TROBO: A Novel Deep Transfer Model for Enhancing Cross-Project Bug Localization
ZiyeZhu1,YuWang1,andYunLi1,2
1 Jiangsu Key Laboratory of Big Data Security and Intelligent Processing, Nanjing University of Posts and Telecommunications, Nanjing, People’s Republic of China.
2 State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, People’s Republic of China
引用
Zhu, Z., Wang, Y., Li, Y. (2021). TROBO: A Novel Deep Transfer Model for Enhancing Cross-Project Bug Localization. In: Qiu, H., Zhang, C., Fei, Z., Qiu, M., Kung, SY. (eds) Knowledge Science, Engineering and Management. KSEM 2021. Lecture Notes in Computer Science(), vol 12815. Springer, Cham. https://doi.org/10.1007/978-3-030-82136-4_43
摘要
TroBo模型是一种新型的深度迁移学习技术,旨在解决项目开发初期缺乏bug修复历史数据的问题,从而提高自动bug定位的准确性。该模型能够将已标记数据丰富的源项目知识转移到新项目上,有效处理非结构化的bug报告文本,并通过对抗性学习识别项目的通用和独特特征。TroBo模型引入了项目感知分类器,区分共享和独有特征,提高了性能。在四个大型真实项目上的实验表明,TroBo模型的表现优于现有技术。
1 引言
在软件开发过程中定位错误是软件质量控制中非常重要且耗时的任务。最近,自动错误定位任务被视为一个结构学习问题,旨在捕捉bug报告和对应错误代码文件之间的关联。具体而言,bug报告记录了开发人员、测试人员和最终用户报告的错误或意外结果(即bug)的各种信息。表1显示了在在线Bugzilla系统中记录的SWT项目的一个bug报告。在过去的十年中,已经提出了各种监督学习方法用于自动错误定位,这些方法已被证明是有效和高效的。然而,这些方法在应用于定位早期开发或不成熟项目中的错误时表现不佳。主要原因是缺乏足够的bug修复数据(即带有相应错误代码文件标签的bug报告)用于训练这些监督模型。
表1. 来自Bugzilla的SWT bug报告样本。

