

随着 ChatGPT 的现象级走红,引领了 AI 大模型时代的变革,从而导致 AI 算力日益紧缺。与此同时,中美贸易战以及美国对华进行 AI 芯片相关的制裁导致 AI 算力的国产化适配势在必行。
国产 AI 芯片方面,昇腾910B、含光、寒武纪思元、壁仞、燧原等都已经推出。
国产知名AI芯片厂商包括昇腾、海光和天数智芯等。这些产品展示了中国在AI芯片领域的强大实力。为了让您更直观地了解这些产品,我们将简要概括如下
1. 昇腾:作为华为旗下的AI芯片品牌,昇腾系列在性能和功耗方面表现出色,广泛应用于数据中心、边缘计算等领域。
2. 海光:由寒武纪推出的AI芯片,具有高性能和低功耗特点,适用于各种AI应用场景。
3. 天数智芯:由北京天数智芯科技有限公司研发的AI芯片,具有较高的性能和集成度,可满足多种AI计算需求。
第一梯队:昇腾、海光;第二梯队:天数、沐曦、寒武纪、太初元碁、壁仞;第三梯队:摩尔线程、燧原;目前来说,国产AI芯片市面上昇腾相对容易碰到一点,海光、天数等也有一些。
本文将分析目前国内知名AI芯片厂商的软件生态。目前主流的路线主要有三种:
华为和寒武纪都是芯片制造商,他们选择从芯片到计算平台库都全自研。华为基于自己的Ascend系列ASIC构建的CANN计算平台库,而寒武纪基于自家的MLU系列ASIC构建的Neuware。选择自研+开源路线的另一种方法是海光信息,他们自主研发了DTK(DCU Toolkit)计算平台库,并兼容开源的ROCm。同时,DTK还适配了自家研发的DCU,使其与CUDA和GPU相媲美。由于兼容了ROCm开源计算平台库,海光DTK的通用性得到了进一步保证。此外,海光DCU的支持也使得DTK发展成为一个相对成熟的生态环境。好的,我可以帮你优化文章内容。以下是我建议的天数智芯和摩尔线程是两家自研+兼容CUDA的公司,他们在API接口协议和编译器层面与CUDA对应一致。
昇腾华为推出的昇腾芯片,采用自家研发的达芬奇架构,是专为人工智能任务设计的处理器。包括昇腾910(用于深度学习训练)和昇腾310(用于推理),这两款芯片在国际市场上,主要与英伟达GPU竞争;而在国内市场,昇腾芯片则与寒武纪、海光等厂商的AI芯片产品一较高下,如思元590、深算一号等。
昇腾软硬件全栈共5层,从底层的Atlas系列硬件、异构计算架构,到顶层的AI框架、应用使能和行业应用,全面提升性能与智能。

华为AI框架层,包括自家研发的MindSpore(昇思)和经过优化适配的第三方框架(如PyTorch、TensorFlow等),以实现高效运行在昇腾芯片上。目前,训练框架主要支持Pytorch和Mindspore,为大型模型训练提供了ModelLink和MindFormers两种解决方案。
应用使能层包含:ModelZoo、MindX SDK、MindX DL、MindX Edge、MindIE等核心组件,助力高效AI开发。
MindIE主要用于大模型推理,目前未开源。ModelZoo:存放模型的仓库MindX SDK:专为特定领域打造,助力快速开发并部署AI应用。工业质检、检索聚类等轻松应对。简化昇腾AI处理器推理业务开发,降低门槛,让您轻松上手。MindX DL是一款强大的深度学习组件,专为Atlas训练卡和推理卡设计。它具备昇腾AI处理器集群调度、性能测试以及模型保护等核心功能,助力合作伙伴快速搭建深度学习平台。MindX Edge(昇腾智能边缘组件):全面管理边缘AI业务容器,确保安全可信。助力客户轻松构建边云协同边缘计算解决方案,快速实现边缘AI业务。异构计算架构(CANN)是英伟达CUDA + CuDNN的有力竞争对手,为多种AI框架提供支持,同时服务于AI处理器。这一关键平台在提升昇腾AI处理器效率方面发挥着至关重要的作用,包括各种引擎、编译器、执行器和算子库等。其被称为异构软件,是因为它不仅承载了AI芯片,还兼容通用芯片。这就需要一层软件来实现算子的调度、加速和执行,并最终自动分配到相应的硬件上(CPU或NPU)。

