
Transformer 技术,一种变革性的 NLP 架构,利用注意力机制增强深度学习翻译模型的性能。自其首次引入以来,它已成为文本数据处理的行业标准,大幅提升了翻译质量。
凭借 BERT 和 GPT 等大型语言模型的突破,基于变压器神经网络架构的 AI 模型取得了显著进展,超越了以往的尖端技术,引领 AI 革命。
深入探索 Transformer 神经网络:
踏上一段理解 Transformer 基本原理和架构设计的旅程。我们将深入剖析其核心功能,同时揭开多头注意力机制的神秘面纱,揭示其作为 Transformer 关键所在的作用。
Transformer模型,计算语言领域的突破,超越了RNN。其独特性体现在其架构中,允许并行处理序列数据,提高了计算效率。在训练期间,Transformer利用自注意力机制学习序列中的依赖关系,并在推理期间动态地调整,处理输入的任何长度。
#01什么是 Transformer?
Transformer架构以其处理顺序文本的卓越能力而著称。它能接收文本输入并生成相应的文本输出,例如语言翻译(将英语句子转化为西班牙语)。
Transformer 架构的核心包含编码器组和解码器组,每个组由多个编码器或解码器层组成。每个层处理输入并生成输出,从而为后续层提供信息。
双向语言模型采用嵌入层处理输入数据,编码器组和解码器组各自对应一个嵌入层,生成对应输出,最终通过输出层输出最终结果。

所有的编码器结构相同,解码器也是如此。

神经网络架构包含编码器和解码器。编码器利用自注意力层建立文本序列内单词联系,前馈层处理信息。解码器添加编码器-解码器注意力层,增强自注意力层和前馈层的功能。每个编码器和解码器都有独立的权重集。
编码器是 Transformer 架构的基石,由可复用模块组成。该模块包括两层:自注意力层和前馈层。周围环绕着残差跳跃连接和两个 LayerNorm 层,确保模型的稳定性和性能。

#02注意力机制的作用是什么?
Transformer 的强大性能源于其使用的注意力机制。
这种机制允许模型在处理某个单词时,同时关注输入中与该单词紧密相关的其他单词。
不同单词有不同的词义关联,例如 “Ball” 与 “blue” 和 “holding” 紧密相关,而与 “boy” 无关。

Transformer 革命性的自注意力机制将每个输入单词与其序列中所有其他单词智能关联,提供更深入的上下文化理解。
举个例子:
借助自注意力机制,模型可以推断出"it"在不同语境中的含义。在"it指代猫"的句子中,该机制解析出"it"与"猫"的关联,而在"it指代牛奶"的句子中,则解析出"it"与"牛奶"的关联,确保模型准确理解文本。

Transformer 赋予每个单词多重注意力评分,以深入理解句意和语义,提升模型处理复杂语言任务的能力。
AI语言模型在翻译时,会优先考虑文本中的关键信息。例如,在翻译“it”时,模型将识别“cat”和“hungry”等重要元素,并在翻译中突出它们,从而确保准确传达文本的含义。

#03训练 Transformer
在训练和推理阶段,Transformer 的运作略有不同。
首先看训练阶段的数据流程。训练数据分为两部分:
源序列或输入序列(如翻译问题中的英文 “You are welcome”)目标序列或目标序列(如西班牙语的 “De nada”)Transformer 的目标是学习如何根据输入序列和目标序列来生成目标序列。

Transformer 的处理过程如下:
将输入序列转换成嵌入式表示(含位置编码)并送入编码器。编码器组处理这些数据,生成输入序列的编码表示。将目标序列加上句首标记,转换成嵌入式表示(含位置编码)并送入解码器。输出层将其转换成单词概率和最终的输出序列。Transformer 利用损失函数将模型输出与目标序列进行比对,利用此损失值在反向传播期间调整模型参数,从而优化 Transformer 的性能。#04推理
推理时,Transformer 以输入序列为基础,准确预测后续文本,无需辅助目标序列。这种模型能力展示了其强大的文本生成能力。
采用 Seq2Seq 模型的循环生成机制,每个时间步输出序列完整输入下一时间步解码器,直到句子结束标记出现。
与 Seq2Seq 不同,此模型在每个步骤中不仅输入上一步单词,还输入整个已生成序列,从而提高了信息利用率。

