AI浪潮迭起,大模型高效训练的达成需要以集群内更大规模的数据承载量和高效的传输速率为前提,在上周召开的英伟达GTC 2024上,我们也明确观察到网络技术能力再升级趋势,裸片、芯片、机柜间互连方式革新不断、带宽提速;而SerDes作为以太网、PCIe、NVLink等通信协议PHY层的底层技术支撑,其单通道传输速率向224G甚至更高演进成必然趋势。本文将从224G PHY&SerDes出发,展望AI数据中心内部有线通信的发展趋势。
摘要
D2D:裸片间通信需求增加,先进封装工艺不断进阶。D2D通信发生于芯片封装内部,其接口物理层可采用高速SerDes或高密度并行架构。我们认为随着Chiplet等众核异构渗透率逐渐提升,Die间通信需求有望进一步增加,对先进封装技术、互连标准提出更高要求:1)先进封装的精进如2.5D/3D封装能够为D2D连接带来更高I/O密度,台积电CoWoS作为主流2.5D先进封装技术广泛应用于A/H100等AI芯片封装;2)UCIe协议的出现有望助推Die间互连接口标准化以实现不同芯粒的自由整合,D2D互连生态有望趋于开放。
C2C:PCIe总线持续升级,NVLink引领片间通信新变革。主板总线是C2C通信的重要媒介,其中PCIe主要用连接CPU与高速外围设备,平均每三年升级一代标准,目前已迭代至6.0版本,16通道下可实现256GB/s的传输速率。在AI场景中,异构并行计算架构成为主流,我们观察到GPU间、异构xPU间的C2C互连逐渐由PCIe主导向性能更强的专用互连技术演进,NVLink实现GPU间高速、低时延的直接互连,并引入NVSwitch解决通讯不均衡,GTC 2024发布新一代NVLink和NVSwitch,C2C互连双向带宽提升至1.8TB/s。
B2B:机间高速互连提升AI训练效能,协议与硬件并进。我们认为,机间通信效率的提升需要协议和硬件端的配套支持:1)协议:从传统的TCP/IP向RDMA演进以优化网络性能,InfiniBand时延低、上线快、但生态相对封闭、价格高昂,RoCE性能略低于InfiniBand,然兼具成本效益和可扩展性,长期来看InfiniBand或与升级以太网平分秋色;2)硬件:接口传输速率需迭代上行,交换芯片作为核心硬件其性能面临升级,我们预期SerDes向224G演进有望为102.4T交换芯片的面世提供底层支撑,助力实现1.6T网络连接。
风险
AI大模型及应用发展不及预期,SerDes技术迭代不及预期。
正文
初探PHY:物理层功能及SerDes技术演进
何为PHY?
PHY(Physical Layer,物理层)位于OSI参考模型的最底层,连接数据链路层设备(通常称为MAC,即介质访问控制)与物理介质(如光纤、铜缆),承担了将设备上层数字信号和介质上的模拟信号相互转换的职能,PHY芯片(一种数模混合芯片)则是实现数据收发职能的重要硬件载体。
根据IEEE 802.3标准给出的物理层协议规范,PHY内部结构一般可拆解为3个子层(PCS、PMA、PMD)和2个接口(MII、MDI),具体功能模块数量和职能细节受不同互连介质及速率需求引出的不同通信标准影响。
► PCS(Physical Coding Sublayer,物理编码子层):PCS位于物理层架构的最顶层。向上,PCS通过MII/GMII连接RS(协调子层),实现MAC层与PHY层之间的互连。PCS主要功能包括:1)线路编码/解码和加扰/解扰,以确保数据传输可靠、有序;2)补偿上下行速率差异,以避免信息混乱和错误;3)正向/前向纠错(FEC),以降低噪声对传输质量影响。
► PMA(Physical Medium Attachment,物理介质连接子层):PMA的主要功能为串并转换、确定链路状态、恢复时钟、检测错误时间等。
► PMD(Physical Medium Dependent,物理介质相关子层):PMD主要完成向MDI输出信号、网络变压、光电转换等功能。
图表1:1000BASE-T1 PHY与OSI参考模型和IEEE 802.3 CSMA/CD局域网模型的关系

注:1)1000BASE-T1标准的MAC接口为GMII(Gigabit MII),即支持千兆网的MII接口;2)≥1Gbps的背板应用场景需要增加Auto-Negotiation
资料来源:IEEE官网,中金公司研究部
底层SerDes技术
SerDes为以太网、PCIe等数据通信协议提供物理层的底层技术支撑。SerDes是SERializer(串化器)/DESerializer(解串器)的简称,是一种主流的时分多路复用、点对点的高速串行通信技术,以太网、HDMI、PCIe、USB等高速串行链路数据通信协议的底层技术支撑均为SerDes。按照传输距离不同,SerDes可分为长/中/短距离的SerDes(LR/MR/VSR SerDes)、超短距离(XSR)SerDes和极短距离(USR)SerDes,分别用于背板(如在Ethernet switch PHY中)、芯片-芯片(如在PCIe/CXL PHY中)、芯片-模块(如在ODSP PHY中)、及裸片-裸片(如在Die-to-Die PHY中)等互连场景。
图表2:各传输距离SerDes及其应用场景