昇腾计算开放编程框架AscendCL是对底层昇腾计算服务接口的封装,它提供运行时资源(例如设备、内存等)管理、模型加载与执行、算子加载与执行、图片数据编解码/裁剪/缩放处理等API库,实现在昇腾上进行AI开发。
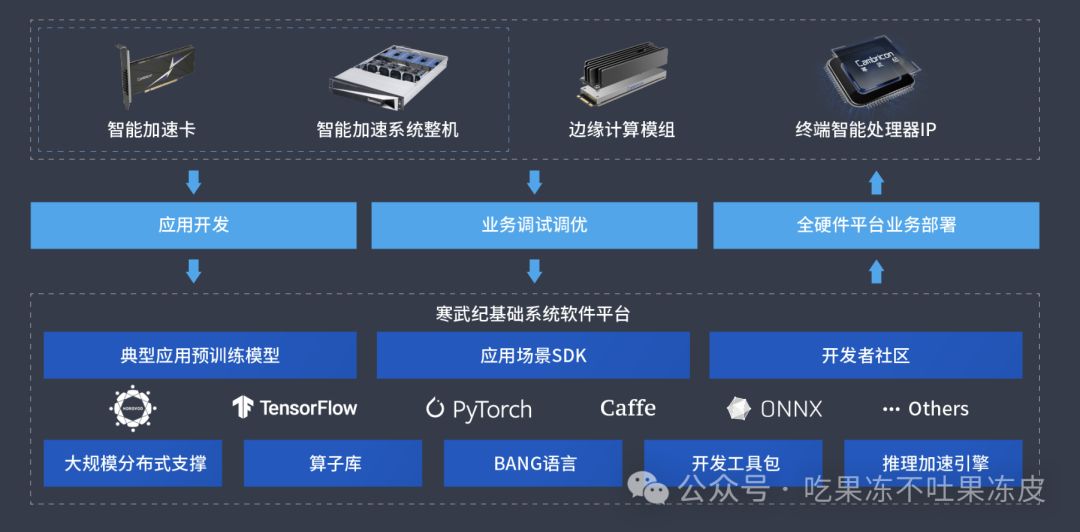
寒武纪Cambricon NeuWare是寒武纪专门针对其云、边、端的智能处理器产品打造的软件开发平台。其采用云边端一体、训推一体架构,可同时支持寒武纪云、边、端的全系列产品。

Neuware软件架构以深度学习应用为核心,依托主流框架,融合寒武纪机器学习编程库CNML、Bang编程语言、运行时库CNRT等多层次技术,为多媒体智能处理提供全面支持。此外,还包含针对多媒体智能处理的SDK,助力各类应用场景的智能化升级。
Neuware集成了多种开源深度学习编程框架,如TensorFlow、Caffe和PyTorch等。此外,它还支持Android NN,但仅适用于寒武纪处理器IP核。这些框架的API与官方开源框架保持一致,同时内部实现也针对寒武纪智能处理器进行了定制优化。"寒武纪机器学习计算库CNML,为深度学习应用提供基础算子,让开发者构建神经网络模型及机器学习算法更得心应手。无需担心内部硬件资源调度,一切尽在掌握。"寒武纪的运行时库CNRT,是一个为寒武纪智能处理器提供的上层编程接口。这个库能有效实现硬件资源的交互和调度,从而增强了寒武纪智能处理器的功能性。用户能够通过调用CNRT与CNML协同开发深度学习应用,或者直接利用CNRT来高效地运行Neuware构建的神经网络离线模型,大大提升了计算效率和应用体验。寒武纪Bang语言,专为寒武纪智能处理器设计,兼容C99和C++11语法特性,助力高性能程序开发。新增类型系统与硬件紧密结合,充分发挥处理器算力,提升性能表现。Neuware编译器针对寒武纪产品,提供Bang语言和汇编语言编译,优化高级汇编语言以适应各类寒武纪硬件,输出可在设备上运行的二进制文件。"CNGDB,一款专为Linux系统设计的Bang语言调试工具,借助GNU GDB的强大调试能力,实现寒武纪处理器产品设备侧与主机侧代码的同步调试。"CNPerf(Cambricon Neuware Performance)是一款专为寒武纪智能处理器设计的性能优化工具,助您深入剖析产品性能。优化后的文章:CNMon,这款专为寒武纪智能处理器设计的系统工具,能实时采集硬件底层信息并揭示上层软件对硬件资源的调度状态。"CNQual,一款专为寒武纪智能处理卡设计的全面诊断软件,深度挖掘硬件性能。它不仅能进行精准的功耗测试、PCIe链路状态诊断,更能模拟硬件压力,验证多卡互联状态。借助CNQual,我们保证寒武纪智能处理卡在各种环境下稳定运行,为您的系统带来无与伦比的可靠性和效率。"CNCL(Cambricon Communications Library,寒武纪通信库)是面向 MLU 设计的高性能通信库。它提供了一套完备的接口来支持常用的集合式通信原语,包括前面提到的broadcast、reduce、alltoall等。