本文的主要作者来自南洋理工大学 S-Lab、腾讯公司和清华大学智能视觉实验室。本文的共同第一作者为南洋理工大学博士生董宇昊和清华大学自动化系博士生刘祖炎,主要研究方向为多模态模型。本文的通讯作者为南洋理工大学助理教授刘子纬和腾讯高级研究员饶永铭。
大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。尽管人们为改进语言模型的推理做出了种种努力,但在多模态视觉语言任务中,高质量的长链推理数据以及优化的训练流程仍未得到充分的探索。
为了解决上述问题,来自南洋理工大学、腾讯、清华大学的研究者们提出一种能够进行长链视觉推理的多模态模型 Insight-V。Insight-V 提供了 1)针对复杂的多模态任务,可扩展地生成冗长且可靠的推理数据;2)建立有效的训练流程,以增强多模态语言模型的推理能力。
Insight-V 的核心创新点包括:1)一个用于生成长链、高质量推理数据的可扩展的数据生成流程;2)一个将视觉推理任务分解为推理和总结的多智能体系统;3)一个用于增强视觉推理能力的两阶段训练流程。这些设计赋予了 Insight-V 较强的视觉推理能力。

论文:https://arxiv.org/abs/2411.14432
代码:https://github.com/dongyh20/Insight-V
模型:https://huggingface.co/THUdyh/Insight-V-Reason
1. 介绍
现有的研究通过长链推理来提升语言模型(LLMs)的推理能力,已经取得了显著进展,这在很大程度上得益于结构化、高质量数据的可获取性以及成熟的训练流程。相比之下,多模态语言模型(MLLMs)进行长链视觉推理仍然是一项重大挑战,主要原因是缺乏大规模、高质量的数据集以及高效有效的训练策略。与纯文本数据相比,视觉推理数据不仅收集成本更高,而且由于缺乏有效的数据生成流程,还需要大量人力来进行详细标注和验证。此外,当前的多模态语言模型无法有效利用视觉线索进行精确的视觉推理,需要一种有效的训练程序,使多模态语言模型在保持清晰视觉感知的同时能够进行详细推理。
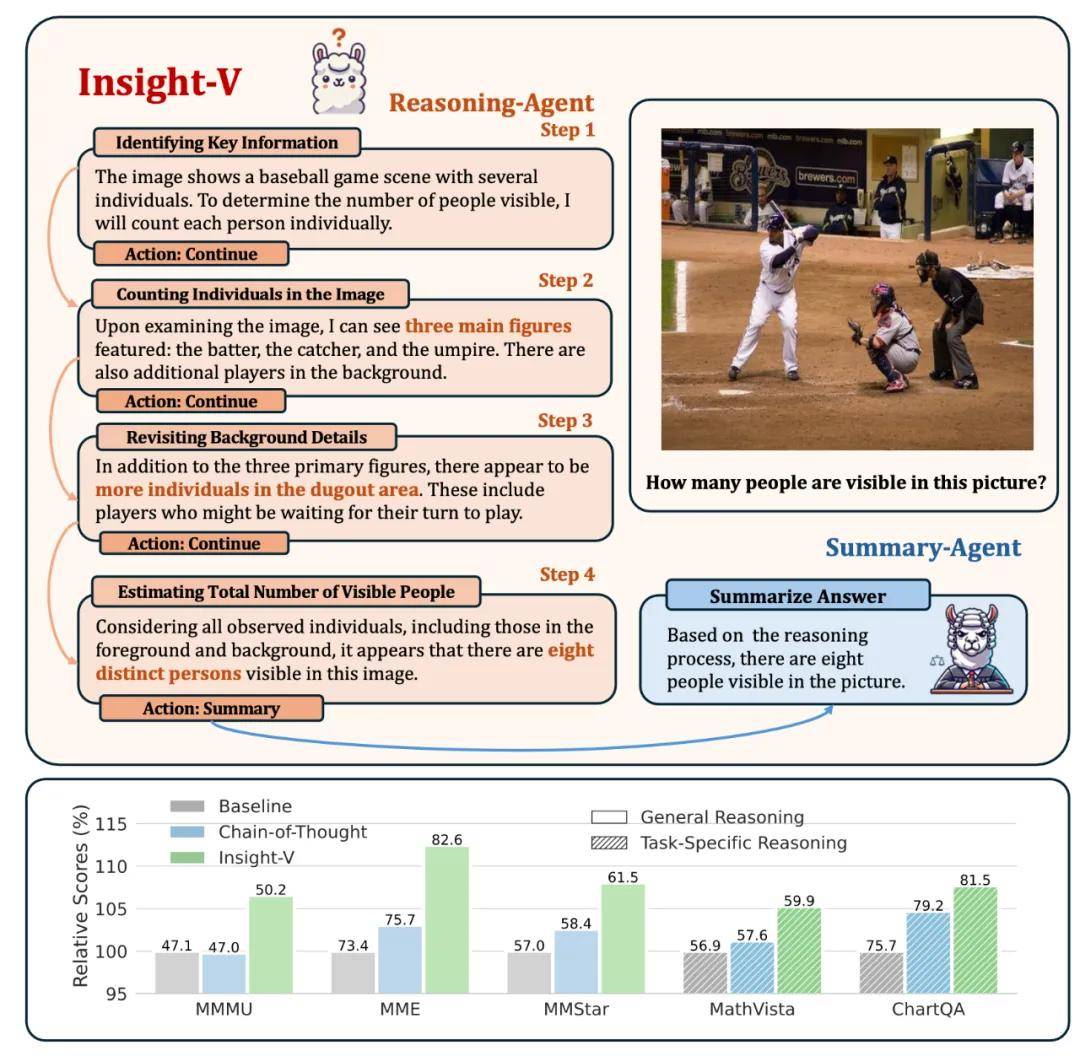
图 1:Insight-V 方法展示。
为了解决以上挑战,本文提出了一个视觉推理的多模态系统 Insight-V,能够实现结构化的长链视觉推理。如图 1 所示,Insight-V 由两个智能体组成,一个专门负责推理,另一个负责总结,这使得它在各类视觉推理基准测试中的性能有了显著提升。
Insight-V 的主要贡献包括:
一个用于生成长链、高质量推理数据的可扩展的数据生成流程。通过利用已有的模型构建数据生成流程,从而提供丰富的,可扩展的视觉推理训练数据。
一个将视觉推理任务分解为推理和总结的多智能体系统。通过将视觉任务分解为推理和总结,并利用不同的模型来分别解决不同的任务,来提升视觉推理能力。
一个用于增强视觉推理能力的两阶段训练流程,从而使 Insight-V 能够在视觉推理评测集上取得优异的性能。
我们提供了 Insight-V 的模型权重,在视觉推理任务上表现出色,在 7B 规模下取得了综合最好的结果,在部分数据集超过最先进的综合模型和商业模型,为多模态视觉推理的发展提供了一个值得探索的方向。
2. 方法概览
结构化推理数据构建

