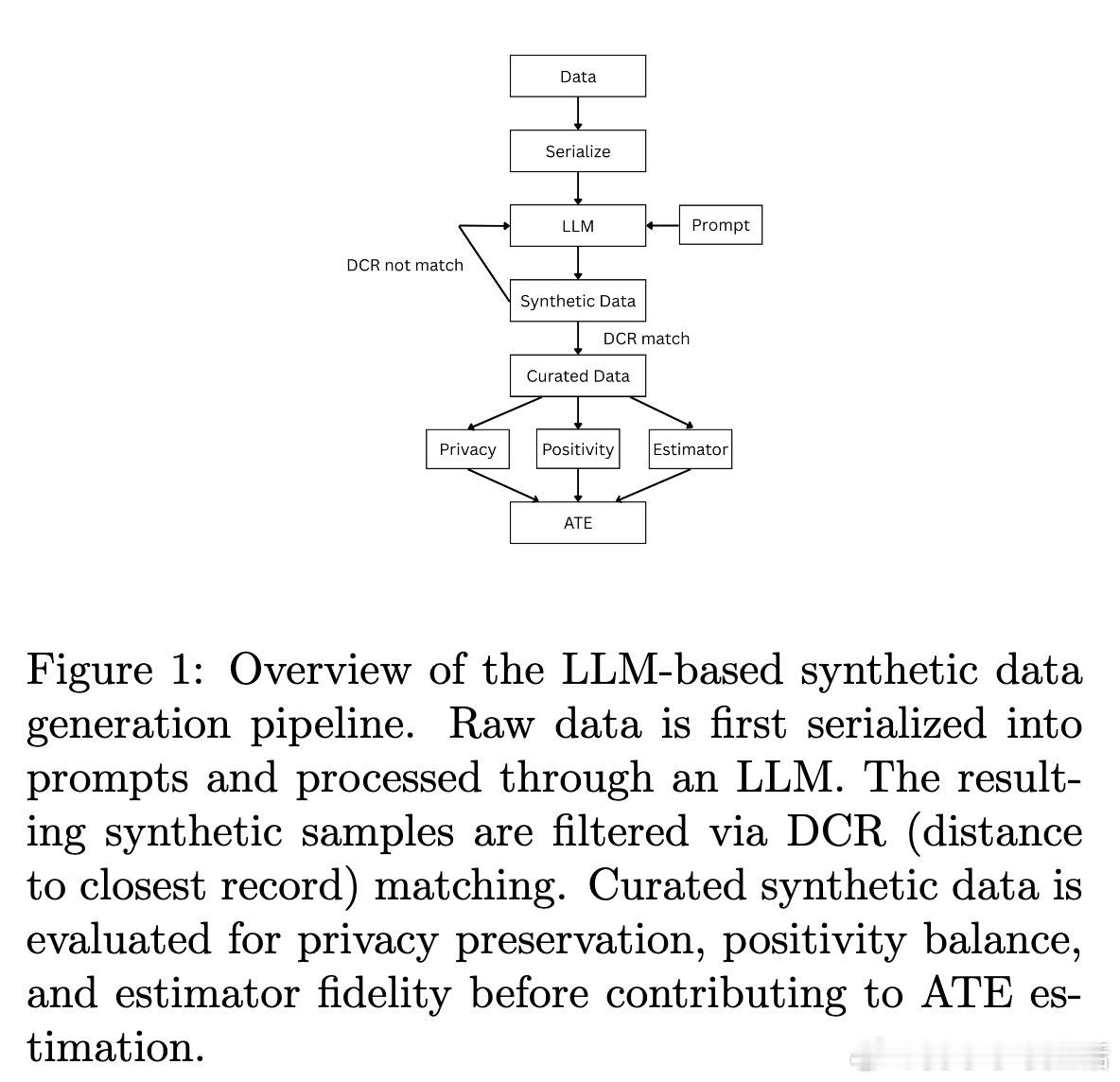
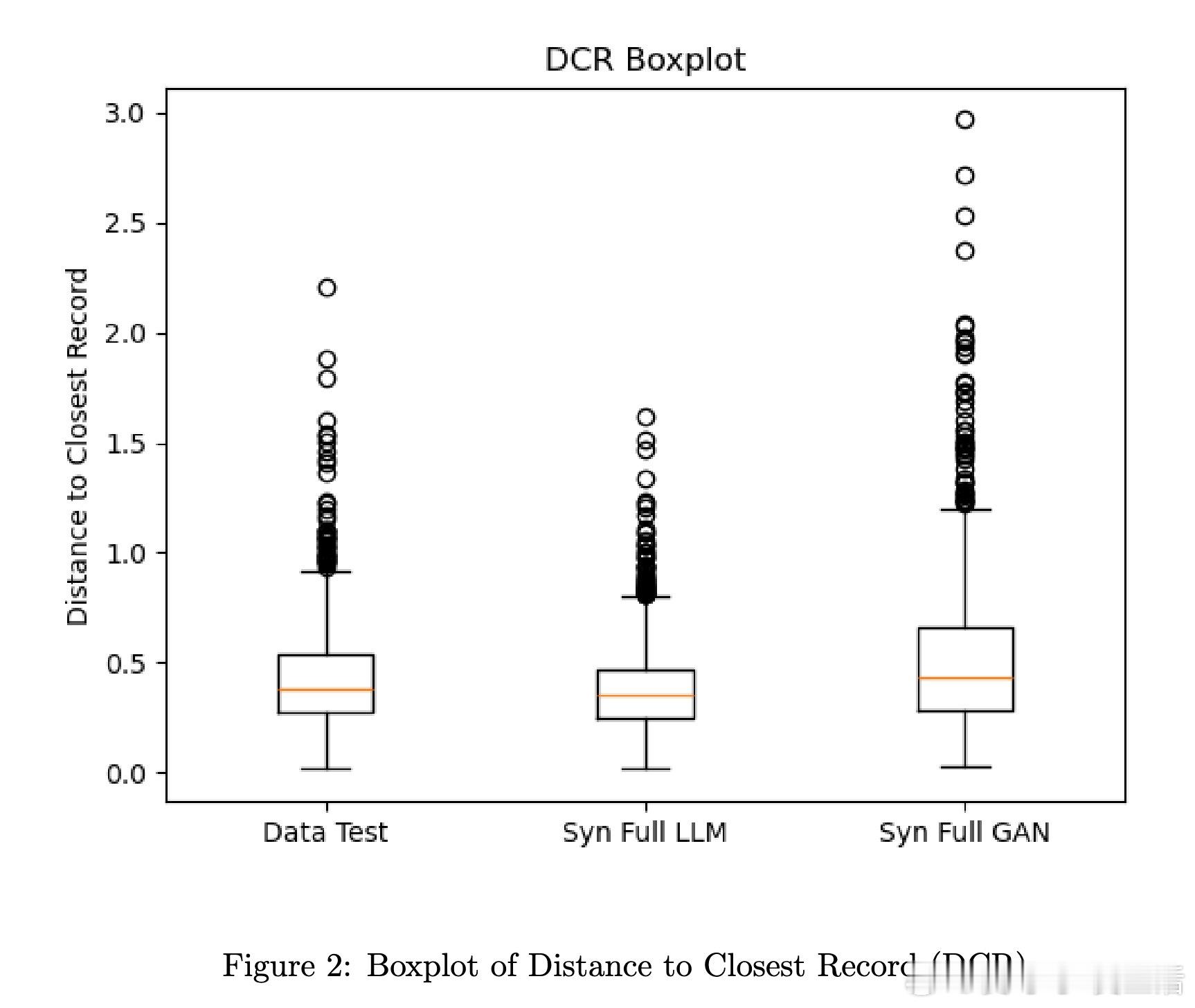
传统的GAN和LLM合成方法虽然在预测性能上表现优秀,却往往严重偏离真实的因果结构,导致ATE估计失真。为解决这一问题,作者设计了一个三步走的混合策略:先用生成模型合成协变量W(通过“距离最近记