好的,我可以帮您优化这篇文章。请问您需要优化哪些方面?比如语言表达、文章结构、数据呈现等等。如果您有具体的要求或者需要进一步的帮助,请告诉我。支持多种 MLU 处理芯片的互联技术,涵盖 PCIe、MLU-Link、RoCE、Infiniband Verbs 和 Sockets,为各种场景提供高效、便捷的连接解决方案。Neuware软件栈拥有多样化的多媒体开发工具,涵盖了CNStream、Gstreamer等视频智能处理SDK以及CNCodec图片、视频编解码SDK,助力多媒体应用的高效开发。寒武纪云边端一体、训推一体开发和部署流程如下所示。
海光信息采用自研开发的DTK(DCU Toolkit)计算平台库,兼容开源的ROCm。DTK是海光的开放软件平台,封装了ROCm生态相关组件,同时基于DCU的硬件进行优化并提供完整的软件工具链,对标CUDA的软件栈,为开发者提供运行、编译、调试和性能分析等功能。
ROCm,这个由AMD主导的开源计算平台库,是其Radeon GPU产品品牌的延伸。除了ROCm,还有一系列简称如ROCx,包括ROCr(运行时),ROCk(内核驱动程序)和ROCt(thunk)。这些平台不仅提供了强大的性能,也为开发者们打开了新的可能性,让他们能够更自由地利用AMD Radeon GPU的潜力。
ROCm是AMD公司为了对标CUDA生态而开发的一套用于HPC和超大规模GPU计算提供的开源软件开发平台。ROCm支持AMD的GPU和APU,以及x86和ARM架构的处理器,提供了与CUDA相似的编程模型,使得在AMD GPU上编写和运行GPU计算应用程序变得更加容易。
虽然从发布的时间来看,ROCm比CUDA晚了将近10年,但ROCm生态发展很快,已经能够提供与CUDA类似的API、工具以及各种函数库,因此,上层的深度学习框架可以基于ROCm的生态进行构建。

CUDA和ROCm的对比:
海光DTK(DCU ToolKit)是海光的开放软件平台,封装了ROCm生态相关组件,同时基于DCU的硬件进行优化并提供完整的软件工具链,对标CUDA的软件栈,为开发者提供运行、编译、调试和性能分析等功能。
基于DCU硬件优化,提供软件工具链,对标CUDA栈,助力开发者实现运行、编译、调试及性能分析等多功能。
提供深度优化的计算加速库,原生支持TensorFlow、Pytorch、PaddlePaddle等框架以及Open-mmlab、Vision、FastMoe等组件。具备FP32/FP16/INT8多精度训练和推理功能,广泛应用于计算机视觉、智能语音、智能文本、推荐系统和强化学习等多个人工智能领域。
海光DTK生态社区(https://cancon.hpccube.com:65024/1/main)是一个功能齐全的平台,提供DTK适配版本、AI生态包、驱动和性能分析工具包等资源。每年4月和10月,社区会发布两个稳定的DTK版本。据悉,24.04版本已经发布,相较于23.10版本,在AI模型训练和推理方面有了显著提升,同时针对当前大热的大模型进行了针对性优化和适配。
针对每个DTK版本,AI生态包提供了丰富的深度学习框架选择(如:PyTorch、TensorFlow等),以及大模型加速训练与推理的工具包(如:DeepSpeed、VLLM等)。轻松下载whl文件,一键安装,实现便捷操作。
海光光合社区,作为国产AI算力基础生态建设的佼佼者,提供全面且易上手的性能及压力测试工具。强烈推荐,值得鼓励!
