
午后的咖啡馆里,人们三三两两地聚在一起,有的在讨论着最新的科技动态,有的享受着片刻的宁静。
这时候,邻桌突然传来一阵激烈的讨论声。
“你觉得YOLO还有改进空间吗?”其中一个人问道。
另一个人笑了笑,回答道:“当然有了,你听说过Hyper-YOLO吗?
他们结合了超图计算,简直是颠覆性的变化!”

大多数人可能不太清楚什么是YOLO,更别说Hyper-YOLO了。
但在科技圈,这两个词最近频频出现在讨论的热点中。
那么,Hyper-YOLO到底为什么引起了这么多关注呢?
Hyper-YOLO的创新:混合聚合网络与HyperC2Net的引入Hyper-YOLO作为一种新型的目标检测方法,和传统的YOLO相比,最大的变化在于它引入了混合聚合网络(MANet)和HyperC2Net。
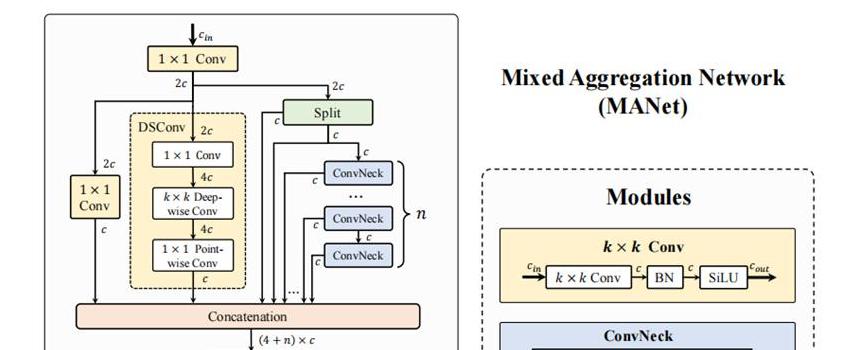
简单来说,MANet提升了特征提取的能力,而HyperC2Net则允许更复杂的跨层和跨位置交互。
什么意思呢?
想象一下,你在一次团队合作中,不仅要和你的直接上下级沟通,还需要跨部门各个层级的交流。
这听起来复杂,但确实能使整个团队更加高效。
就拿日常生活中的例子来说,你买一辆新车。
过去的YOLO模型可能就像一辆基本款的轿车,提供了驱动功能,但很有限。
而Hyper-YOLO就像是高配版,不仅有基本的驾驶功能,还能自动驾驶、夜视、路况预警等等。
这些新功能让你的驾驶体验大大提升,这正是通过混合聚合网络和跨层表征网络带来的革新。
传统YOLO的局限:为什么需要超图计算赋能的HGC-SCS框架众所周知,传统的YOLO在目标检测上已经有了不错的成绩,但它也有明显的局限性,比如在多尺度特征融合上,往往处理得不够完整。
这就像你拍了一张照片,有些细节看不清楚,结果影响整体美感。
而Hyper-YOLO通过引入超图计算,不仅能清晰地看到照片中的每个细节,还能进一步解析它们之间的关系。

这样说来,有一种很贴切的类比。
传统的YOLO就像是一个优秀的厨师,可以做出各种美味的菜肴。
但Hyper-YOLO呢?
它不仅是优秀的厨师,还能精准配对食材的营养成分,让每道菜既美味又健康。
这就是超图计算赋能的HGC-SCS框架的厉害之处,它从多个维度分析特征,进行更高层次的信息融合。
实验证明:Hyper-YOLO在COCO数据集上的优异表现你可能会问,这些革新在实际应用中到底效果如何呢?
根据最近的实验结果,Hyper-YOLO在COCO数据集上的表现令人惊艳。
它不仅显著优于YOLOv8和YOLOv9,还在目标检测的平均精度上提高了12%和9%。
这意味着什么呢?
举个简单的例子,以前你用普通的YOLO模型可能会漏掉一些关键的物体,现在用了Hyper-YOLO,几乎没有遗漏,你甚至可以准确识别到图片中小到细微的物体。
在我们的日常生活应用中,这样的提升也是显而易见的。

想象一下,智慧城市中的监控系统,如果用上Hyper-YOLO,安全隐患的识别会更加精准和高效。
比如,它能更快识别出交通违章行为,从而及时处理,保障道路安全。
结语Hyper-YOLO的创新不仅仅在于技术上的提升,更是为实际应用带来了极大的便利和精准。
这种跨越不同层次和位置的高阶特征交互,为我们的视觉识别技术带来了新的可能性。
就像生活中的各种新技术一样,Hyper-YOLO也是不断前进和创新的结果。

未来,随着Hyper-YOLO的不断发展,我们也期待能看到更多日常生活中的应用场景,从智慧城市,到智能家居,再到医疗影像的精确分析。
让我们一起期待这场由超图计算和视觉目标检测引爆的新变革,也许下一个讨论Hyper-YOLO的人,就会是你和你的朋友!
这样的文章不仅梳理了Hyper-YOLO的技术原理,还通过贴近生活的类比和场景描述,引发读者的思考和讨论。
希望能让更多普通读者了解并关注这项前沿技术。