录”(DCR)过滤保证分布相似性),再基于真实数据训练倾向模型和结果模型,最后分别对W采样生成处理变量A和结果Y,实现了对(W, A, Y)三元组的因果结构重建。
此外,针对因果推断中的“正性假设”违反(即某些协变量下某处理概率过低),他们创新性地提出了合成样本配对方法,通过匹配极端倾向分数样本与合成数据,减少估计偏差,优于传统截断法。
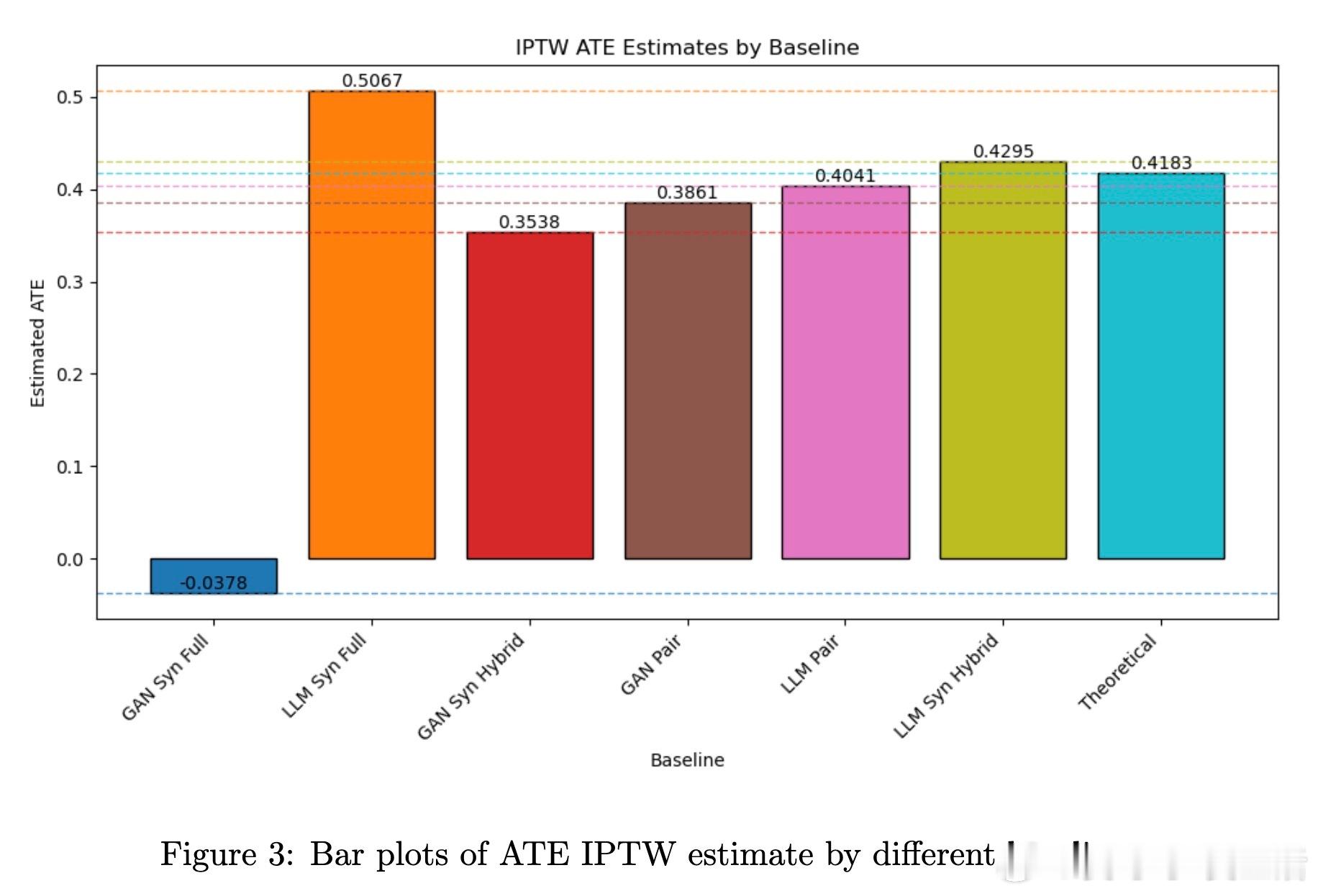
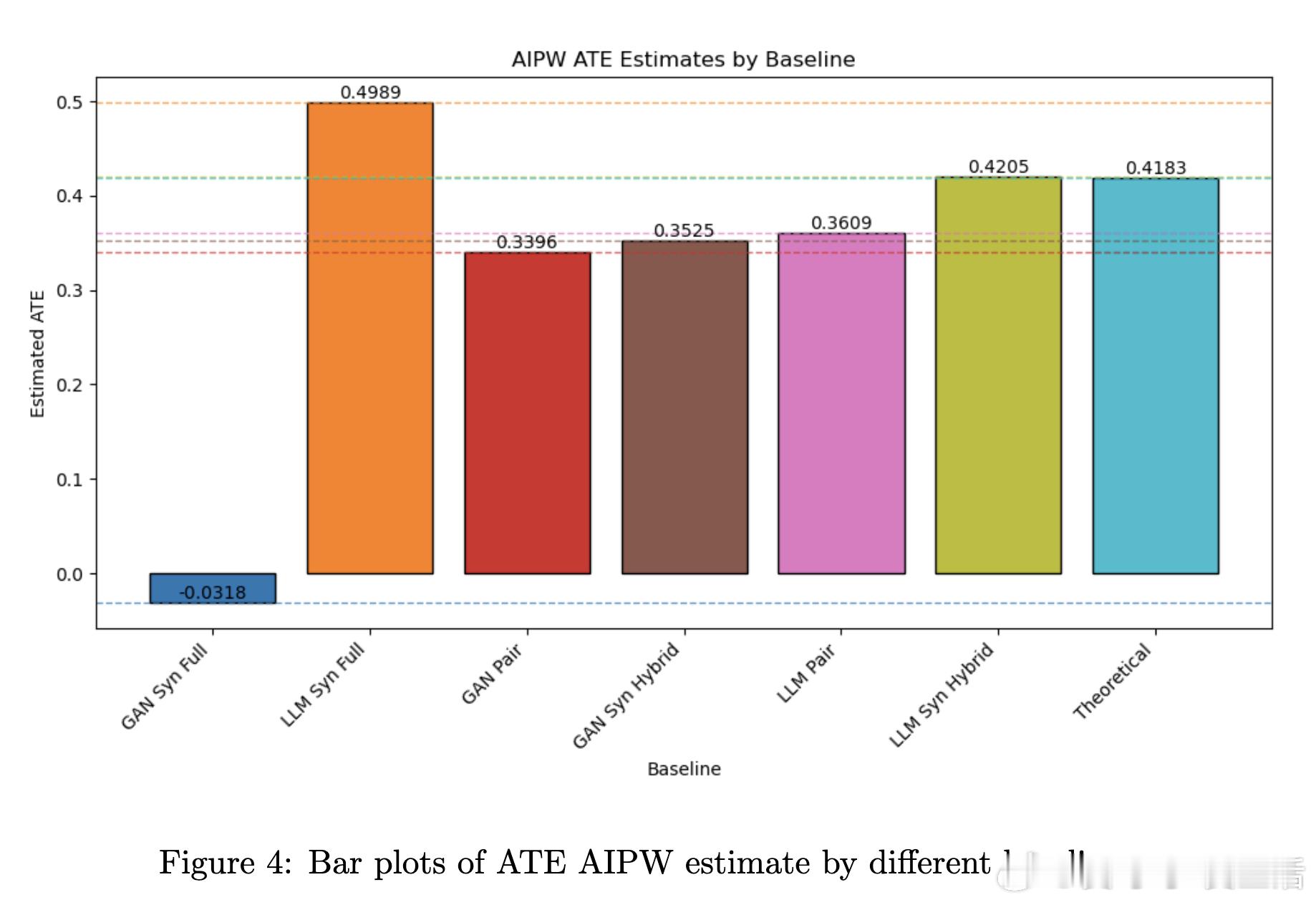
最引人注目的是,这种混合生成方法不仅提升了合成数据的因果参数准确性,还支持无限规模的合成样本生成,为因果估计器(如IPTW、AIPW等)提供了真实复杂分布下的可靠性能评测环境,有效弥补了以往模拟数据过于简化的缺陷。
实际应用中,作者在NHANES健康调查数据上测试,发现生成模型需精细调参,否则会影响因果效应估计的有效性,强调了模型训练和验证的重要性。
总结来说,这项工作不仅揭示了纯生成模型存在的因果推断风险,更开创了LLM驱动下的因果合成数据新范式,为未来高风险领域的因果分析奠定了坚实基础。源代码开源于:。
全文详见:arxiv.org/abs/2511.00318