海光提供光源社区(https://sourcefind.cn/#/main-page),适配DCU硬件的环境镜像和模型仓库一应俱全,下载即用,轻松进行测试。
天数智芯天数智算软件栈兼容主流GPU通用计算模型,提供等效组件、特性、API和算法,与CUDA(10.2)接口协议和编译器层面保持一致,助力用户实现系统或应用无缝迁移。由于支持常用GPU通用计算API,用户无需修改代码即可完成迁移。
融合了TensorFlow、PyTorch、PaddlePaddle等国际主流深度学习框架,提供与官方开源框架相同的算子,并针对天数智芯加速卡持续提升性能。天数智算软件栈的函数库为深度学习应用提供丰富的基础算子,助力开发者轻松构建各类神经网络模型和机器学习算法。ixBLAS:兼容 CUDA 主流版本ixFFT:兼容 CUDA 主流版本ixDNN:适配 cuDNN v7.6.5ixRAND:适配 cuRAND v10.1.2CUB:适配 CUB v1.8.0CUTLASS:适配 CUTLASS v2.5.1THRUST:适配 THRUST v1.9.7ixSPARSE:兼容 CUDA 主流版本CV-CUDA:适配 CV-CUDA v0.4ix-TransformerEngine:针对Transformer Engine v1.6.0的专业级优化,助您轻松应对各种任务。ixPROF ⼯具能够收集和查看追踪数据,可针对天数智芯加速卡进⾏性能剖析。ixKN 工具是一款用于抓取 CUDA 核函数(kernel)执行期间性能分析指标 (event/metric) 数据的工具。它可以帮助您更好地了解代码的性能瓶颈,从而优化您的代码。ixGDB 工具是一款基于 CUDA-GDB 的开源调试工具,专为天数智芯加速卡的 CUDA 应用程序而设计。为了发挥天数加速卡的极致性能,天数智芯⾃研了推理框架和引擎:IxFormer:专为大型模型推理加速而设计的高效框架,支持当前市场上主流的大型模型推理加速,实现在天数智芯加速卡上的卓越性能。同时,它还具备对vLLM和TGI框架进行推理加速的功能。天数智芯IxRT:专为业界主流框架优化的推理加速引擎,助力视觉、语音、推荐及自然语言等领域模型在天数智芯卡上实现卓越推理性能。天数智芯提供基于 Kubernetes(K8s) 集群系统的 GPU 虚拟化方案,其中包括 VGPU 方案。燧原燧原科技的计算及编程平台TopsPider,以创新的编程模型、开放的接口和专业的profiling工具为基础,支持适应性图优化策略、算子泛化和系统级设备虚拟化。同时,它拥有高效的分布式训练能力,通过软硬件协同架构设计,充分挖掘邃思芯片的潜力。
Enflame GCU硬件配套的软件生态矩阵包括核心异构加速计算平台(驱动、运行时、编译器、开发者工具)以及扩展开发库、计算图、框架、AI开发相关的工具集,上层还提供丰富的模型、镜像、解决方案和AI开发平台等。软件组件众多,可归为以下6大类别:
1. 驱动:包括GPU驱动和CPU驱动;
2. 运行时:包括CUDA Runtime和OpenMP Runtime;
3. 编译器:包括CUDA Compiler和OpenMP Compiler;
4. 开发者工具:包括NVVM、Nsight Systems和Nsight Compute;
5. 计算图:包括CUDA Graph and OpenACC;
6. AI开发相关的工具集。
TopsPlatform,即TopsRider核心异构加速计算平台,支持X86和ARM平台的稳定驱动。兼容众多Linux发行版,提供高效的设备管理、资源管理和虚拟化功能。编译层包括TopsCC异构编译器和编程模型,以及性能分析/调试工具,助力用户快速编写自定义GCU程序。计算平台以上的扩展库包括预编译算子库、计算图编译器、通信库和多媒体库。TopsATen预编译算子库保持用户界面的稳定兼容并带来性能跃升。ECCL显著降低通信开销,同时降低对接复杂性。GCU新增加多媒体支持,软件提供适配FFmpeg库的解码接口;TopsCV图像处理接口 。AI Framework提供燧原稳定适配的主流深度学习框架和自定义推理框架Topsinference,联合下层组件实现诸多新功能和性能提升,在传统领域持续增强动态性支持和计算图加速。AI Framework提供燧原稳定适配的主流深度学习框架和自定义推理框架Topsinference,联合下层组件实现多项新功能和性能提升,在传统领域持续增强动态性支持和计算图加速。
