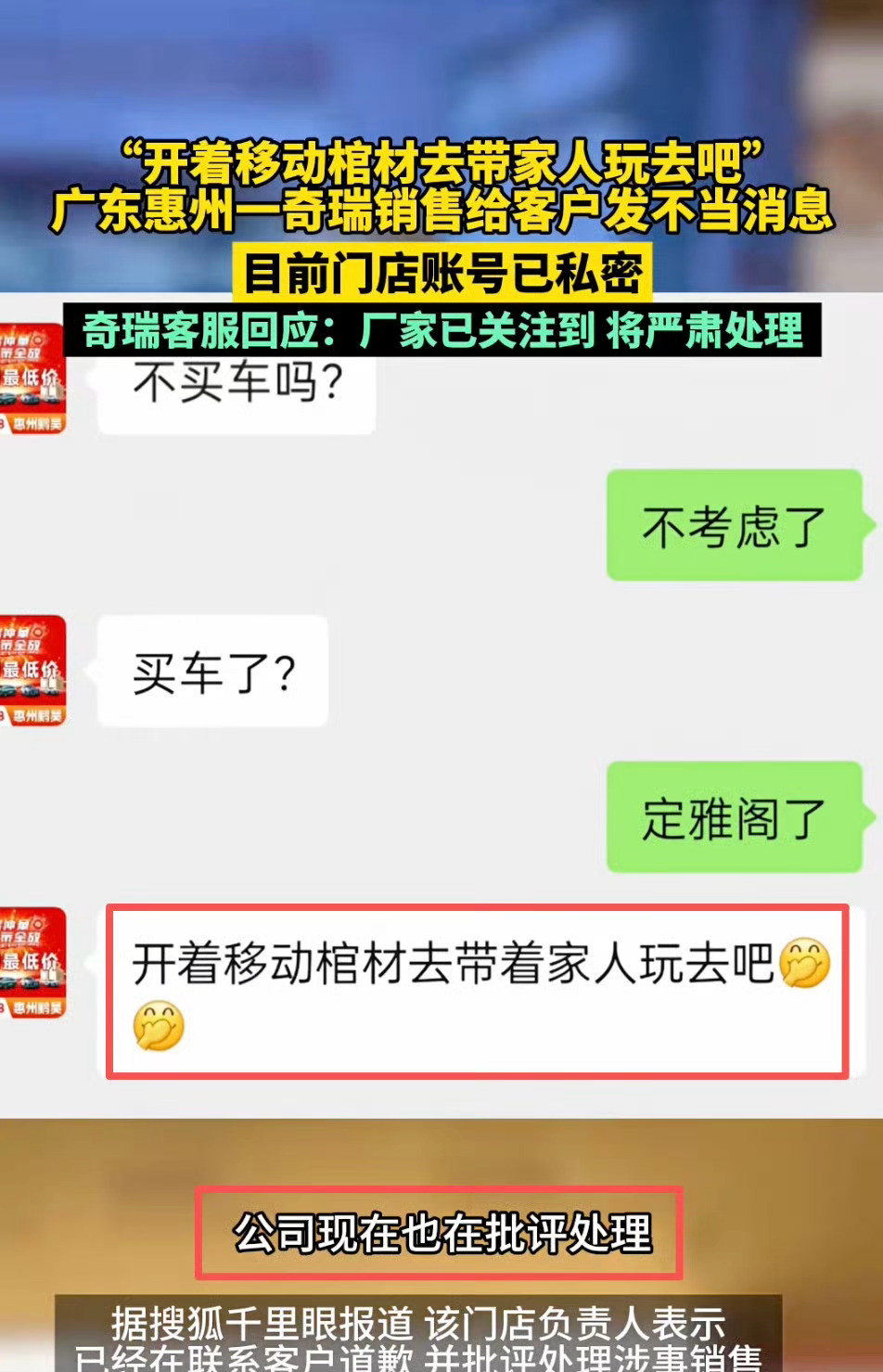
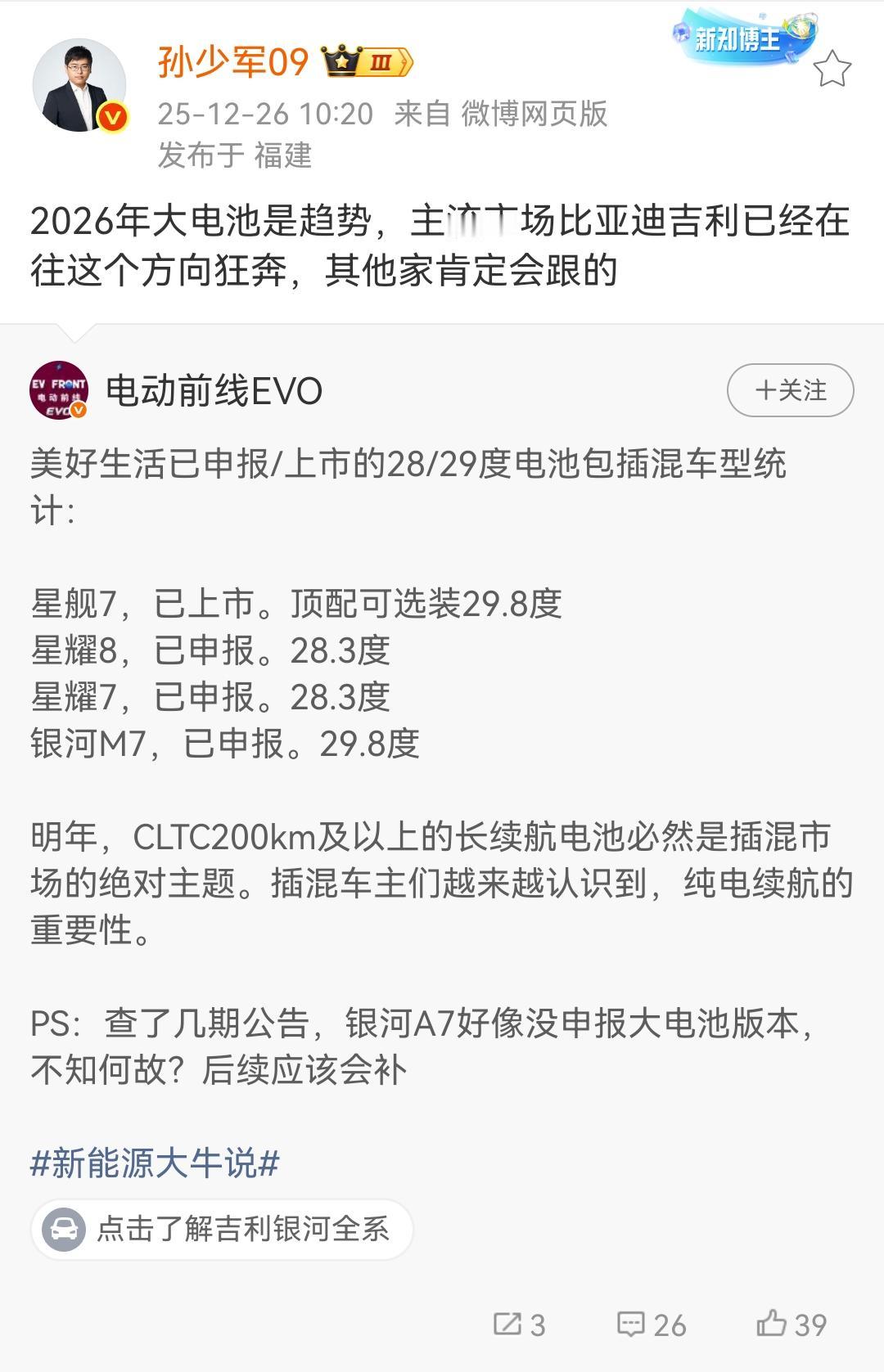
自动驾驶技术路线又卷出新高度了——从规则时代到端到端,现在进化到「端到端+世界模型+VLA」的融合架构。2023 年以前,自动驾驶靠「打补丁」——遇到电动车怎么办?写条规则。遇到大卡车,再写一条。结果系统越来越臃肿,像个缝缝补补的老旧软件。特斯拉 FSD V12 一出,直接掀桌子:别写规则了, 让 AI 学人类怎么开车。这就是端到端——输入摄像头画面,输出方向盘角度和油门刹车,中间全交给神经网络。但端到端有三个致命问题:问题 1:人类司机有好有坏,AI 会不会学到路怒症和加塞?答案是强化学习——通过奖励机制筛选好的驾驶行为, 让模型自己成长。问题 2:人类开车会推理,AI 怎么学会推理?答案是 VLA 模型——把大语言模型的推理能力嫁接到视觉识别上, 让车也能「思考」。问题 3:路面塌方、红绿灯掉落这种万年难遇的场景,数据从哪来?答案是世界模型——在虚拟世界里造各种极端场景, 让 AI 提前演练。