跨项目错误定位作为一种颇具前景的解决方案,通过引入迁移学习技术,旨在克服不成熟项目在错误修复数据方面的匮乏。研究表明,采用源-目标架构——一种专门的迁移学习模型——能够实现从源项目(拥有充足错误修复数据的项目)到目标项目(错误修复数据不足的项目)之间共享知识的学习与传递。例如,Huo等人开发的TRANP-CNN深度迁移学习模型,能够同时识别源项目和目标项目共有的特征,并据此在目标项目中定位错误文件。但是,该模型在知识传递过程中未能有效过滤掉源项目的特有特征,这些特征对于构建针对目标项目错误定位的健壮模型不仅无益,反而可能产生负面影响。为了解决这一问题,Zhu等人提出了名为CooBa的对抗性迁移学习模型。该模型采用对抗性训练策略,从代码的共享表示中剔除项目特有的特征,并利用个体特征提取器来识别每个项目的独有特征。尽管如此,CooBa模型仍面临特征冗余的挑战,因为无法确定项目特有特征是否包含了共享特征。这两种模型在处理错误报告时都使用了全知识转移编码器,这是因为所有错误报告都是以自然语言编写,并记录了代码中的错误。然而,错误报告的核心内容属于非正式文档,即用户生成的文本,而这两款模型都未充分考虑错误报告处理过程中噪声的影响。
基于上述观察,本文提出了一种名为TroBo(Transfer Knowledge for both Bug reports and Code files)的新型深度迁移模型,用于提升跨项目错误定位的性能。具体来说,TroBo通过一个全知识转移编码器学习所有错误报告的自然语言知识,并采用软注意力机制自动过滤掉错误报告中与错误无关的内容。对于代码文件,TroBo包含了一个针对每个项目的独有特征提取器,以捕捉项目独有的特征。TroBo还利用了对抗性训练策略,包括一个共享特征提取器和项目鉴别器,以捕捉项目间共享的通用特征。更为重要的是,本文在代码嵌入层之后构建了一个项目感知分类器,旨在促使代码嵌入层捕捉每个项目的特征。增强后的代码嵌入层将提高对抗性训练的性能,并解决特征冗余问题。在大型真实项目上的广泛实验表明,本文的模型在所有评估指标上均显著优于现有技术。本文的主要贡献如下:
本文提出了一种名为TroBo的深度错误定位模型,该模型满足了缺乏历史错误修复数据项目的训练需求。本文的模型采用了一个全迁移学习模块,以共享目标项目错误报告的知识,同时有效减轻了文本噪声问题。本文构建了一个部分迁移学习模块来学习代码表示,并设计了项目感知分类器以增强对抗性训练,避免特征冗余。2 技术介绍
本节将详细介绍所提出的TroBo模型,该模型用于跨项目的错误定位。图1展示了我们模型的总体架构,它包括三个核心组件:错误报告学习模块、代码文件学习模块以及相关性预测器。
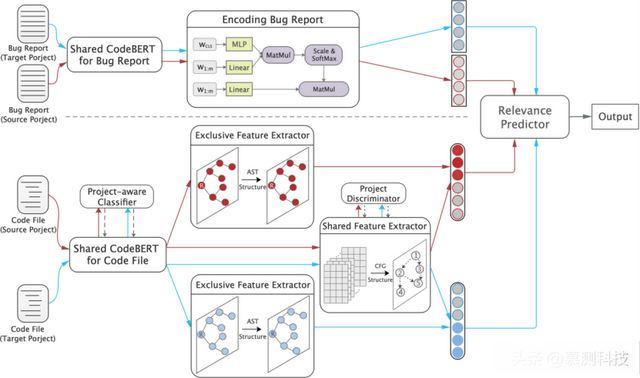
图1. TroBo模型的总体框架,包括错误报告学习模块、代码文件学习模块以及相关性预测器
2.1 学习Bug报告
输入表示。我们使用CodeBERT,这是一种基于BERT的双模态预训练模型,适用于自然语言和编程语言,将错误报告映射到相应的嵌入序列。具体来说,我们选择错误报告的摘要和描述部分,并将它们视为一个单词序列。一个错误报告进一步表示为一个单词嵌入序列,其中m是单词的数量。
编码层。在我们的任务中,来自不同项目的错误报告都是用相同的自然语言(即英语)编写的。考虑到目标项目的错误报告数量有限,我们需要将来自源项目错误报告中学到的自然语言知识应用到目标项目上。因此,我们的TroBo模型被设计为通过全知识转移的方式,学习来自源项目和目标项目所有错误报告的知识。
正如我们之前提到的,错误报告是非正式的文本数据,通常包含一些与错误无关的信息(即噪声)。为了过滤掉这些噪声,我们采用了软注意力机制[1]来自动突出错误报告中的关键信息。我们将错误报告编码为所有单词嵌入的加权和,具体方式如下:,其中,是单词的权重,表示其在输入错误报告中的重要性。也就是说,包含关键信息的单词具有更高的权重,而对于任务无用的单词则具有较低的权重。的计算方式如下:

其中,[CLS] 是由 CodeBERT 提供的一个特殊标记,其最终的隐藏表示被视为用于分类或排序的聚合序列表示;MLP 表示一个双层多层感知器网络。在这里,我们使用 [CLS] 的最终隐藏表示来表示错误报告的全局信息。需要注意的是,整个错误报告学习模块在不同的项目之间是共享的。
2.2 学习代码文件
受近期关于共享-空间组件分析的工作启发,TroBo模型显式地为每个项目建模了独有特征和共享特征。具体来说,我们首先在嵌入层之后提出了一个项目感知分类器,这可以增强嵌入层对输入项目的敏感性。然后,我们为每个项目构建了一个独有特征提取器,基于抽象语法树(AST)来捕捉项目独有的特征。同时,我们利用对抗性训练策略来提取源项目和目标项目之间的共享特征。对抗性训练策略包含一个基于控制流图(CFG)的共享特征提取器和项目鉴别器。为了引导模型产生这样的分离特征,我们进一步添加了正交性约束,鼓励这些部分的独立性。
输入表示。对于代码文件,我们将其视为n个代码标记的序列,并使用CodeBERT的预训练权重作为每个标记的初始化。值得注意的是,我们为嵌入错误报告和代码文件分别设置了两个独立的CodeBERT(如图1所示)。然而,CodeBERT缺乏项目感知能力,无法区分源项目和目标项目的特征。这可能导致对抗性训练的崩溃(尤其是对于项目鉴别器)以及独有特征和共享特征之间的特征冗余。作为回应,我们通过一个额外的项目感知分类器来适应这个CodeBERT,鼓励代码嵌入层捕捉每个项目的特征。具体来说,我们设置了一个双层多层感知器网络作为项目感知分类器,以预测输入标记嵌入序列的项目标签,即来自源项目还是目标项目。为了简化,项目感知分类器可以表示如下:

