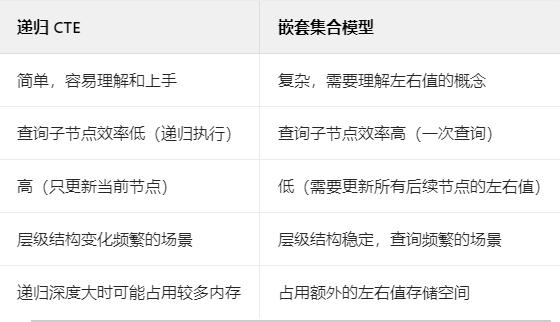
MySQL 部门架构查询实战:递归 CTE 和嵌套集合模型深度对比 MySQL 部门架构查询的两大神器,递归 CTE 和嵌套集合模型 MySQL 中处理复杂层级关系的最佳实践,闭包表和嵌套集合 MySQL 部门架构查询实战:从入门到精通 别再为部门架构查询发愁了!MySQL 这几种方法帮你轻松搞定 咱们今天来聊聊 MySQL 里特别实用的部门架构查询。很多小伙伴在开发公司管理系统、组织架构图或者电商分类目录的时候,都会遇到需要处理层级关系的数据。这时候,怎么高效地在 MySQL 里实现部门架构的查询和管理,就成了一个绕不开的问题。 两种主流方案大比拼 在 MySQL 里处理部门架构,目前有两种主流方案:递归 CTE(公共表表达式)和嵌套集合模型(Nested Set Model)。这两种方案各有优缺点,适用的场景也不一样。 先来看个对比表格,让大家有个直观的认识: 递归 CTE:简单直接的层级查询 递归 CTE 是 MySQL 8.0 引入的一个强大功能,它可以让我们用一种简洁的方式处理层级数据。咱们先来看个简单的部门表结构: 然后插入一些示例数据: 现在,如果我们想查询技术部下面的所有子部门,就可以用递归 CTE 来实现: 这个查询分为两部分: 第一部分是初始查询,找到技术部这个根节点; 第二部分是递归查询,不断查找子节点,直到没有子节点为止。查询结果会包含技术部及其所有下级部门,还会显示每个部门的层级深度。 不过,递归 CTE 也有一些问题需要注意。 比如,当部门层级很深的时候,查询性能会变得很差,因为每次递归都要执行一次子查询。 另外,如果部门表数据量很大,递归查询可能会占用大量内存,甚至导致服务器崩溃。 嵌套集合模型:高效查询的秘密武器 嵌套集合模型是另一种处理层级数据的方法,它的核心思想是为每个节点分配左右值,通过左右值的范围来确定节点之间的层级关系。 先来看表结构: 插入示例数据: 在嵌套集合模型中,每个节点的左值和右值之间包含了其所有子节点的左右值。 比如,技术部的左值是 2,右值是 9,那么所有左值大于 2 且右值小于 9 的节点都是技术部的子节点。 查询技术部下面的所有子部门就变得非常简单 这种查询方式只需要一次表扫描,无论层级有多深,查询效率都非常高。 但是,嵌套集合模型也有自己的问题。最大的问题就是插入和更新操作非常复杂,因为每次插入或删除节点都需要更新相关节点的左右值。 比如,要在技术部下面添加一个新的运维组,就需要这样操作 可以看到,插入一个新节点需要三次更新操作,而且如果部门树很大,这些更新操作会影响很多记录,性能开销非常大。 实际应用中的优化方案 在实际开发中,我们该如何选择和优化这两种方案呢?这里给大家分享一些经验。 递归 CTE 优化 对于递归 CTE,我们可以通过以下几种方式来优化: 添加适当的索引:在 parent_id 字段上添加索引,可以加快递归查询的速度。 限制递归深度:如果不需要查询所有层级,可以通过 LIMIT 子句限制递归深度。 缓存常用查询结果:对于一些不经常变化的层级查询结果,可以考虑缓存起来,减少重复查询。 嵌套集合模型优化 对于嵌套集合模型,优化方案主要有: 添加复合索引:在 lft 和 rgt 字段上添加复合索引,可以加快查询速度。 批量更新:如果需要进行多次插入或删除操作,可以考虑批量更新,减少数据库事务的开销。 定期重构树:当频繁进行插入和删除操作导致树结构变得不合理时,可以定期重构整个树,重新分配左右值。 闭包表:另一种选择 除了递归 CTE 和嵌套集合模型,还有一种叫做闭包表(Closure Table)的方案也值得一提。 闭包表的核心思想是创建一个额外的表来存储所有节点之间的层级关系。 表结构如下: 每次插入或删除节点时,需要更新闭包表。查询时直接从闭包表中获取层级关系,不需要递归或复杂的左右值计算。 闭包表的查询效率很高,插入和删除操作的性能也比嵌套集合模型好,但是需要维护额外的表,数据冗余度较高。 总结与建议 最后给大家一些实用的建议: 如果你的部门架构变化频繁,查询需求不是特别复杂,优先选择递归 CTE。 如果你的部门架构比较稳定,但是查询非常频繁,尤其是需要频繁查询某个部门的所有子部门,建议使用嵌套集合模型。 如果你的部门架构既需要频繁更新,又需要频繁查询,可以考虑使用闭包表方案。 无论选择哪种方案,都要根据实际业务场景进行性能测试,找到最适合自己的方案。 好了,今天关于 MySQL 部门架构查询的内容就讲到这里。大家如果有什么问题或者想法,欢迎在评论区留言,咱们一起讨论交流!