2025年初,中国迎来属于自己的“ChatGPT时刻”。
DeepSeek-R1模型的卓越能力引发了广泛关注,从科技圣地硅谷到国内各个角落,不分年龄、职业,从科技创业者到各行各业的从业者,无论是新手小白还是技术大咖,无不沉浸在对DeepSeek的探索与体验之中。面对“服务器繁忙”的挑战,用户们更是解锁了DeepSeek的多样“玩法”:
通过Web/APP端,普通用户只需简单登录即可免费享受服务,随时随地体验AI的魅力;资深玩家则可申请性价比超高的API,以OpenAI o1价格3%的优惠(每百万输出tokens仅需16元)自由定制需求;而对于追求私密与控制的极客玩家,本地部署方案将DeepSeek安装在个人电脑或服务器,享受完全掌控的丝滑体验,无惧官方宕机。

本地部署需要配置哪些硬件?
相较于那些只能等待DeepSeek“服务器繁忙”得到缓解的用户,已经完成DeepSeek本地部署的人们早已抢先一步,开始享受着大模型带来的种种优势与便利。对于普通用户而言,想要实现这一部署,则需具备一定配置的硬件支持,这具体涵盖了高性能处理器以确保计算效率、充足的内存资源以保障多任务处理流畅,以及足够的存储空间来容纳庞大的模型数据及运行期间的临时数据。

仅供参考



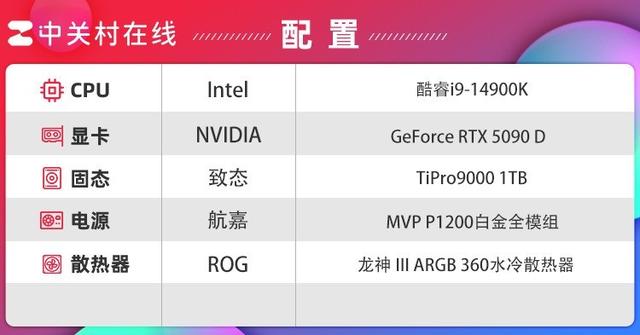
简单两步搞定DeepSeek本地部署

其次,将DeepSeek模型下载到本地。大家可从多个网站或社区下载DeepSeek-R1大模型,选择时需考虑自身需求。更为便捷的是,LM Studio软件内置了DeepSeek模型下载功能。只需点击主界面左侧的放大镜图标进入大模型搜索页,输入“DeepSeek”即可检索到多个不同参数规模的大模型。模型参数越大,内容越丰富且准确,但对硬件要求也越高。随后,直接选取并下载所需的DeepSeek模型,下载完成后,即可在本地环境中运行DeepSeek。


硬件配置给力!畅享本地DeepSeek!


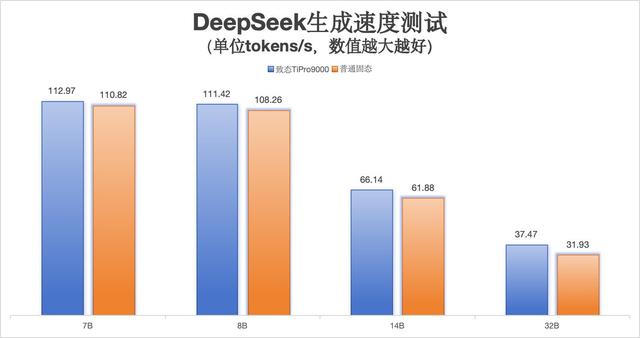
在使用同样的测试场景下,普通硬盘搭配索泰GEFORCE RTX 5090 D测试结果显示,7B版本DeepSeek大模型的生成速度达到110.82 tokens/s;8B版本生成速度为108.26 tokens/s;14B版本则为61.88 tokens/s;32B版本达到31.93 tokens/s。其速度低于基于致态TiPro9000固态硬盘搭建的测试环境,并且随着参数规模的增加,生成速度差距持续拉大。值得注意的是,本次测试主要为推理测试,而在训练阶段,大模型需要海量的数据进行喂养,不仅对容量提出考验,还对读写能力提出新要求。
写在最后
在数字化时代,数据已成为核心生产要素,而存储则是其不可或缺的基石。面对海量数据的存储挑战,如何有效承载这些数据成为亟待解决的问题。随着AI时代的临近,各式各样的AI应用将频繁访问数据,这对硬盘的读写性能提出了更高要求。因此,具备大容量、高速读写能力以及高度安全可靠的存储设备将成为市场的首选。
(9515026)