不过 VLA 能推理但搞不定物理空间,世界模型理论上是终极形态, 但成本高、周期长, 短期内落不了地。行业一度陷入「选 VLA 还是选世界模型」的争论。这个时候特斯拉又掀了一次桌子:他们用 3DGS(高斯泼溅)技术,把真实场景重建成可训练的 3D 虚拟世界——比如把真实路口的红绿灯「掰弯」、「掰断」,生成低频数据喂给模型。这相当于给端到端架构外挂了一个轻量版世界模拟器。更绝的是:特斯拉把 3DGS 直接嵌入感知网络里,云端做数据预训练,车端还是跑传统端到端。这样既解决了数据稀缺问题,又没让架构变臃肿。推理能力上,继续用大语言模型那套自回归逻辑——A 触发多个 A1/A2/A3,选逻辑最自洽的进入 B,层层推导,最终形成「理解力」。简单来说,特斯拉把端到端、世界模型、VLA 推理三大技术路线融合了,搞出一个「集大成者」架构。目前看起来,这套融合架构是最优解,但不是唯一解。华为、小鹏这些走「端到端+强化学习」路线的厂商,在中国复杂路况下体验已经不输特斯拉了。自动驾驶新一轮军备竞赛已经打响,但是最终赢家肯定不是技术最炫的,而是体验最好、成本最优、最先规模化落地的那个。