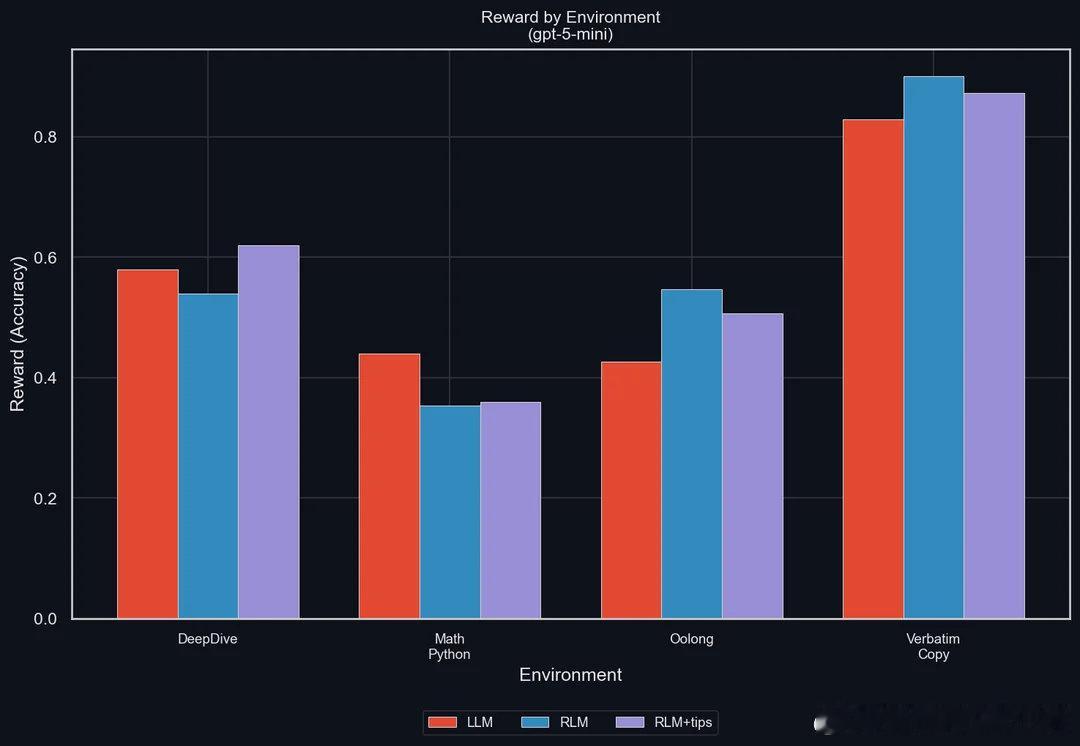
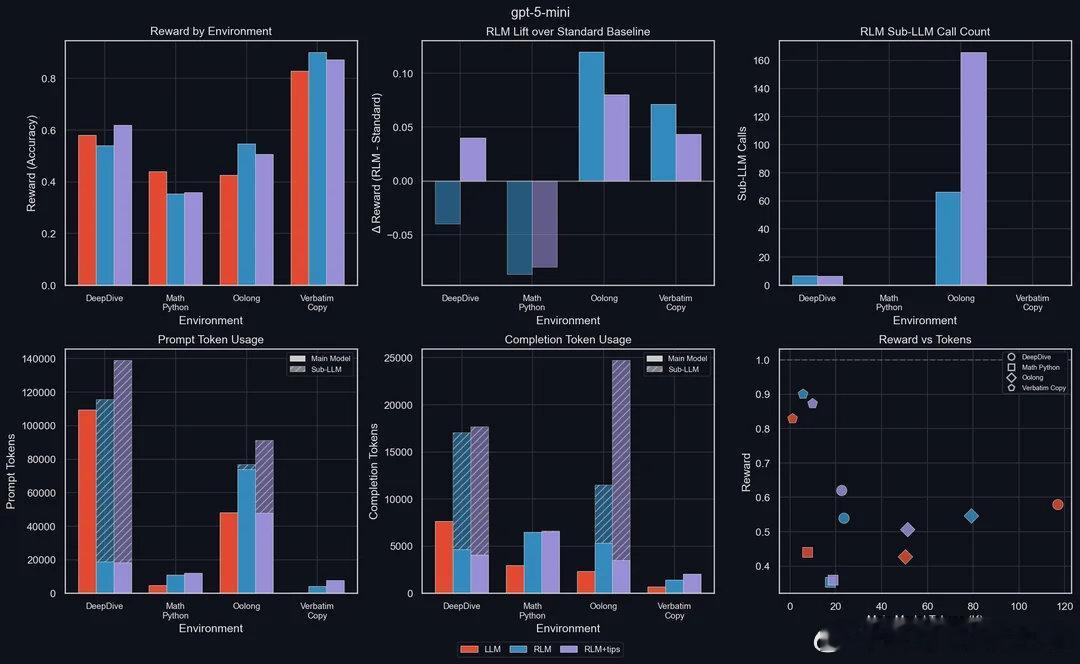
【当AI学会管理自己的记忆:递归语言模型如何终结"上下文腐烂"难题】Prime Intellect发布了递归语言模型(RLM),一种全新的推理策略,让AI不再被动接受冗长的提示词,而是主动将其视为可操作的动态环境。传统大模型有个致命软肋:上下文窗口越长,信息丢失越严重,业内称之为"上下文腐烂"。你给模型塞进去100页文档,它可能只记得开头和结尾,中间的关键信息早已模糊。RLM的解法很巧妙——它把输入数据当作Python变量来处理,模型自己决定检查哪些片段、拆分哪些任务、递归调用哪些子模块,整个过程在一个持久化的Python REPL环境中完成。几个核心突破值得关注:第一是"上下文折叠"。不同于传统RAG那种先总结再检索的套路(总结必然丢信息),RLM让模型主动把特定任务委派给子模型和Python脚本处理,信息完整性得以保留。第二是效率惊人。测试显示,用RLM包装的GPT-5-mini在长上下文任务上击败了标准GPT-5,而主上下文token消耗不到后者的五分之一。这意味着什么?小模型加上好策略,可以干掉大模型的暴力堆参数。第三是长程任务的连贯性。通过强化学习让模型端到端管理自己的上下文,系统能在跨越数周甚至数月的任务中保持思路清晰。这对真正的AI Agent至关重要——你不可能指望一个每隔几分钟就"失忆"的助手帮你完成复杂项目。