图 2:结构化数据构建。
现有的研究已经探索了将推理能力融入多模态大型语言模型(MLLMs)中。然而,训练 MLLMs 具备强大的推理技能仍然是一个相当大的挑战,尤其是由于数据方面的限制。为了解决这一问题,我们介绍了提出的数据生成流程,该流程旨在通过渐进式生成过程和多粒度评估来生成高质量的长链推理数据。如图 2 所示,这种可扩展的方法使我们能够生成高质量的数据,从而有效地提升模型的推理能力。
渐进式长链推理数据生成。我们通过调用能力强大的多模态综合模型,来收集单步推理结果。在每一步推理结束之后,模型根据历史的推理结果来生成针对下一轮推理的动作,如果动作为‘继续推理’,下一步模型继续执行单步推理;如果动作为‘总结’,下一步模型根据历史推理内容总结得出答案。
多粒度评估。我们通过两个步骤来对生成的推理数据进行评估。首先,我们直接使用真实答案来对推理数据进行过滤,过滤掉最终答案错误的数据。之后,我们使用一个推理步骤打分模型,来针对推理数据的质量进行打分,将推理数据分为不同质量的子集,以供最后训练数据集的构建。
模型设计
推理模型。我们提出了一种专门的推理智能体,其旨在针对输入查询生成一个详细的、逐步推进的推理过程。我们通过为每个问题选取得分最高的推理路径来构建推理数据集。在基于该数据集进行训练之后,模型转变为一个具有更强推理能力的推理智能体,使其能够生成更详细、结构化的推理过程。
总结模型。我们开发了一种对推理路径中的不准确之处具有较强适应性的总结模型,该模型可根据需要有选择性地纳入或忽略某些元素。这种方法在最大程度发挥推理模型效能的同时,将引入误导性信息的风险降至最低。我们利用所收集的数据集来完成总结任务,该数据集由两类数据组成:具有最优推理过程的数据和具有有缺陷推理过程的数据。此外,为了保留原有的多模态能力,我们用标准问答数据对数据集进行补充,以维持总结智能体在直接问答方面的性能。