其中是输入代码序列开头的[CLS]标记的最终隐藏表示。我们使用softmax交叉熵来优化项目感知分类器:
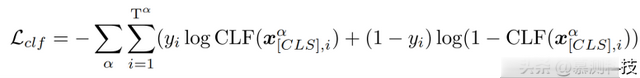
其中;表示输入、i的真实项目标签;Tα 是项目 α 的训练实例数量。通过这种方式,我们使用调整后的 CodeBERT 将代码文件转换为一个标记嵌入序列 x = {x1, x2, ..., xn},其中 n 是代码文件中的标记数量。标记嵌入 x 包含了不同项目的特定特征,这些特征增强了下游的对抗性训练,并解决了我们任务中的特征冗余问题。
独有特征提取器。为了从单个项目中提取独有特征,我们使用了多层图卷积网络(GCN)来处理基于AST的代码文件。具体来说,代码图 GAST = (VAST, EAST) 是通过代码文件对应的AST构建的,其中 VAST 是AST中的节点集,每个节点代表一个代码标记;EAST 是包含AST中标记之间链接的边集。相应的节点嵌入矩阵 X 由标记嵌入序列 x 转换而来。然后,GCN 直接在AST代码图上操作,并根据节点的邻域属性诱导节点嵌入向量,遵循逐层传播规则:

其中是无向图的邻接矩阵,添加了自连接,I是单位矩阵;;表示激活函数;和 Wl 分别是第 l 层的节点隐藏表示和可训练的权重矩阵;H0=X。对于来自项ɑ的代码文件,其对应的独有特征提取器(具有相同的结构但没有共享参数)生成的独有特征如下:

对抗性训练。除了每个项目特有的独有特征外,不同项目之间共享的公共特征能够更有效地建模多个项目之间的更一般的关联。为了提取这样的项目不变特征,我们将对抗性训练策略整合到我们的模型中。一般来说,对抗性训练策略[5]包含生成器和鉴别器。对于我们的任务,生成器的目标是提取共享特征,而鉴别器则预测提取的特征来自哪个项目。
共享特征提取器。为了在不同项目之间生成共享表示,我们采用了卷积神经网络(CNN)层和多层图卷积网络(GCN)的组合来处理基于控制流图(CFG)的代码文件。首先,我们使用CNN学习每个代码语句的语义信息,这在代码处理和分析任务中得到了广泛应用。我们设置了小尺寸的卷积核(例如,1、3、5)来提取代码中的词汇和语义特征。给定一个代码文件,CNN层最终提供了一个语句表示序列 n = {n1, n2, ..., nu},其中 u 是代码文件中的语句数量。因此,我们基于代码文件的CFG构建了代码图GCFG = (VCFG, ECFG),其中VCFG是CFG中的节点集,每个节点代表一个代码语句;ECFG 是包含CFG中语句之间链接的边集。相应的节点嵌入矩阵 N 从语句表示序列n转换而来。CFG代码图的操作类似于独有特征提取器。为了简化,我们使用Esh来表示CNN与GCN的组合结构,并从不同项目中提取共享特征如下: 项目鉴别器。项目鉴别器被设计用来预测输入项目的标签,即来自源项目还是目标项目,从而鼓励共享特征提取器产生表示,使得项目鉴别器无法可靠地预测提取特征的项目。项目鉴别器可以表示如下:
项目鉴别器。项目鉴别器被设计用来预测输入项目的标签,即来自源项目还是目标项目,从而鼓励共享特征提取器产生表示,使得项目鉴别器无法可靠地预测提取特征的项目。项目鉴别器可以表示如下:
其中,MLP 表示一个两层的多层感知机网络。对抗性训练过程是一种最小-最大优化,可以形式化为:

其中,代表项目ɑ的训练实例数量,和分别表示共享特征提取器和项目鉴别器的可训练参数。通过这种方式划分特征,训练于共享表示的鉴别器能够更好地在各个项目之间泛化,因为其输入未受到每个项目独有的特征的污染。
特征融合。从专属特征提取器和共享特征提取器中,我们为每个代码文件获得了一个专属表示和一个共享表示。由于专属表示和共享表示之间的部分特征可能存在重叠,我们在合并它们之前,采用了正交性约束[3]来针对每个项目解决这一问题:

其中表示Frobenius范数的平方。然后,代码文件的表示通过一个双层MLP网络生成:

在这里,⊕表示串联操作。
2.3 相关性预测器
相关性预测器的目标是通过对错误报告和其相关代码文件的信息进行学习,来捕捉它们之间的相关性模式。由于目标项目缺乏足够的标注数据用于训练,我们构建了一个跨源项目和目标项目的共享相关性预测器。为了预测一个错误报告和一个源代码文件的相关性,我们计算它们在嵌入空间中的映射之间的距离。相关性的度量定义如下:

在这里,表示L2范数的平方。每个项目的任务损失函数定义为:

其中通过等式 12 计算;τ是一个间隔参数,用来确保相关对的距离小于不相关对的距离。
2.4 训练
鉴于源项目 s 的标注错误-修复数据以及目标项目 t 的相应数据,最终的训练目标定义如下:

其中、和是超参数;和通过等式13计算。I (b, c) = 1 表示(b, c)来自源项目,反之亦然。在训练过程的每次迭代中,我们交替地从源项目或目标项目采样一批训练实例来更新参数。我们采用 Adam [12] 优化算法直接最小化我们模型中的最终损失函数 L。
3 实验结果与分析
3.1 实验设置
数据集。我们在四个开源项目上进行了大规模实验,包括 AspectJ、JDT、SWT 和 Eclipse Platform UI。该数据集是通过问题跟踪系统(Bugzilla)和版本控制系统(GIT)提取的。考虑到错误与不同修订版本相关,每个项目的每个错误报告都检出了其源代码包的修复前版本。
比较基准。我们将我们提出的模型 TroBo 与以下基准方法进行比较,
BugLocator:一种基于信息检索(IR)的知名错误定位方法,它考虑了之前已经修复的相似错误。DNNLOC :一个结合了rVSM [21] 和深度学习的模型,同时考虑了错误修复历史和API元素的元数据。NP-CNN:一种基于卷积神经网络(CNN)的方法,利用来自自然语言和编程语言的词汇和结构信息。CG-CNN:一种基于控制流图(CFG)的方法,它捕获额外的结构和功能信息来表示源代码的语义。TRANP-CNN:一种深度迁移模型,用于跨项目的错误定位,通过从源项目和目标项目共同提取可迁移特征。CooBa:一种针对跨项目错误定位的对抗性迁移学习方法,侧重于项目之间共享的公共知识。实现细节。在我们的实验中,我们采用了各方法原始工作中建议的相同设置,并且所有方法都在跨项目的背景下进行评估。在错误报告和代码文件编码器的输出拼接后,我们插入了一个丢弃层[16],其率为0.5。初始学习率设置为0.008,并随着训练步骤的增加而减小。源项目使用32大小的批次,目标项目使用16大小的批次。模型参数 λ1、λ2 和 λ3 分别设置为0.5、0.2和0.3。为了计算准确的平均测量值,我们重复实验10次。遵循Huo等人[9]的工作,我们只使用一个源项目,并执行一对一的跨项目错误定位。例如,如果选择AspectJ作为目标项目,则通过依次将其他三个项目视为源项目,形成总共三个跨项目对。我们认为源项目的所有错误报告和目标项目20%的错误报告都已修复,其相应的错误修复数据用作训练数据。目标项目剩余80%的错误报告未修复,用于测试。为了评估TroBo的性能,使用了两个指标,即Top-K排名和平均精度(MAP),这两个指标在错误定位中广泛用于评估。
3.2 有效性分析
我们提出的模型的有效性通过与所有比较基准在四个项目(12个跨项目任务)上的评估得到验证。实验结果呈现在图2中,每个跨项目任务的最佳性能用“.”标记。横坐标指向不同的任务。例如,“SWT”→“JDT”表示SWT是源项目,JDT是目标项目。第一行和第二行的直方图分别报告了Top-10排名结果和MAP结果。从图2中,我们可以观察到:

图2. 与错误定位模型在Top-10排名和MAP方面的性能比较。
(1) 我们提出的TroBo模型在所有任务上均超越了现有技术水平,无论是在Top-10排名还是MAP指标上。就Top-10值而言,TroBo在JDT上比其最佳竞争对手(即CooBa)高出1.6-4.6%,在AspectJ上高出2.6-4.8%,在SWT上高出1.8-4.9%,在Platform上高出3.0-4.6%。在MAP指标上,TroBo在所有任务上比跨项目错误定位TRANP-CNN平均提高了7.4%。与平均结果相比,TroBo实现了平均Top-10为0.687和MAP为0.373。总的来说,TroBo在包含所有可能的跨项目任务和指标的情况下表现最佳。这些结果表明,我们提出的TroBo模型能够有效解决缺乏足够错误修复数据的项目的错误定位问题。
(2) 传统的错误定位模型在直接用于标签匮乏的项目时效果不佳。我们可以看到,最佳传统错误定位模型CG-CNN的性能在所有任务上仍然明显落后于所有迁移学习模型(即TRANP-CNN、CooBa、TroBo)。类似的结果可以在所有传统模型中找到。例如,CooBa和TRANP-CNN在JDT项目的MAP指标上分别比NP-CNN提高了11.7%和7.6%。这些结果表明,尽管传统模型在训练中使用了源项目的错误修复数据,但它们无法充分利用源项目中的知识。在实践中,确实有必要为标签匮乏的项目构建专门的错误定位技术。
3.3 消融研究
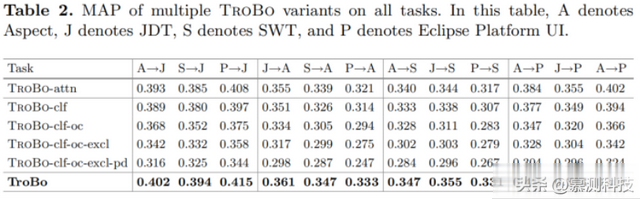
在我们的模型中,我们首先使用注意力机制来自动过滤错误报告中的与错误无关的内容。其次,我们引入对抗性迁移学习来提取源项目和目标项目之间共享的公共特征。最后,我们利用项目感知的分类器和正交性约束来明确区分每个项目的专属和共享特征。为了进一步调查TroBo的重要组件是否有效,我们设计了多个TroBo变体进行评估,包括:(1)TroBo-attn:没有注意力机制的TroBo,(2)TroBo-clf:没有项目感知的分类器的TroBo,(3)TroBo-clf-oc:没有项目感知的分类器和正交性约束的TroBo,(4)TroBo-clf-oc-excl:进一步移除了专属特征提取器,即模型只提取跨项目的共享知识,(5)TroBo-clf-oc-excl-pd:仅保留了共享特征提取器,直接迁移知识而没有项目鉴别器。最终,MAP指标的实验结果在表2中呈现。我们可以观察到,整个TroBo模型在所有任务上都优于其他变体。比较TroBo和TroBo-attn的性能,我们发现注意力机制确实有效于过滤错误报告中的与错误无关的噪声。此外,我们观察到TroBo-clf-oc在所有任务上都优于TroBo-clf-oc-excl。这表明特定项目的专属特征对错误定位是有用的。此外,TroBo、TroBo-clf和TroBo-clf-oc的性能表明,项目感知的分类器和正交性约束在学习专属和共享知识方面起到了关键作用。最后,与TroBo-clf-oc-excl-pd相比,TroBo-clf-oc-excl通过对抗性训练显著提高了性能。结果表明,直接应用迁移学习不能保证提取纯共享知识。
转述:伊高磊