资料来源:Cadence官网,OIF,中金公司研究部
SerDes系统一般由发送端的串化器、驱动器和接收端的解串器、模拟前端组成,包含模拟电路和数字电路,通常集成在IP核中或以独立芯片形式存在。SerDes最早的单通道数据率一般在1.25-3.125Gbps,当前国际上成熟应用的SerDes最高速率为单通道112Gbps,基于PAM4 ADC+DSP架构设计,于2022年实现商用落地。我们认为,SerDes单通道传输速率的提升和性能优化依赖于脉冲幅度调制、高速ADC、数字信号处理等多种技术的演进以及制造工艺的升级。
► 脉冲幅度调制(PAM):先进的调制方式能够增加单次脉冲(单个码元)携带的bit数量,进而提升SerDes传输速率。例如,在NRZ(不归零编码)编码下,每个码元携带1个bit;在PAM4(第四代脉冲幅度调制)编码下,一次脉冲可呈现4个电平,每个码元携带2个bit,实现在相同带宽条件下单位时间传输效率(比特率)提升一倍。
► 高速ADC:NRZ调制方式下,采用传统的模拟前端即可,经过匹配-均衡-采样-解串后再进入数字域;而PAM4及更高调制方案下,电平数量的增加以及传输速率的提升带来串扰、非线性、噪声等问题,对接收端的采样能力提出更高要求,链路设计中一般在模拟前端增加ADC(模数转换器)将模拟信号先转为数字信号,反馈均衡、采样和解串则均在数字电路中完成。
► 数字信号处理(DSP):PAM4 SerDes系统加入DSP以发挥时钟恢复功能,通过生成所有可能的数据序列并和接收信号进行对比的方式识别最可能的传输序列,可有效补偿增益误差和时间偏移,同时增强系统对噪声的抵抗力,提升数据传输效率和稳定性。
► 先进制程工艺:先进制程工艺的升级能够帮助SerDes实现更低功耗和更高性能的互连,亦或推动新型架构的出现。各家芯片厂商陆续推出3nm制程SerDes,以满足AI和其他高速网络基础设施对数据带宽的更高要求。
为什么需要升级到224G?
AI浪潮驱动数据处理量激增,牵引云端算力需求提升。数据中心内部高速连接需求大幅增长,需要承载量更大的互连通道作为支撑。AI算力的提升,除了依靠单张GPU卡、SSD等核心硬件的性能升级,还需要更高的芯片间互连、片内互连能力作为有力支撑,从而实现多颗GPU的高效聚合、以及满足GPU访存和交换数据需求;而要提高整个AI集群的算力利用率,还需要提升片外通信速度以最大化单位时间传输的信息量,进而形成强大的集群有效算力。因此,我们认为大集群并不等于大算力,要实现AI集群训练效能的提升,板上芯片间、片内Die间、及片外互连能力均需进一步升级。
比较I/O带宽和计算单元算力,我们看到随着摩尔定律的放缓和半导体工艺趋近物理极限,I/O带宽与算力之间的差距不断扩大。随着晶圆迭代至5nm/3nm制程,晶体管密度接近极限,研发成本增幅扩大,摩尔定律趋于放缓。进入后摩尔时代,Intel、AMD等芯片厂商均采用多Die拓展的技术路线,Multi-Die系统将多个异构裸片集成在单个封装中,晶体管数量可增加至数万亿个,处理器计算能力大幅提升。然而,由于I/O引脚数量存在物理极限,I/O速率的提升与算力增长速度不成比例,根据新思科技官网,晶体管密度翻倍的同时,I/O性能仅提高了不到5%,数据传输能力一定程度上制约了芯片总算力的提升。
图表3:I/O带宽与算力之间的差距逐渐扩大