"AI Development Toolkit深度参与开源社区,提供一揽子工具集。其中包括大模型推理引擎vLLM和Text Generation Interface(TGI)的GCU版本,致力于支持Huggingface社区开源库以低成本构建运行AIGC任务。更值得一提的是,新推出的TopsCompressor能有效支持大模型低精度量化。借助AI Toolbox,我们可以进行精度与性能调试,同时对传统模型进行低精度量化。"Data Center Toolkit,又称TopsCloud,是一款Kubernetes集群下GCU部署运维的工具套件。它包括基础设备和Kubernetes插件,支持集群自动化安装升级、调度、可视化监控告警,以及golang二次开发组件。这款工具套件可以帮助您更轻松地管理和维护您的Kubernetes集群,提高工作效率。Enflame GCU Center的镜像库和解决方案扩展了基础环境支持。AI Platform提供可视化AI开发部署平台,涵盖算法、数据集、服务部署管理和集群设备调度监控功能。特别推出的AIGC文生文、文生图、图生图场景无代码应用平台,助力AI开发更轻松。相关名词:
GCU
General Compute Unit, 燧原科技通用计算单元
TopsRider
燧原科技驭算软件栈
Enflame Driver
燧原科技GCU驱动程序
EFSMI
燧原科技GCU设备管理界面
TopsRuntime
燧原科技运行时库
TopsCodec
燧原科技GCU编解码运行时接口
TopsCC
燧原科技异构计算编译器
TopsKit
燧原科技开发者工具包
TopsProf
燧原科技查看GCU和CPU活动的命令行性能分析工具
TopsVisualProfiler
燧原科技查看GCU和CPU活动的可视化性能分析工具
TopsPTI
燧原科技高级自定义性能分析接口
TopsGDB
燧原科技异构编程调试器
TopsTX
燧原科技记录GCU程序调用过程上下文信息的工具
TopsGraph
燧原科技计算图AI编译器
TopsATen
燧原科技对齐Pytorch Aten语义的预编译计算库
TopsCV
燧原科技图像处理工具
FFmpeg-GCU
燧原科技视频编解码工具
ECCL
燧原科技集合通信库
TopsInference
燧原科技推理加速框架
TopsCompressor
燧原科技模型压缩工具
TopsIDEAS
燧原科技模型推理调试工具
TopsModelGraph
燧原科技模型可视化开发调试工具
TopsAIserver
燧原科技服务化推理部署工具
EGC
Enflame GCU Container,燧原科技官方容器镜像库
TopsCloud
燧原科技GCU Kubernetes集群部署运维工具套件
TopsStation
燧原科技端到端应用开发部署与管理运维平台套件
LumiCanvas
燧原科技支持文生图文生视频业务的应用工具
LumiVerse
燧原科技支持文生文业务的应用工具
总结在一些项目中,昇腾、海光和天数都有所应用。总体来看,昇腾的算力表现优秀,但自研CANN生态存在较多问题。海光则依赖于ROCm生态,表现适中;而天数由于兼容CUDA,上层应用迁移相对容易。尽管如此,国产主流AI芯片的计算平台与基于CUDA生态的竞争对手(如华为的CANN、寒武纪的Neuware等)仍存在一定差距,尤其是基于ROCm开发的海光DTK。
随着国家对自主可控的持续投入,越来越多的公司将采购国产AI芯片。同时,基于相应厂商的AI计算平台库进行适配开发。期待AI算力基础设施全栈国产化、性能追赶CUDA,让我们共同成为国产AI芯片崛起的见证者。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