同步发布的INTELLECT-3是一个1060亿参数的MoE模型(120亿激活参数),在Prime Intellect的完整强化学习栈上训练,性能对标闭源前沿模型,但完全开源开放权重。社区讨论中有个问题很尖锐:这和OpenAI、Anthropic现有的上下文管理方案有什么本质区别?答案在于层级不同。现有方案大多是外部编排,是"绕过"问题;RLM则把上下文管理内化为模型推理循环和训练目标的一部分,是"解决"问题。当任务需要持续运行数天甚至数周时,这个区别就会显现出来。有人评论说这个思路"显而易见到奇怪为什么不是默认做法"。确实,人脑处理短期记忆和规划任务时,本质上就是这么运作的——选择性关注、分块处理、递归调用。但"显而易见"和"能做好"之间往往隔着五年的工程积累,就像推理能力的研究2019年就有了,真正爆发要等到o1。更深一层看,这触及了一个根本问题:如果你想造出超越人类的智能,或许应该从无限递归上下文开始,因为这正是人类认知的运作方式。一个被冻结在时间中的大脑不可能真正学习或理解任何东西。迄今为止发布的每一个大模型,要么被冻结在时间中,要么在上线后不久就因为上下文问题而崩溃。当模型能够程序化地"窥视和检索"自己的提示词时,暴力扩展上下文窗口的路线是否已经过时?这个问题的答案,可能决定着下一代AI架构的走向。reddit.com/r/singularity/comments/1q1vcvf/prime_intellect_unveils_recursive_language_models