资料来源:新思科技官方公众号,中金公司研究部
综上,我们认为,数据中心集群持续扩容、互连带宽需求日益攀升的背景下,互连接口物理层(PHY)标准向224G甚至更高传输速率演进趋势加速确立。224G SerDes技术的突破也为片内、片外互连速度的提升奠定了基础,224G SerDes的优势体现在:以224G 以太网SerDes为例,1)减少线缆和交换机数量:单通道224G SerDes的应用能够大大减少数据中心所需的线缆和交换机数量,从而优化网络效率、并降低节点增加而导致的额外通信成本。2)降低传输功耗:OIF CEI-224G框架采用CPO(光电共封装)和OE(optical engine,光学引擎),缩短主机SoC与光学接口之间的电气链路,根据新思科技官网,224G SerDes每比特功耗较112G降低约1/3。
224G SerDes面临既定信道或距离类型下实现更高传输性能的挑战。回顾以太网数据传输发展过程,基于NRZ调制的模拟型28G SerDes的奈奎斯特频率为14G,56G/112G PAM4混合型SerDes的奈奎斯特频率分别为14G、28G,而当SerDes速率提升至224G,奈奎斯特频率需要翻倍至56G,引发更严重的链路损耗。此外,由于SerDes信号和干扰源之间的通道隔离没有得到改善,导致信号串扰加剧等问题。同时,更高的数据传输速率亦对更低的每比特功耗提出更高要求。新思科技表示在224G速率下要达到上一代的性能水平,SerDes设计复杂程度增加了5倍。
224G SerDes PHY设计已启动,商用部署进程有望加快。根据IP Nest,2023年已有几款224G SerDes设计启动,但224G SerDes客观存在的设计复杂性、功耗约束、以及对更先进调制技术的需求等问题导致其真正实施部署的难度较大,LightCounting预测首批224G SerDes将在2026年迎来部署上量,早期应用范围包括重定时器和变速器、交换机、AI扩展、光模块、I/O芯片和FPGA,成熟应用后有望延伸至更多数据需求领域。但我们观察到,产业端呈现出更加积极的部署信号,2024年或迎来初步应用:新思科技于2022年9月在ECOC 2022上首次演示224G SerDes,通过最小化模拟前端、在整个系统中引入大规模并行性和高级DSP技术实现高性能224G以太网PHY IP;Marvell在FQ4 2024业绩电话会上表示,其下一代单通道200Gb/s速率的1.6T PAM DSP产品已经在客户侧进行认证,预计将于今年年底开始部署;博通在3月20日召开的基础设施赋能AI投资者会议中表示其底层SerDes技术升级至单通道200Gb/s,基于3nm工艺制造。
图表4:224G SerDes频率、损耗及数量预测

注:奈奎斯特频率是为防止信号混叠需要定义最小采样频率,实际应用的采样频率为奈奎斯特频率的2倍,例如56G SerDes在NRZ方案下采样频率为28G,在PAM4下,由于每个脉冲含2个bit,采样频率为14G资料来源:新思科技官网,LightCounting,IP Nest中金公司研究部
展望:AI数据中心内部有线通信发展趋势
按照封装层级划分,数据中心内部有线通信由内至外可大致拆解为3层,分别为:Die-to-Die、Chip-to-Chip、Board-to-Board通信。其中,Die-to-Die(裸片间)通信是级别最小的通信,发生在芯片封装以内,实现芯片内部不同功能模块间的数据交换;向外延伸,Chip-to-Chip(芯片间)通信实现服务器主板上不同芯片间(如CPU-GPU)的数据沟通;在服务器外部,Board-to-Board通信实现服务器-交换机、交换机-交换机之间的数据传输,层层叠加形成数据中心集群内部组网架构。
我们认为,AI浪潮迭起,超万亿参数量多模态大模型的高效训练的达成需要以数据中心内更大规模的数据承载量和高效的传输速率为前提,集群内部Die-to-Die、Chip-to-Chip、Board-to-Board互连能力的全方位提升已成为确定性发展趋势。
图表5:数据中心各层级通信示意

资料来源:OIF,澜起投资官网,Alphawave官网,中金公司研究部
展望#1:Die-to-Die
D2D通信是芯片封装内部发生的裸片间超短距数据传输。D2D接口是裸片间数据传输的功能模块,通常由一颗PHY芯片和一个控制器模块组成。在物理层,裸片与裸片之间可采用高速SerDes架构或高密度并行架构,分别实现并行/串行数据传输,支持2D、2.5D、3D多种封装结构。
基于Chiplet(芯粒)的众核异构方案优势众多,Die间通信需求进一步增加。Chiplet将SoC拆解为实现特定功能的裸片,可复用不同制程的IP。Chiplet的优势在于:1)良率:通过集成小面积芯片,减少了晶圆缺陷对良率的影响;2)成本:基于不同功能的IP可灵活选择工艺制程,平衡性能和研发成本;3)算力:突破单芯面积限制,为晶体管提供更多物理平台;4)存储容量:Chiplet方案可以实现在单个封装体内多次堆叠,在增加存储容量的同时保持小型化;5)通信带宽:Chiplet采用高密度、高速封装和互连设计,能够有效提升计算和存储、计算和计算之间的带宽与信号传输质量,缓解“存储墙”问题。
Die间协议参差多样,互连生态逐步走向开放
Chiplet各裸片间的互连接口协议多样。Chiplet裸片的互连接口协议设计需要考虑与工艺制程及封装技术的适配、系统集成及扩展等复杂要素,同时需要满足不同应用领域对单位面积传输带宽、每比特功耗等性能指标的差异化要求,通常上述指标要求相互矛盾,因此Chiplet互连接口与协议的设计难度较高。Chiplet接口互连协议可以划分为物理层、数据链路层、网络层以及传输层。其中,链路层及以上接口更多依赖沿用或扩展已有接口标准及协议;物理层的互连协议繁多,带宽密度、传输时延、能耗等性能指标及实现工艺均存在差异。从连接方式来看,Chiplet在物理层有串行和并行两种互连方式。
D2D互连标准的不统一影响Chiplet的进一步发展。Chiplet的自由拼接依托于Die间通信协议的开放统一,但目前D2D接口通常基于厂家自身互连需求开发,芯粒自由组合并通过SiP封装的理想情景尚无法实现。我们认为,Chiplet的进一步发展很大程度上局限于裸片间通信PHY互连标准的不统一,面临设计好的成品日后接口不匹配、不同芯粒互连时资源浪费等问题。
图表6:Chiplet物理层部分互连标准一览