在推理过程中,数据流动如下:
1、将输入序列转换成嵌入式表示(含位置编码)并送入编码器。
2、编码器组处理这些数据,生成输入序列的编码表示。
4、解码器组结合编码器组的编码表示处理这些数据,生成目标序列的编码表示。
5、输出层将其转换成单词概率,并生成输出序列。
运用序列建模,我们选择预测序列末尾的单词作为预测目标。将其输入解码器,结合初始句首标记和序列首个单词,进行后续预测。
通过递归循环将生成的新单词添加到解码器序列中,直到预测出句子结束符。由于编码器序列在每次迭代中保持不变,可以省去重新编码和预测编码器输出的步骤,从而提高效率。
#05教师强制法
教师强制法是一种训练方法,将目标序列输入解码器,以帮助其学习正确的输出。此方法提高了模型的准确性,确保解码器从目标序列中学习准确的上下文信息。
在训练阶段,采用逐步生成并处理输出序列的循环方式会延长训练时间并增加难度。这是因为模型需要基于可能存在错误预测的前一个单词预测后续单词。
指导式解码为模型提供了准确线索,如教师引导学生般。即使模型初始预测有误,它也能根据目标单词自我修正,避免累积错误,提升预测精度。
#06Transformer 有哪些应用?
Transformer架构在自然语言处理领域广泛应用,赋能语言模型、文本分类等任务。它在序列到序列模型中表现出色,例如机器翻译、文本摘要、问答、命名实体识别和语音识别。
Transformer 模型的多样性体现在其根据不同问题量身定制的变体上。核心编码器层作为模型架构的基石,灵活搭配特定模块,满足不同的应用需求。
Transformer 分类架构
Transformer模型擅长情感分析,它接收文本输入,通过“头部”模块处理输出,从而预测文本表达的情感极性(积极或消极)。

Transformer 语言模型架构
语言模型以文本片段为输入,预测后续内容。它使用 Transformer 架构,其中头部模块分析 Transformer 输出,计算每个词汇表单词的概率。模型选择概率最高的单词作为预测输出。
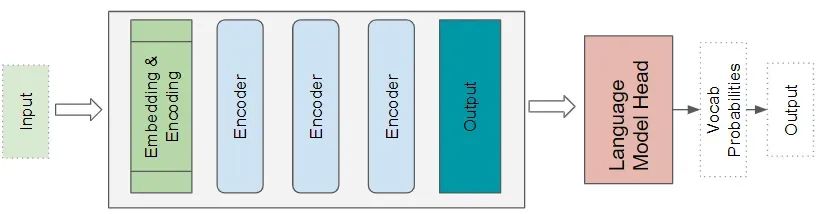
#07为什么优于 RNN?
RNN(循环神经网络)及其子模型 LSTM(长短期记忆)和 GRU(门控循环单元)曾主导自然语言处理领域,直至 Transformer 算法的出现。Transformer 自诞生以来,凭借其更强大的处理能力,已成为自然语言处理任务的首选架构。
RNN 序列到序列模型搭配注意力机制,可显著提升性能,注意力机制赋能模型专注于关键输入序列,从而提高预测准确性。
但是,它们存在两个主要限制:
难以处理长句中相隔较远的单词之间的长距离依赖性。递归神经网络 (RNN) 因其按顺序处理数据的能力而闻名。然而,其按时间步逐字计算的特性会限制训练和推理速度,因为它必须等待前一个时间步的计算完成才能继续下一个。卷积层限制了邻近元素之间的交互,确保特定区域内的像素或文本元素相互影响,为特征提取奠定基础。连贯的层级结构促进了更广泛元素的交互,从而提取更高层次的特征。Transformer 架构 revolutionizes NLP by eliminating RNNs. Leveraging solely the power of attention mechanisms, it streamlines language processing tasks.
它们能够并行处理序列中的所有单词,从而极大地提高了计算速度。
探索 Transformer 的内部奥秘!深入了解其工作原理,掌握它如何以 63% 的精度完成机器翻译任务的秘密。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