图 3:训练流程。
训练策略
Insight-V 的训练策略简单直接。我们从一个已经训练好的多模态模型出发,利用这个模型的权重来初始化 Insight-V 当中的两个模型。
第一阶段,我们进行多智能体系统的监督微调。对于推理模型,我们利用精心整理的推理数据集来培养逐步推理的能力。对于总结模型,我们按照上文所述构建了一个数据集,并从用于基础模型的数据集中抽取了大约一百万对通用的图文组合,以保留其原有的视觉感知能力。
在第二阶段,我们利用强化学习算法来进一步提升模型的推理能力。我们使用迭代式直接偏好优化(Iterative DPO)。通过进行多轮直接偏好优化(DPO)训练和抽样,这种方法能使该模型在训练期间更好地模拟在线环境,从而进一步提升其性能。
3. 实验结果
视觉推理
我们在 7 个基准测试上开展了评估实验,涵盖了通用推理和特定任务推理评估。当应用于 LLaVA-NeXT 和我们的基线模型时,Insight-V 展现出了显著的有效性和通用性,大幅超越了其他最先进的大型语言模型(MLLMs)。在 MMStar 数据集中,Oryx 取得 61.5% 的平均准确率。在 MME 数据集上取得了 2312 的总分,并且在 MME 的感知和认知子任务上都取得了先进的结果。针对 7 个数据集的平均结果,Insight-V 表现出色,超越了一系列先进的模型。

基础视觉感知
为了更进一步测试 Insight-V 的通用性,我们在一些侧重评估模型基础视觉感知能力的数据集上进行了测试。结果表明,InsightV 在不影响一般视觉感知能力的情况下提升了推理能力,甚至在对感知能力要求更高的基准测试上也实现了性能提升。当 Insight-V 与 LLaVA-NeXT 模型结合时,在 TextVQA,DocVQA,OCRBench,AI2D 等测试集上都有显著的性能提升,当与我们构建的更强的基础模型结合时,在这些 benchmark 上也表现出了更好的结果。

分析实验
多智能体系统的有效性。针对 Insight-V 的设计,我们与其他可能的设计选择进行了对比,包括直接进行微调、多轮对话监督、只训练总结模型。结果显示,多智能体设计的表现优于其他配置,突出了推理和总结分解的关键作用。

数据 Scaling Law 实验。我们研究了数据扩展对于 Insight-V 的影响,尤其是对于推理模型的效果。结果表明,随着推理模型训练数据的扩展,推理模型的性能得到了显著的提升。推理模型得益于数据扩展,能为总结模型提供更有价值的见解。

强化学习算法的效果。我们探究了不同的强化学习策略对于推理模型效果的影响。我们对比了使用 RLAIF 数据进行训练,直接进行 DPO 以及 Insight-V 的多轮迭代式 DPO。结果显示,相比其他方法,迭代直接偏好优化(Iterative DPO)逐步增强了模型的推理能力,从而带来了性能的提升。

4. 案例分析

我们对 Insight-V 与思维链(Chain-of-Thought)以及通过直接监督微调学习进行了定性比较。对于 Insight-V 系统而言,其推理智能体能够提供一个更加连贯且结构化的推理过程,从而引导总结智能体得出正确答案;然而,其他方法在面对复杂推理任务时会显得吃力,无法解决这类具有挑战性的问题。
5. 总结
在本文中,我们介绍了 Insight-V,这是一种新颖的系统,它将用于长链、高质量推理数据的可扩展数据生成系统与有效的多智能体训练系统相结合,以增强多模态语言模型(MLLMs)的推理能力。通过开发该系统,我们提供了一种旨在提高推理性能的可扩展模型训练方法。我们在各种基准测试中的广泛评估证明了我们这种方法的有效性,为赋予多模态语言模型更强的推理能力铺平了道路。
