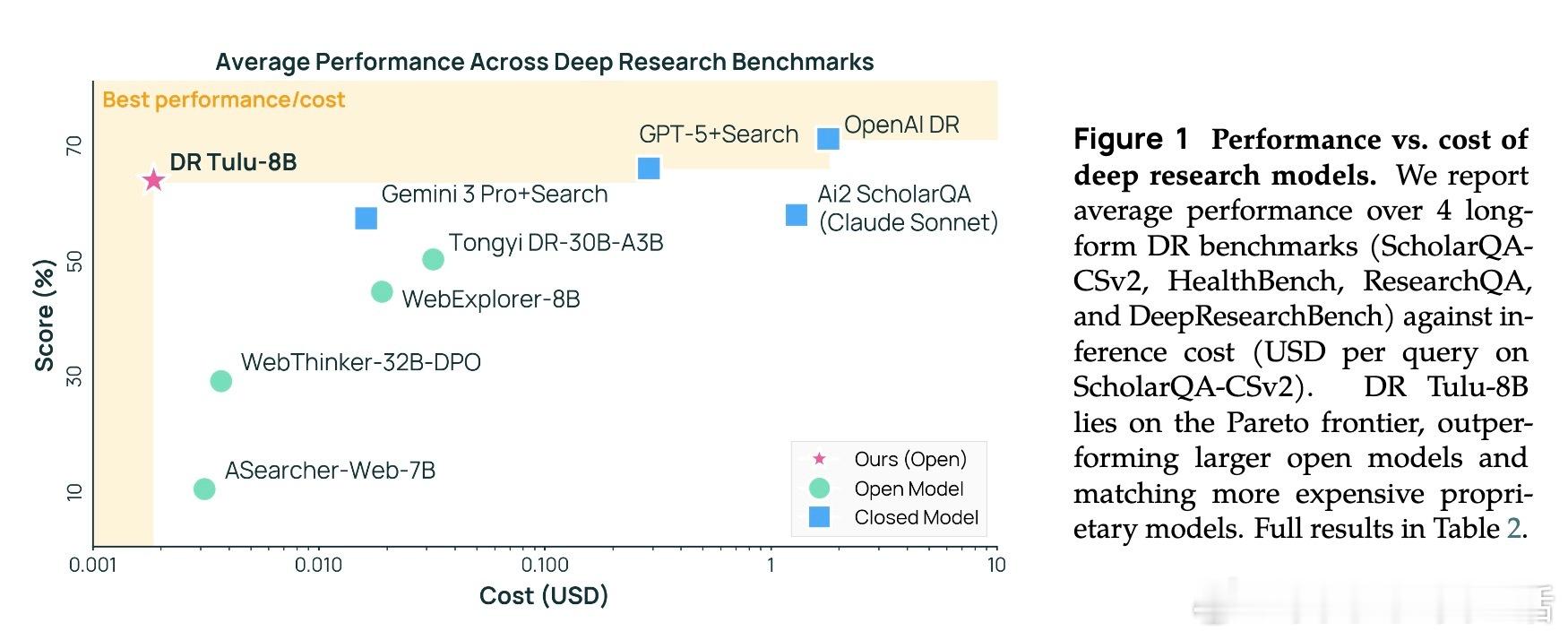
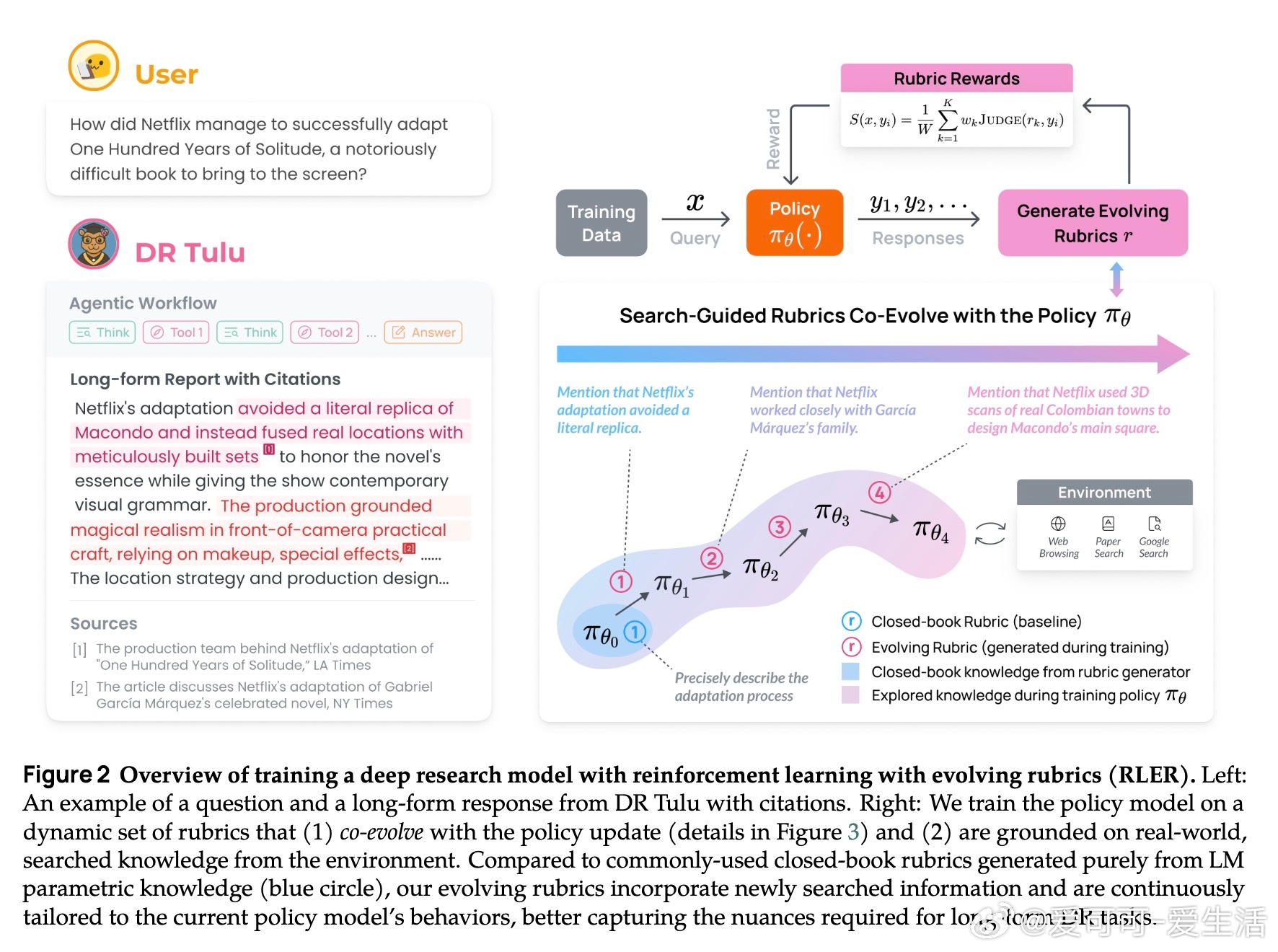
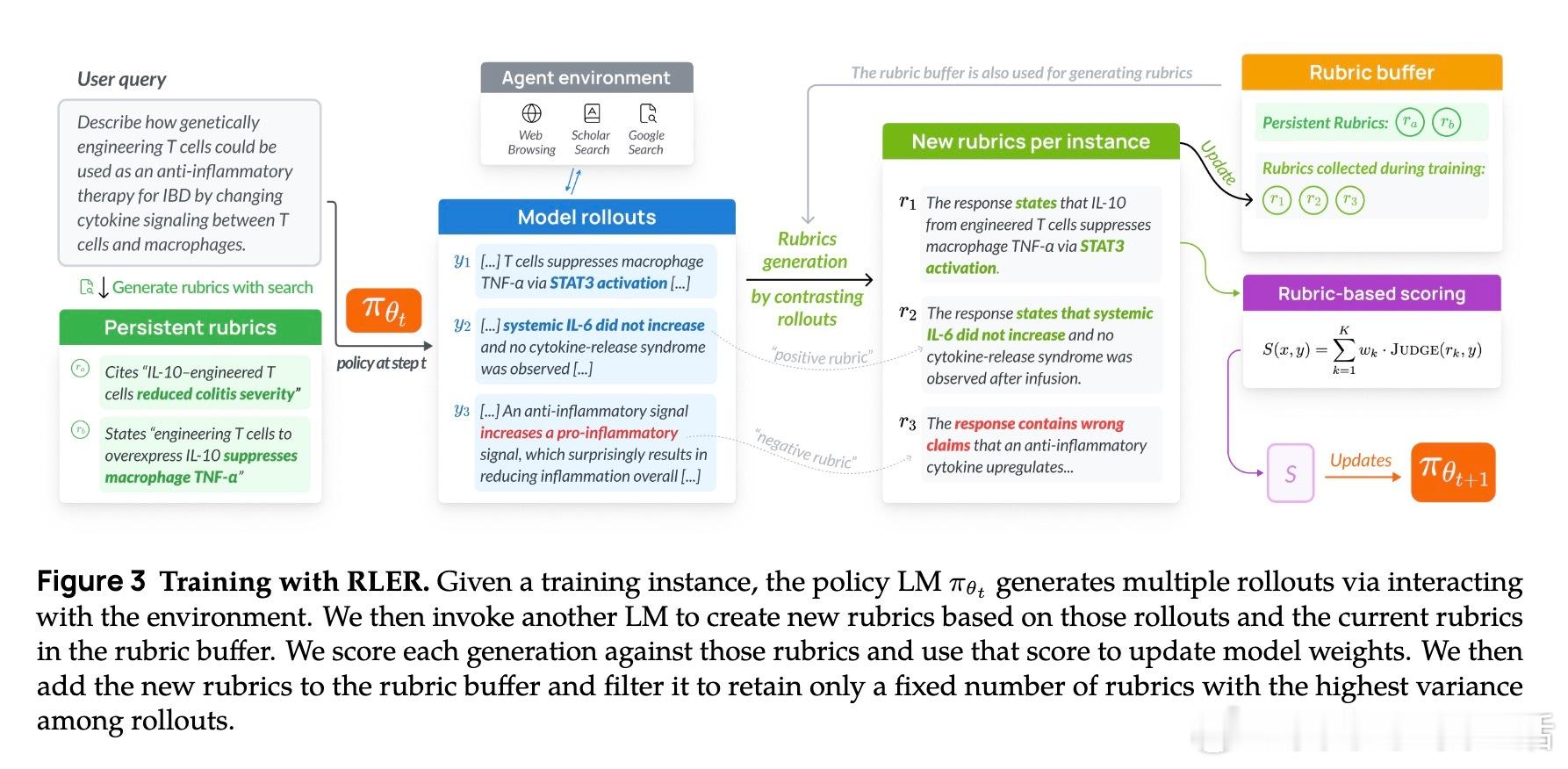
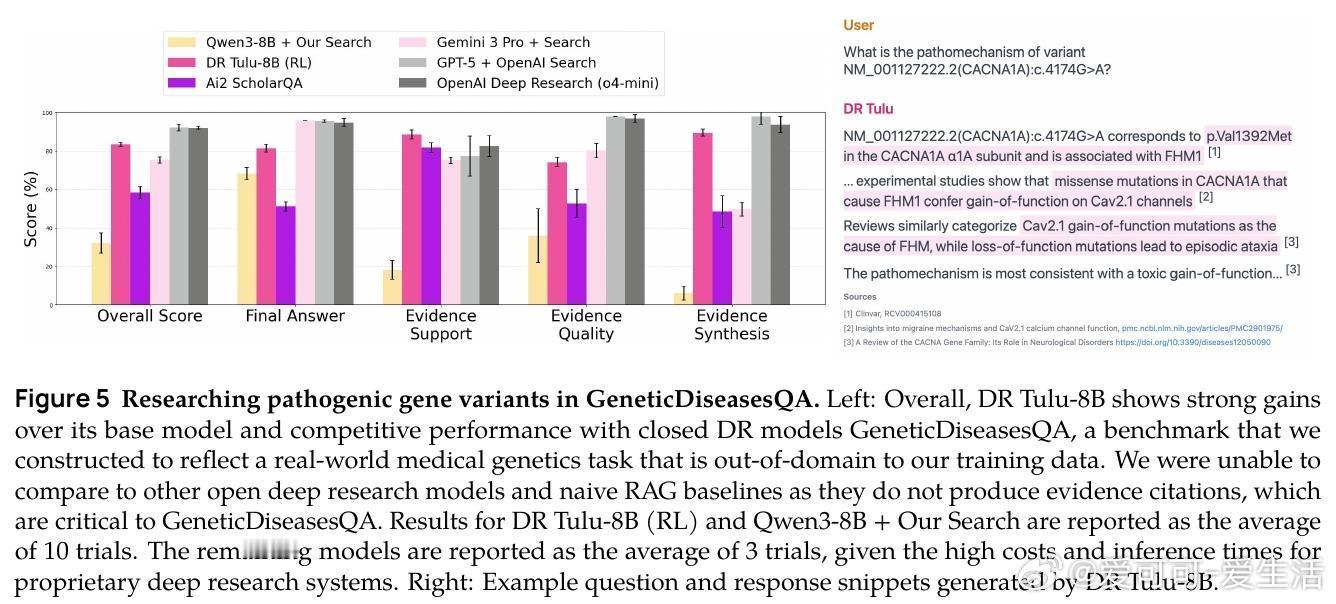
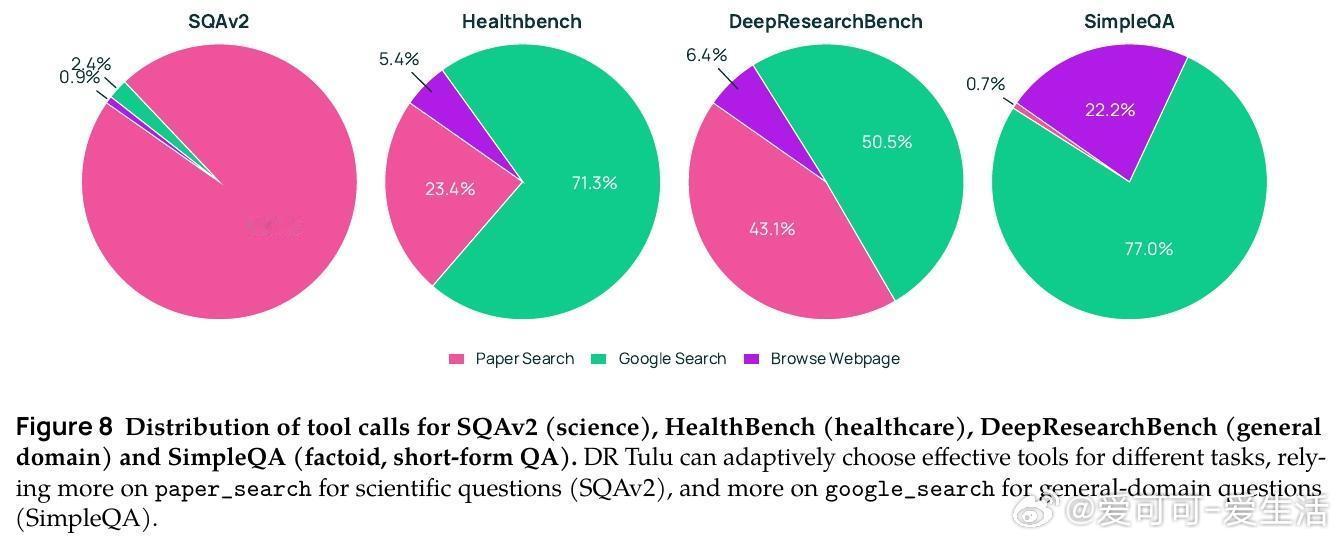
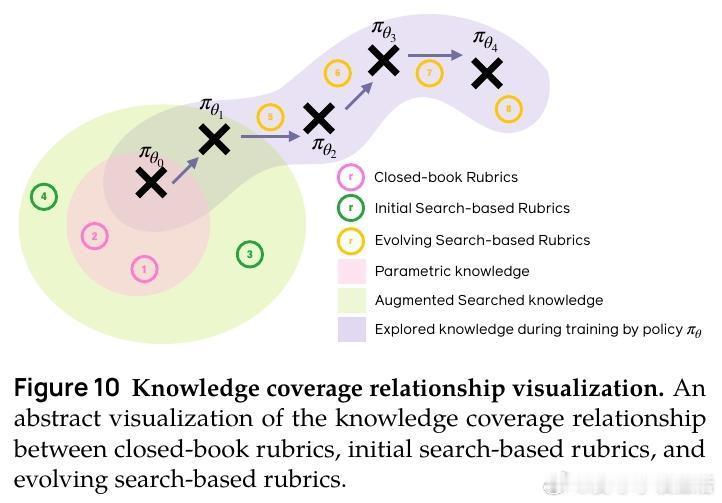