资料来源:CSDN,半导体行业观察,中金公司研究部
UCIe助力Chiplet接口标准化,D2D互连生态逐步开放。2022年3月,英特尔、AMD、Arm、高通、三星、台积电、日月光等芯片厂商,以及Google Cloud、Meta、微软等云厂商共同成立Chiplet联盟,联合制定Chiplet通用高速互连标准,即UCIe(Universal Chiplet Interconnect Express)标准,英伟达于2022年8月宣布将支持新的UCIe规范[1]。根据IP Nest预测,基于UCIe的D2D IP设计的启动数量远高于其他。我们认为,在UCIe标准的推动下,来自不同厂商、但基于相同接口标准的Chiplet芯片有望通过先进封装实现进一步整合,Chiplet生态体系有望逐步完善。
图表7:UCIe规范Chiplet物理层标准并实现性能提升

资料来源:UCIe官网,IP Nest,中金公司研究部
芯片封装进阶,先进封装需求大幅提升
先进封装技术优化连接,提升Die间通信速度。传统封装方式主要基于导线将晶片的接合焊盘与基板的引脚相连,实现电气联通,最后覆以外壳形成保护,主要方式有DIP、SOP、QFP等。由于Chiplet方案对比单片SoC牺牲了各功能模块间的布线密度和传输稳定性,传统封装可能难以满足Die间通信需求。先进封装的出现优化了裸片间的连接方式,有效缩短Die间信号距离,同时提供了更高的连接密度和通信带宽,提升通信质量并降低功耗水平。
先进封装通过对点或层的布局取代引线,提升引脚连接密度。其中,点连接包括Bumping(凸块)、TSV(硅通孔);层连接包括RDL(重布线层)和Interposer(中介层)。对点、层封装技术进行组合运用,形成了Fan-out、WLCSP(晶圆级封装)、Flip-chip(又可细分为FCBGA、FCCSP两种倒装)、2.5D/3D封装、SiP(系统级封装)等多种先进封装形式。根据Yole预测,先进封装在整体封装市场的渗透率有望持续提升,到2025年先进封装市场占比将升至49.4%;市场规模有望从2022年的443亿美元扩容至2028年的786亿美元,2022-2028年复合增长率达10%。从先进封装类型来看,2.5D/3D封装的市场增速领先,2022-2028 CAGR接近40%。
图表8:各类先进封装市场规模预测

