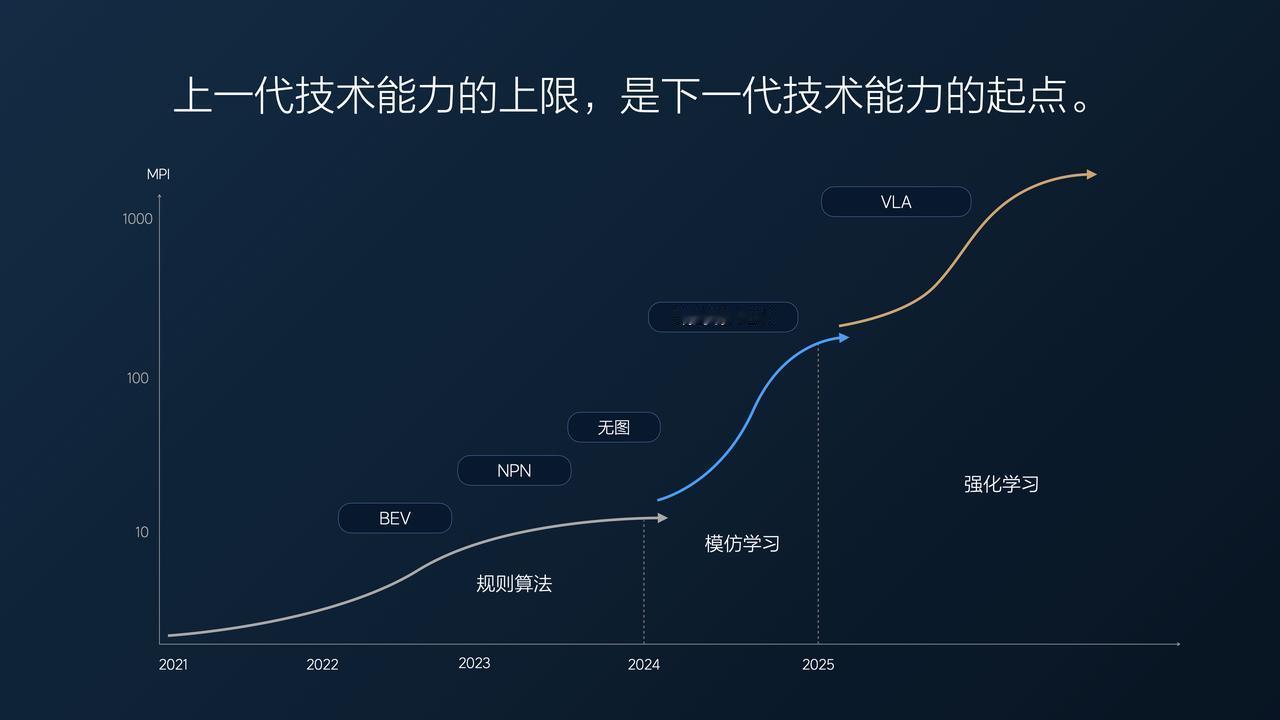
体验理想OTA8.1,能看的视野更远,比如识别红绿灯更早,能挑战连续的复杂路障,也就是更像人开车了。体验背后是技术,机器如何理解物理世界?理想郎咸朋直言“VLA是自动驾驶最好的模型方案”理想高管回应王兴兴质疑VLA(视觉-语言-动作)模型打破了传统自动驾驶“感知-决策”割裂的桎梏,凭借多模态融合实现了语义级的复杂环境理解,这正是李想所强调的汽车机器人必备的物理世界感知能力。其优势体现在三方面:一是天然适配具身智能,能构建道路场景认知图谱,可理解施工牌“临时封闭”的因果逻辑,实现类人推理;二是动态决策更灵活,在L4级场景中,语言引导的动作生成模块让突发状况下决策延迟降低40%,鲁棒性突出;三是数据效率革新,借助预训练能力将场景理解样本需求缩减70%,加速高阶自动驾驶落地。对比其他选手,理想押注VLA打造认知内核,让车辆从“执行”转向“理解”,VLA的成长会更像是人的成长,离不开大量的语言输入和更快的迭代。VLA路线不仅满足L4功能需求,更定义了自动驾驶的未来范式。