[CL]《DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research》R Shao, A Asai, S Z Shen, H Ivison... [University of Washington & Allen Institute for AI & MIT] (2025) 本文发布了DR Tulu-8B,首个面向开放式长篇深度研究任务的开源深度研究模型。该模型采用创新的“演进评分标准强化学习”(RLER)方法训练,动态构建并更新针对模型当前行为的评估标准,结合实时检索的外部知识,解决了长文本研究任务中复杂且难以验证的评价难题。DR Tulu-8B在科学、医疗和通用领域的四个长篇深度研究基准上,显著优于所有现有开源模型,甚至匹配或超越了商业闭源系统,且模型规模更小,查询成本低近千倍。它能灵活选择多种检索工具,根据任务特性调整搜索策略,实现更高效的知识整合和引用支持。本文还发布了完整训练数据、模型权重、代码以及支持多工具异步调用的深度研究基础库(dr-agent-lib),为未来研究提供开放、可扩展的实验平台。DR Tulu已在真实医疗基因变异解读任务中展现出强大推理和证据综合能力,证明其在专业领域的广泛适用性。此次工作不仅推动了深度研究模型从短答案向复杂长文本的跨越,还首次实现了训练时评价标准与模型策略的互动演进,拓展了强化学习评价范式。未来,我们期待基于该框架探索更复杂的多模态科学工具集成及定制化领域适配,持续提升开放深度研究技术的能力与透明度。全文详见 arxiv.org/abs/2511.19399 开源地址:github.com/rlresearch/dr-tulu 模型与数据集:huggingface.co/collections/rl-research/dr-tulu 官方博客:allenai.org/blog/dr-tulu深度研究的未来属于不断进化的智能评价体系和灵活多样的知识检索,DR Tulu开创了这一新时代。