资料来源:Yole,中金公司研究部
头部厂商加速先进封装布局,拓展2.5D/3D封装平台。全球先进封装技术主要由台积电、Intel、三星等头部厂商主导,其他封装厂商逐步跟进。以台积电为例,CoWoS(Chip On Wafer On Substrate)是先将芯片连接至硅晶圆,再将CoW连接至基板,其核心在于应用硅中介层以及Bumping和TSV等技术替代传统引线键合,提升引脚数量和互连密度。目前CoWoS等2.5D封装方式广泛应用于CPU、GPU、FPGA等芯片封装,是基于Chiplet芯片封装的主流方案。
凸点间距不断缩小,Die间互连密度提升。我们观察到,随着芯片在算速与算力上的需求持续提升,先进封装不断向功能多样化、连接多样化、堆叠多样化发展,封装形式对应的凸点间距越来越小,I/O密度和封装集成度随之提升,同时也导致封装难度变大。对比各厂商技术,台积电和Intel的封装能力较为领先。
展望#2:Chip-to-Chip
主板总线是C2C通信的重要媒介,实现板上芯片间数据传输。AI场景中,以CPU+GPU为代表的异构并行计算架构成为主流,C2C互连技术逐渐由PCIe主导向多节点无损网络演进。
PCIe持续演进,CXL顺势而生
PCIe是一种高速串行拓展总线标准,用于CPU与高速外围设备的连接。PCIe具有良好的向后兼容性,平均每三年升级一代标准,对应单通道速率翻倍增长。处理器I/O带宽平均每三年实现翻番,推动PCIe标准基本按照3年一代的速度更新演进。PCI-SIG于2003年正式推出PCIe 1.0版本,到2022年已迭代至6.0版本。2022年6月,PCI-SIG发布PCIe 7.0前瞻性文件,预计在保持相同编码/调制方案的基础上,传输速率再次翻倍至128GT/s(16通道下传输速率达512GB/s),完整标准规范将在2025年发布。
PCIe 6.0将开始应用224G SerDes,经网卡转换后可支持800G以太网。如前文所述,PCIe用于片内或机架内连接,以太网用于机架外连接,通过PCIe网络接口卡(NIC)可以将PCIe转换为以太网,再经过多层网络交换机实现以太网结构。根据新思科技官网,4通道PCIe吞吐量与单通道以太网最高数据速率相匹配,意味着x16 PCIe吞吐量等效于x4以太网端口带宽。PCIe 5.0利用当前已成熟商用的单通道112G SerDes技术,逐渐成为HPC和AI服务器场景中的主流总线;PCIe 6.0则将基于下一代224G SerDes,16通道下经过网卡转换可高效支持800G以太网(4通道)端口,根据PCI-SIG,PCIe 6.0预计将于2025年前后开启商用。
图表10:PCIe各版本规格参数

注:Flit Mode*表示流控单元模式,以Flit为最小单位进行数据传输
资料来源:PCI-SIG官网,中金公司研究部
PCIe标准迭代过程中信号插损也随之增加,引入信号调理技术可有效改善信号质量。为应对愈演愈烈的信号插损问题,PCIe从4.0时期开始引入信号调理芯片:1)PCIe Retimer:Retimer是一种数模混合器件,其工作原理是通过内部嵌有的CDR电路提取输入信号中的嵌入式时钟,再使用未经衰减变形的时钟信号重新传输数据,从而提升信号完整性并消除信号抖动影响。2)PCIe Redriver:通过发射端的驱动器和接收端的滤波器放大受损信号,实现对信号损耗的补偿。对比来看,Retimer能够实现比Redriver更优的降低信道损耗效果,但由于增加了数据处理过程时延有所拉长。PCIe Retimer在AI服务器中应用广泛,其市场规模有望扩容。Retimer芯片能够提升服务器、企业存储、异构计算和通信系统中数据传输时信号的完整性,典型应用场景包括NV Me SSD、AI服务器、Riser Card等。
CXL(Compute Express Link)协议基于PCIe物理标准,共享内存助力性能提升。2019年Intel主导并联合Meta、谷歌等公司发布新的互连协议CXL。CXL(CXL.io)运行在PCIe 5/6的物理层之上,具备和PCIe相当的物理及电气接口特性,提供高带宽,高可扩展性;同时,CXL提供额外协议(CXL.cache/mem)用于数据中心内设备之间的内存互访。2023年11月,CXL3.1新版本正式发布,是对3.0版本的渐进性更新,提出采用新的可信执行环境并优化了结构和内存扩展器。CXL相比于PCIe的优势在于:1)降低跨设备访问延迟,通过CXL协议,CPU与GPU可以绕过PCIe协议进行内存资源共享,形成内存资源池,有效降低CPU与GPU之间的延迟;2)提升内存容量,连接CXL的附加设备向CPU提供更多内存,低延迟CXL链路允许CPU将此额外内存与DRAM内存结合使用。
图表11:CXL协议及规范标准

资料来源:CXL官网,中金公司研究部
NVLink赋能GPU间高速互连
NVLink是专用于英伟达GPU之间的点对点互连协议。英伟达针对异构计算场景于2014年开发了NVLink技术,NVLink实现了GPU之间的直接互连,可扩展服务器内的多GPU输入/输出(I/O),提供相较于传统PCIe总线更加快速、更低延迟的系统内互连解决方案。NVLink 1.0的双向传输速率为160GB/s,此后NVLink随着GPU体系结构的演进而同步迭代升级。3月19日的GTC 2024 Keynote上,英伟达发布第五代NVLink高速互连方案,最高双向总带宽提升至1.8TB/s,较第四代提升一倍,约为x16 PCIe 5.0链路总带宽的14倍。我们认为,英伟达第五代NVLink技术的推出显著提升GPU间通信效率,有望从C2C互连层面进一步强化其AI芯片集群计算性能。
NVSwitch是NVLink技术延伸的产物,解决GPU间通讯不均衡问题。GTC 2024大会上,英伟达发布新一代NVLink Switch:单颗NVSwitch芯片采用台积电4NP制程工艺,支持72个双向200G SerDes端口(应用224G PAM4 SerDes技术)。新一代NVLink Switch最多可实现576个GPU的互连,大幅扩展了NVLink域,聚合总带宽提升至1PB/s,助力万亿级以上参数量AI大模型释放加速性能。
图表12:NVLink和NVSwitch各世代规格参数

