多模态融合技术使AI能同时处理文本、图像、音频、视频、传感器数据等多类型信息,并通过跨模态关联实现更接近人类认知的综合决策。其核心价值在于突破单模态信息孤岛,例如医生通过CT影像(视觉)+ 基因报告(文本)+ 心电图波形(时序数据)综合诊断疾病。
 1、技术演进里程碑
1、技术演进里程碑
单模态时代(2000年前):独立发展的OCR文字识别、语音识别技术
早期融合尝试(2010s):视频网站弹幕与画面时间轴对齐技术
深度学习突破(2020s):CLIP模型实现图文跨模态检索,准确率提升40%
大模型时代(2024-2025):GPT-4 Turbo支持10种模态输入,百度文心4.0实现动态权重融合
2、多模态融合技术原理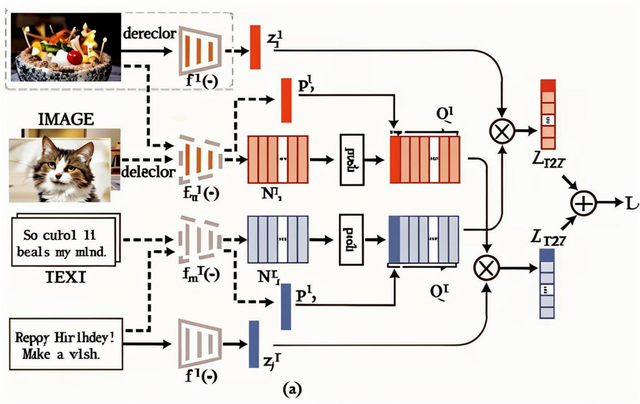
多模态融合技术的核心在于整合不同模态(如文本、图像、音频等)的数据,形成统一的理解和决策。其实现过程可分为以下关键步骤:
特征提取每个模态的数据通过专用模型提取特征:文本:使用BERT、GPT等模型转化为语义向量。图像:通过CNN或Vision Transformer提取视觉特征(如颜色、纹理、物体轮廓)。音频:通过频谱分析或语音识别模型提取音调、语速等特征。例如,医生诊断时,CT图像(视觉特征)与患者主诉文本(语义特征)分别提取后,再关联分析。
跨模态对齐将不同模态的特征映射到同一语义空间,解决数据同步性和语义差异问题。常用方法包括:
对比学习:例如CLIP模型,让“猫”的文本描述与猫的图片在向量空间靠近。注意力机制:识别模态间的关联权重,如视频中某段语音与对应画面匹配。例如,在自动驾驶中,雷达探测的障碍物位置与摄像头画面通过时间戳对齐,确保实时决策。
融合策略根据场景选择融合方式:早期融合:在特征提取阶段直接拼接多模态数据,适合高度相关的模态(如视频+音频)。晚期融合:各模态独立处理后再合并结果,适合数据质量差异大的场景(如文本+传感器数据)。动态融合:根据数据质量实时调整权重。例如夜间驾驶时,雷达数据权重高于视觉数据。3、多模态融合核心技术 跨模态检索与关联:通过向量数据库实现跨模态搜索,如用关键词“爆炸声”检索监控视频中的对应片段。
跨模态检索与关联:通过向量数据库实现跨模态搜索,如用关键词“爆炸声”检索监控视频中的对应片段。例如电商客服根据用户上传的破损商品图片,自动关联历史订单文本,快速处理售后2。
噪声与缺失数据处理噪声过滤对模态特定噪声(如图像模糊)使用加权平均融合;对跨模态噪声(如语音与字幕不同步)采用规则过滤;用生成模型(如GAN)补全缺失模态。例如仅凭CT图像生成可能的病理报告文本。
多任务联合训练单一模型同时处理多模态任务,提升效率:如Whisper模型同时完成语音识别(音频→文本)和翻译(文本→多语言)。例如:教育机器人批改作业时,识别手写文字(图像任务)并分析语法错误(文本任务)。
动态权重分配根据数据可信度调整模态权重:在工厂质检中,若摄像头被雾气干扰,则增加红外传感器数据的权重。 4、多模态检索的新方法及技术进展
4、多模态检索的新方法及技术进展 4.1 联合特征空间建模与互相关性显式分析原理:将不同模态(如图像、文本)映射到统一的语义空间,通过显式建模模态间的互相关性提升检索精度。例如,图像和文本的联合表示不仅捕捉各自特征,还通过互相关矩阵分析两者关联性1。案例:在电商场景中,用户上传一张“红色连衣裙”图片,系统通过联合空间模型检索出包含“夏季新款”“雪纺材质”等文本描述的关联商品,而非仅依赖单一模态的标签匹配1。4.2 多模态对比学习原理:利用对比损失函数拉近相关模态对的向量距离,推开无关模态对的距离。例如,CLIP模型通过对比学习使“狗”的文本描述与狗的图像在向量空间中靠近。应用:短视频平台中,用户输入“欢快的背景音乐”文本,系统可检索出匹配的音频片段或含有类似氛围的视频1。4.3 生成式跨模态检索原理:结合生成对抗网络(GAN)或扩散模型,生成缺失模态数据以辅助检索。例如,根据文本描述生成图像特征,再在图像库中检索相似内容。实例:医疗领域输入“肺部结节CT影像”文本描述,生成对应的特征向量,快速检索历史病例中的相似影像及诊断报告。4. 4 图神经网络驱动的跨模态关联原理:构建多模态知识图谱,利用图神经网络(GNN)挖掘模态间复杂拓扑关系。例如,新闻事件中的人物(文本)、现场图片(图像)、采访录音(音频)通过图结构关联。应用:媒体库中,输入某政治人物的演讲视频,可检索其历史言论文本、相关新闻报道及社交媒体动态。4.5 动态自适应融合策略原理:根据数据质量动态调整模态权重。例如,在低光照条件下,图像模态置信度降低,系统自动增强文本或传感器数据的检索权重。场景:自动驾驶中,夜间摄像头模糊时,系统优先根据雷达信号和导航文本数据检索障碍物信息。4.6 技术优势与挑战优势:上述方法显著提升了跨模态检索的精度与鲁棒性。例如,文献1指出,联合建模方法相比传统单模态检索,精度提升超30%。挑战:模态间的时间异步性(如直播弹幕与画面延迟)、语义冲突(如文本描述与图像内容不符)仍需进一步解决。5、多模态对比学习的局限性分析
