Python系列文章加上几个番外篇,已经超过了100篇,基本上把所有Python中需要理解、掌握的常用的语法特性进行了详细的介绍并给出了相应的代码实例。
笔者计划从本文开始,分别结合不同的编程场景需求,介绍不同场景中Python的支持,包括但不限于Python并发编程、Python网络编程、Python数据库编程等。从而能够在Python基本语法掌握的基础上,结合具体场景的支持,编写出更加实用的Python程序。当然在介绍不同场景的Python支持的同时,也会稍微介绍下计算机科学在这些场景中的理论内容,作为配合Python招式的内功心法。
本文作为Python并发编程的第一篇,首先打算从两个概念的辨析入手。本文的主要内容有:
1、CPU是如何执行程序的
2、并发和并行
CPU是如何执行程序的首先还是把大名鼎鼎的“冯诺依曼体系结构”放在这里,当下的计算机体系结构,基本上都是基于冯诺依曼关于“存储程序”的理念来设计的。存储在内存中的,不只是数据,还有要执行的程序。

CPU和内存之间,通过总线进行连接,在不同时钟周期内,总线上传输的可能是数据流、指令流,或者控制流。
我们所编写的程序,在执行之前,会先编译为机器指令,存储到进程中,然后交由CPU进行执行。
CPU在执行每一条指令时,分为3个步骤:
1、取指(Fetch):从内存中取得要执行的下一跳指令。
2、译码(Decode):对指令进行译码,翻译为CPU能够理解的具体操作。
3、执行(Execute):根据指令的译码结果,实际进行指令的执行过程,一般又会有取操作数、驱动ALU进行算术和逻辑运算等步骤。
如果有计算结果需要回写,还要进行回写内存的操作步骤。
为了提高计算机的吞吐率,现代CPU通常采用流水线技术,分阶段并行处理多条指令,不同的CPU模块,是真正在并行工作,同时进行多条指令的不同流水线阶段。

单个CPU的话,依靠流水线技术,已经可以实现多个指令的并行操作。
如果是多个CPU,或者多核CPU,则可以进一步提升指令的并发度。
并发与并行简单了解了CPU执行程序的过程,在真正开始Python的并发编程之前,还有必要辨析一下并发和并行这两个容易混淆的概念,从而更加清晰的理解后续Python中并发编程的内部细节。
1、并发(Concurrency)
并发是指在同一时间段内处理多个任务,任务之间可以交替执行,但不一定是同时执行。

并发,对CPU个数或者CPU核心数并没有要求,哪怕只有一个单核CPU,也是可以实现并发的。操作系统通过各种调度算法,实现CPU的时间片的分时复用。只要时间片切分的足够小,多个任务在极小的时间段内各自独占CPU,给用户的感知则是多个任务似乎在同时运行中。
2、并行(Parallelism)
并行是指在同一时刻真正地同时执行多个任务,通常需要多个处理器或者多核处理器来实现。
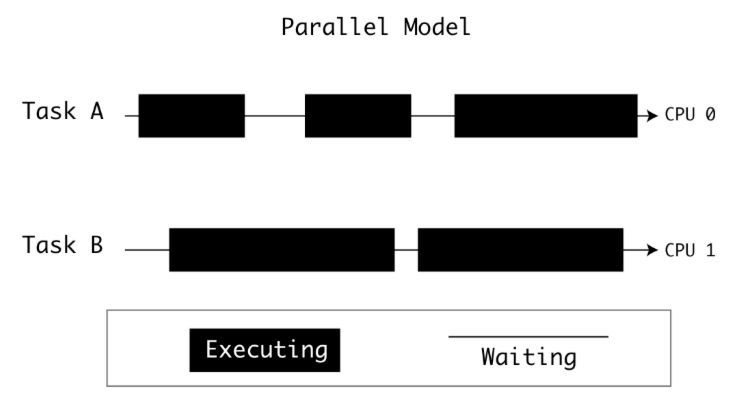
并行依赖于硬件的支持,并行的几个任务各自独占一个CPU或者CPU核心,实现同一时刻的同时运行。
从概念上来看,并发是一个更加宽泛的概念,并行是并发的一种特殊形态。
我们后续进行并发编程时,根据采用的并发模型,可能只是做到分时复用的并发,也可能真正做到了并行,需要具体分析来看。
所以,有些初学者以为程序执行太慢,想通过并发编程来提高执行效率,如果不了解并发和并行的区别,可能反而执行效率更低了。毕竟,分时复用的并发,在任务资源你的申请、任务切换的上下文环境的保存与恢复等也有一定量的时间开销。
总结本文简单介绍了CPU执行程序的过程,对比了并发和并行这两个容易混淆的概念,在后续的并发编程中,需要始终注意到通过并发编程,不一定能够提升程序的执行效率,还是需要具体情况具体分析。
感谢您的拨冗阅读,希望对您有所帮助。