注:“-”表示尚未披露公开信息资料来源:英伟达官网,中金公司研究部
NVLink-C2C将NVLink扩展至封装级,借助先进封装支持芯粒互连。NVLink-C2C基于SerDes和Link技术打造而成,可从PCB级集成、多芯片模块(MCM)、硅中介层或晶圆级连接实现扩展。以GB200超级芯片为例,英伟达利用NVLink-C2C技术构建封装级互连,Grace CPU与Blackwell GPU之间支持900 GB/s双向带宽的通信。
展望#3:Board-to-Board
AI大模型发展下,数据中心呈现两个趋势变化:1)网络流量高增长,且东西向(即服务器之间)流量占比大幅提高,根据思科预测,当前东西向流量占比或已达到网络流量的80-90%;2)网络架构逐渐走向多层不汇聚、少收敛、更具可拓展性的形态,如英伟达数据中心采用胖树架构构建无收敛网络,每一层网络总带宽保持一致。我们在以往报告《AI浪潮之巅系列:InfiniBand VS以太网,智算中心网络需求迎升级》中已详细论述了AI需要什么样的数据中心网络。
机间高速互连(B2B)是AI训练效能提升的重要一环。我们认为,AI集群训练效率的提升,对机间通信效率提出更高要求,一方面,组网协议作为数据运力动脉需要配套升级,从传统的TCP/IP向RDMA演进以优化网络性能;另一方面,接口传输速率需持续迭代上行。
图表13:智算中心相较传统数据中心,对通信性能要求提升
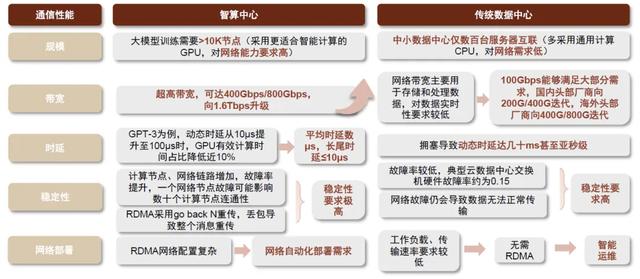
资料来源:中国移动研究院,百度开发者中心,信息化观察网,中金公司研究部
RDMA提高传输效率,IB和升级以太网方案或长期齐头并进
RDMA(Remote Direct Memory Access,远程直接内存访问)节省数据传输步骤,提升通信效率。目前主流RDMA方案包括三类,分别是InfiniBand、RoCE、iWARP。
► InfiniBand
InfiniBand从小众超算市场逐渐成为大规模AI训练集群的优先选择。2014年至今,在TOP100(全球超算排行100强)中,InfiniBand的占比显著高于以太网,2020年后,InfiniBand的占比超50%。而对于AI大模型驱动的智算中心建设需求,InfiniBand凭借极高吞吐量、极低延迟、高可拓展性(最高能扩展到具有数万个节点的集群)、快速上线、调优和维护大规模网络能力、无损网络构建能力等特性较好地满足上文提到的智算需求,在AI后端组网中的渗透率快速提升。
InfiniBand路线图显示,未来预期传输速度已规划至3.2Tb/s。目前InfiniBand的传输速度为400Gb/s(4通道,8芯光纤模式下)。2023年11月,IBTA发布XDR 800Gb/s InfiniBand的初始规范,最新路线图显示,XDR 800Gb/s将于2024年落地,单通道SerDes速率翻倍,支持XDR的网卡和交换机将提供每端口800Gb/s的传输速度,并支持1.6Tb/s端口速率的XDR交换机到交换机之间的连接;IBTA计划在2026年、2030年将InfiniBand网络性能继续提升至GDR 1.6Tb/s、LDR 3.2Tb/s。
图表14:InfiniBand路线图