4.1 联合特征空间建模与互相关性显式分析原理:将不同模态(如图像、文本)映射到统一的语义空间,通过显式建模模态间的互相关性提升检索精度。例如,图像和文本的联合表示不仅捕捉各自特征,还通过互相关矩阵分析两者关联性1。案例:在电商场景中,用户上传一张“红色连衣裙”图片,系统通过联合空间模型检索出包含“夏季新款”“雪纺材质”等文本描述的关联商品,而非仅依赖单一模态的标签匹配1。4.2 多模态对比学习原理:利用对比损失函数拉近相关模态对的向量距离,推开无关模态对的距离。例如,CLIP模型通过对比学习使“狗”的文本描述与狗的图像在向量空间中靠近。应用:短视频平台中,用户输入“欢快的背景音乐”文本,系统可检索出匹配的音频片段或含有类似氛围的视频1。4.3 生成式跨模态检索原理:结合生成对抗网络(GAN)或扩散模型,生成缺失模态数据以辅助检索。例如,根据文本描述生成图像特征,再在图像库中检索相似内容。实例:医疗领域输入“肺部结节CT影像”文本描述,生成对应的特征向量,快速检索历史病例中的相似影像及诊断报告。4. 4 图神经网络驱动的跨模态关联原理:构建多模态知识图谱,利用图神经网络(GNN)挖掘模态间复杂拓扑关系。例如,新闻事件中的人物(文本)、现场图片(图像)、采访录音(音频)通过图结构关联。应用:媒体库中,输入某政治人物的演讲视频,可检索其历史言论文本、相关新闻报道及社交媒体动态。4.5 动态自适应融合策略原理:根据数据质量动态调整模态权重。例如,在低光照条件下,图像模态置信度降低,系统自动增强文本或传感器数据的检索权重。场景:自动驾驶中,夜间摄像头模糊时,系统优先根据雷达信号和导航文本数据检索障碍物信息。4.6 技术优势与挑战优势:上述方法显著提升了跨模态检索的精度与鲁棒性。例如,文献1指出,联合建模方法相比传统单模态检索,精度提升超30%。挑战:模态间的时间异步性(如直播弹幕与画面延迟)、语义冲突(如文本描述与图像内容不符)仍需进一步解决。5、多模态对比学习的局限性分析
多模态对比学习(如CLIP模型)通过拉近相关模态的向量距离实现跨模态关联,但其在实际应用中仍存在以下核心局限:
5.1 模态对齐的天然鸿沟问题:不同模态的底层特征分布差异大(如图像的像素空间与文本的语义空间),导致向量空间对齐困难。例如,同一概念的视觉特征(如“苹果”的图片)与文本描述可能存在语义偏差(如水果 vs. 手机品牌)。案例:在医疗领域,CT影像的纹理特征与病理报告的专业术语难以直接对齐,需依赖大量标注数据强制映射,易引入噪声。5.2 数据质量与标注依赖高成本:对比学习依赖海量高质量配对数据(如图文对齐的标注),但现实场景中多模态数据常存在噪声或弱关联(如社交媒体图片与用户评论语义不符)2。偏差风险:若训练数据存在偏见(如性别/种族关联特定图像),模型会继承并放大偏差。例如,检索“CEO”时可能偏向男性形象。5.3 动态场景适应性差时序关联弱:传统对比学习难以处理视频、语音等时序数据的动态变化。例如,视频中人物动作与解说文本的跨帧关联需额外时序建模3。实时性挑战:工业质检中,传感器数据与图像需实时对齐,但对比学习的离线训练模式难以满足毫秒级响应。5.4 计算资源与效率瓶颈显存消耗大:对比学习需同时处理多模态数据,例如CLIP训练需数千GPU小时,中小型企业难以承受4。长尾分布问题:罕见模态组合(如手语视频+专业术语文本)因样本不足导致检索失效,需特殊采样策略补救。5.5 模态冲突与冗余处理不足冲突场景:当多模态信息矛盾时(如语音说“开心”但表情悲伤),对比学习可能因强制对齐而误判5。冗余浪费:若不同模态信息高度重复(如卫星图像与气象文本报告同一天气),模型无法有效筛选关键特征,导致计算资源浪费。5.6 前沿改进方向解耦表示学习:分离模态共享特征与私有特征,减少强制对齐的干扰(如腾讯ARC Lab提出的解耦对比框架)。自监督数据增强:利用生成模型(如扩散模型)合成高质量配对数据,降低标注依赖4。动态权重调整:根据场景自动分配模态权重,例如在低光照环境中降低图像模态的对比损失权重6、行业应用图谱领域
典型应用场景
技术组合
金融科技
上市公司风险预警
财报文本+工商图像+舆情音频
智能制造
设备故障预测
维修日志+红外图像+振动波形
医疗健康
远程影像诊断
CT切片+电子病历+语音主诉
新媒体
智能内容审核
直播视频+弹幕文本+背景音乐