注:在4X(4通道)以Gb/s为单位表示链路速度资料来源:InfiniBand Trade Association,中金公司研究部
InfiniBand组网优势突出,但存有成本高昂、生态封闭等问题。目前InfiniBand市场呈现Mellanox(英伟达子公司)一枝独秀的局面。InfiniBand组网需要使用的交换机、网卡等硬件产品仅英伟达一家可供应,从协议到软硬件整个生态较为封闭,英伟达在产业链中的议价能力强,导致通过InfiniBand协议部署的AI训练和推理基础设施的BOM成本高于以太网,据博通基础设施赋能AI交流会[2],基于以太网RDMA协议搭建的计算集群成本约为基于InfiniBand的50%或更低,我们认为InfiniBand在普遍性和经济性上或存在一定欠缺。
► RoCE
RoCE性能接近InfiniBand,多厂商优化流控、拥塞管理。我们认为,RoCE方案的以太网性能逐步接近InfiniBand,但和IB基于信用的流控机制不同,RoCEv2在基于PFC(基于优先级的流量控制)/ECN(显式拥塞通知)/DCQCN(数据中心量化拥塞通知)的流控机制对传统以太网络进行改造来保证无损网络时,可能出现PFC死锁、拥塞弥漫等问题。华为、新华三、浪潮等厂商均推出了自己优化后的无损网络解决方案。
多家科技巨头联合成立UEC,以联盟形式打造高性能以太网。为应对InfiniBand部署率提升对以太网市场份额可能造成的冲击,据Linux基金会,2023年7月,UEC(Ultra Ethernet Consortium,超以太网联盟)由硬件设备厂商博通、AMD、思科、英特尔、Arista、Eviden、HP和超大规模云厂商Meta、微软共同创立。自成立以来,UEC联盟成员不断扩大,彰显开放性生态优势。我们认为,虽然当前时点UET相关标准和技术还处于早期开发阶段,未来随着技术的逐步推广与落地,UET有望超越RoCE协议,对标InfiniBand,带领以太网网络在智算领域渗透率提升。
小结:InfiniBand和RoCE各有优劣,AI训练场景中InfiniBand协议先行,以太网+RDMA渗透加速。短期内由于算力资源紧张,部分厂商选择英伟达代建数据中心,借助InfiniBand的特性快速上线网络以训练大模型;长期来看,我们认为随着智算集群规模的持续扩容,AI大模型及应用厂商或倾向于寻求更具性价比的网络形式,叠加更多针对AI需求的以太网核心器件上市、UEC联盟的逐步成熟、RoCE针对AI网络的不断优化,能够和现网大规模的IP网络实现兼容互通的升级高性能以太网方案需求有望加速释出,在智算中心中的渗透率有望不断增长。
核心硬件性能升级带动交换速率提升
交换机是B2B通信的核心,交换芯片带宽提升推动机间高速互连。交换芯片作为交换机的性能锚点,决定交换机的总带宽、端口最大传输速率、缓冲时间等能力。结合我们的产业链观察,随着数据流量的持续攀升,交换芯片基本按照2年一代的速度实现速率翻倍。当前,全球范围内最先进的以太网交换芯片产品的带宽已行至51.2Tbps,博通、英伟达、美满电子、思科先后发布相关产品,2023年已有部分产品实现批量出货;LightCounting预计51.2Tbps的InfiniBand交换芯片将在2024年迎来量产落地。根据LightCounting(2023年4月报告)预测,到2028年,51.2Tbps交换芯片在以太网和InfiniBand的渗透率有望分别达到8%、54%,广泛应用于AI数据中心。
图表15:以太网交换芯片各速率出货量及预测

注:根据LightCounting2023年4月报告资料来源:LightCounting,中金公司研究部
图表16:InfiniBand交换芯片各速率出货量及预测

注:根据LightCounting2023年4月报告
资料来源:LightCounting,中金公司研究部
图表17:全球领先半导体厂商的高带宽交换芯片、交换机产品

注:1)“-”表示未公开披露;2)Jericho3-AI全双工模式下交换芯片速率可达28.8Tbps;3)英伟达Quantum系列官网仅披露交换机配置,未披露搭载的交换芯片具体性能参数资料来源:各公司官网,TechWeb,半导体行业观察,中金公司研究部
100G+高速SerDes的逐渐成熟和商用落地从技术端推动了51.2T超大带宽交换芯片面世。展望未来,我们认为SerDes将继续向224G演进,有望带动102.4T及更高带宽交换芯片上线。根据Yole报告展示的交换芯片升级路线图,Yole预计在2025年和2027年有望分别迎来带宽为102.4T和204.8T的交换芯片的批量上市,电气接口单通道SerDes速率实现从112G到224G的突破。全球以太网交换芯片龙头博通在3QFY23业绩会上表示,为实现下一代1.6T以太网连接,2023年已开始开发Tomahawk 6交换芯片(应用224G SerDes),吞吐能力超过100Tb/s,按照此前博通交换芯片每1.5-2年升级一代,我们预计公司超100Tb/s带宽的交换芯片将于2024年稍晚推出。
从交换机带宽、端口速率来看,随着AI后端网络加速向高速迁移,51.2T交换芯片在2024年将进一步部署,400G+端口速率交换机有望在AI集群中收获增量,Dell’Oro预测到2025年,400/800G交换机渗透率将达到85%,1.6T交换机亦有望开始逐步上量,到2027年成为数据中心交换机主流端口速率。
图表18:AI集群后端网络中不同端口速率交换机渗透率及预测

注:包括以太网交换机和InfiniBand交换机
资料来源:Dell’ Oro,中金公司研究部
PHY及SerDes产业链梳理
从PHY&SerDes芯片产业链看,上游主要包括Synopsys、Cadence等PHY IP核及EDA厂商,中游芯片设计厂商包括博通、美满电子、瑞昱、德州仪器、高通等Fabless或IDM厂商。
图表19:PHY芯片产业链上游、中游概览

注:“~”表示公司PHY芯片市场份额资料来源:裕太微招股书,中金公司研究部
SerDes设计实现IP化,成为接口IP市场增长的重要驱动力。接口IP持续向高速演进,高端接口IP市场张力十足。我们认为,AIGC的发展对数据传输的带宽和时延均提出更高要求,将进一步推动PCIe、以太网、存储等接口协议升级,底层SerDes技术亦不断高端化。根据IPnest预测,2022-2026年PCIe、DDR、以太网和D2D四类接口IP市场规模的年均复合增速约为27%,其中高端品类(PCIe4.0及以上&CXL、高级DDR、高端以太网、D2D)增速较快,2022-2026年CAGR高达75%,贡献未来接口IP市场主要增量,IPnest预计到2026年四类高端接口IP市场规模合计有望达到21.15亿美元。
图表20:2021-2026年高端接口IP市场规模预测

注:高端以太网指基于56G、112G、224G SerDes的PHY
资料来源:IPnest,中金公司研究部
IP核和EDA市场由海外头部厂商主导且集中度较高,龙头企业IP+EDA软件业务协同。IP市场主要由Synopsys、ARM等海外厂商主导,根据IPnest数据,按IP许可和版税收入排名,2022年全球IP市场top3厂商分别为Synopsys、ARM和Cadence,市占率分别为30%、25%和7%,CR3超过60%。Synopsys和Cadence在EDA市场份额同样较高,根据TrendForece数据,2021年全球EDA市场top3厂商分别为Synopsys、Cadence和西门子,份额分别为32%、30%和13%。
聚焦SerDes IP环节——SerDes技术供应商集中在北美,国产厂商加速布局。目前市场上主要存在两类SerDes厂商:1)第三方SerDes供应商:授权SerDes IP给芯片商使用并收取专利授权费。全球领先的第三方SerDes厂商Synopsys、Cadence、Alphawave等均为美国公司;当前国内市场SerDes IP自给率仍较低,本土厂商正在突破112G SerDes技术。2)自研厂商:博通、Marvell、英特尔等厂商根据自身需求或帮下游客户设计SerDes IP,定制化属性较强。
聚焦以太网PHY芯片环节——以太网PHY芯片市场由境外厂商主导,国产化水平相对较低。根据中国汽车技术研究中心数据,全球以太网PHY芯片主要由博通(美国)、美满电子(美国)、瑞昱(中国台湾)、德州仪器(美国)等境外厂商主导,2020年全球以太网PHY芯片市场Top5厂商份额合计超91%;国内市场侧,主要参与者与全球市场大体相似,瑞昱份额相对较高(28%),Top5厂商份额合计超87%。国内以太网PHY芯片厂商主要包括裕太微、景略半导体(脱胎于美满电子)等,国产PHY芯片目前市占率较低,且集中于车载场景的低速率产品,我们认为未来在中高速PHY芯片领域的替代空间尚为广阔。
风险提示
AI大模型及应用发展不及预期。随着全社会数字化转型及智能化渗透率的提升,人工智能持续赋能各行各业。而人工智能依赖于海量数据进行模型训练,推动全社会算力需求大幅攀升,对通信硬件设备传输速率、拓展性、兼容性等要求较高。若AI大模型及应用发展不及预期,可能放缓D2D、C2C、B2B等通信向超高带宽升级的需求。
SerDes技术迭代不及预期。高速SerDes设计面临降低功耗、减少噪声与扰动等设计难点,同时需要依靠先进制程工艺以优化SerDes整体性能。如若以上环节攻克遇阻,则会导致SerDes单通道传输速率的迭代速度放慢,进而拖累接口物理层传输升级整体步伐。
[1]https://www.uciexpress.org/post/ucie-announces-incorporation-and-new-board-members-at-fms-2022
[2]https://investors.broadcom.com/static-files/4378d14e-a52f-409f-9ae4-03d810bc7a6c
文章来源
本文摘自:2024年3月23日已经发布的《通信技术10年展望系列——224G PHY已启航,数据中心有线通信迈向新征程》
分析员 陈 昊 SAC 执证编号:S0080520120009 SFC CE Ref:BQS925
联系人 郑欣怡 SAC 执证编号:S0080122070103
分析员 李诗雯 SAC 执证编号:S0080521070008 SFC CE Ref:BRG963
分析员 彭 虎 SAC 执证编号:S0080521020001 SFC CE Ref:BRE806
法律声明

