LTM: Scalable and Black-box Similarity-based Test Suite Minimization based on Language Models
Rongqi Pan, Taher A. Ghaleb, and Lionel C. Briand, Fellow, IEEE
引用
Pan, Rongqi, Taher A. Ghaleb, and Lionel Briand. "LTM: Scalable and Black-box Similarity-based Test Suite Minimization based on Language Models." arXiv preprint arXiv:2304.01397 (2023).
论文:https://arxiv.org/abs/2304.01397
摘要
本文提出了名为LTM(Language model-based Test suite Minimization)的新方法,用于软件测试中的测试用例集最小化。LTM利用大型语言模型(LLMs)提取测试代码的嵌入,并使用相似性度量来指导遗传算法(GA)搜索最佳的最小化测试用例集。实验结果表明,LTM在故障检测率、测试时间节省和整体最小化时间方面优于现有方法。该工作的主要贡献包括更具可扩展性的TSM方法、基于LLMs的信息丰富的相似性度量以及对黑盒TSM方法的全面分析。
1 引言
软件测试是一项必不可少的活动,它通过检测软件版本中的 错误来保证高质量的软件系统。当测试用例集很大时,特别是对于大型代码库,运行测试用例集中所有测试用例的可伸缩 性很快成为一个关键问题,因为在工业环境中进行测试的时间和资源是有限的。这个问题尤其严重,因为测试用例集的 大小往往随着软件演化而增加,这使得不可能在分配测试预算的情况下为每个代码更改运行所有测试用例。为了解决这个问题,测试用例集最小化(test suite minimization, TSM)被广泛采用,以在保持其错误检测能力的同时使测试过程更加高效。与测试用例选择 (选择与代码更改相关的测试用例子集)和测试用例优先排序 (根据错误检测能力等某些特征对测试用例进行排序)相比,测试用例集最小化的目标是消除不太可能检测不同错误的冗余或相似的测试用例。尽管存在各种TSM方法,但它们中的大多数要么依赖 于代码覆盖率信息(白盒),这需要访问软件生产代码,要么依赖于基于模型的特性,例如UML状态机测试的转换覆盖率。测试工程师并不总是可以访问这些信息,此外,收集代码覆盖率信息是昂贵的,并可能导致大型软件系统的可伸缩性问题。Crucani等人和Pan等人通过提出仅依赖于测试用例源代码(黑盒)的TSM方法解决了这个问题。基于聚类算法的FAST-R算法已经被证明比白盒方法更有效,但取得了相对较低的错误检测率。ATM算法基于测试用例相似度和进化搜索,在实际可接受的时间范围内实现了较高的错误检测率。由于测试用例集最小化是在主要软件版本上执行的,而不是在每次代码更改时执行测试用例选择和优先级排序,因此在许多实际情况下,ATM比FAST-R提供了更好的权衡。然而,ATM对于大型软件系统仍然存在可扩展性问题,因为它的总最小化时间(准备时间和搜索时间的总和)随着测试用例集规模的增加而迅速增加。对ATM算法最小化时间的分析表明,相似性度量是限制 其可扩展性的主要因素,原因在于:
(1)计算相似性代价昂贵,占最小化时间的41.20%;
(2)相似性度量影响搜索的收敛性和速度。这促使我们研究既能更有效地计算,又能提供更多信息来指导搜索的相似性度量方法。
本文提出LTM(Language model-based Test suite Minimization),一种可扩展的、基于黑盒相似性的TSM方法,基于预训练大型语言模型(LLMs)和基于向量的相似性度量,据我们所知,这是LLMs在TSM上下文中的第一个应用。LTM使用测试用例的源代码(Java测试方法),不需要任何预处理,作为三个可选的预训练语言模型的输入:CodeBERT,GraphCodeBERT和UniXcoder,以提取测试方法嵌入。考虑到测试用例多样性与故障检测呈正相关,LTM采用两种相似度度量:余弦相似度和欧氏距离来计算提取的嵌入之间的相似度。使用计算的相似度分数,LTM采用遗传算法(GA)来最小化测试用例集,该算法为给定的测试预算搜索测试用例集的最优子集。我们使用用于评估ATM(DEFECTS4J)的相同数据集评估LTM,遵循类似的实验设计,并使用相同的有效性和效率评估指标:故障检测率(FDR)和最小化时间(MT),此外,考虑到测试用例执行时间的潜在变化,仅基于它们的测试用例数量评估最小化的测试用例集可能并不总是准确的。因此,我们使用一个额外的指标来扩展我们对最小化测试用例集的评估:时间节约率(TSR)。然后,我们通过综合考虑效能和效率来确定LTM的最佳配置,并将其与ATM的最佳两种配置进行比较。
具体来说,本文解决了以下研究问题。
RQ1:如何LTM执行不同配置下的测试用例集最小化?LTM为50%最小化预算(即,在最小化的测试用例集中保留的测试用例的百分比)实现了高FDR结果(在所有配置中0.80的总体平均FDR)。LTM的最佳配置是UniXcoder在考虑有效性(平均0.84FDR)和效率(平均26分钟)时使用余弦相似度,这也实现了更大的时间约率(平均TSR的40.38%)。RQ2:怎么使得LTM和ATM相比?LTM的最佳配置通过实现显著更高的FDR结果(平均为0.84vs0.81)而优于ATM,更重要的是,在准备时间(最多快两个数量级)和搜索时间(快一个数量级)方面,运行速度比ATM快得多(平均为26.73分钟vs72.75分钟)。总体而言,本工作的贡献如下:
一种可扩展的黑盒TSM方法,它超越了最先进的(SOTA)方法,具有更高的故障检测能力。利用为编程语言预训练的大型语言模型的信息量更大的相似性度量。它们有效地指导搜索过程,从而加速收敛,以获得更高的故障检测能力。对效率和效果进行了全面的对比分析基于涉及16个Java项目的661个版本的大规模测试用例集最小化实验的黑盒TSM方法,对替代方法的性能产生了有价值的见解。总的来说,实验花费了大约45天的日历时间,相当于在一个拥有83,216可用CPU内核的集群上进行了14年的计算。2 技术介绍
LTM依赖于语言模型来计算测试代码相似性,并允许使用进化搜索来最小化。我们的目标是找到一种黑盒解决方案,在可伸缩性和有效性方面,比最新的最先进(SOTA)方法(即ATM)实现更好的权衡。ATM虽然具有较高的错误检测率,但在可扩展性方面存在局限性,即测试用例向ASTs的转换以及基于树的相似度计算耗时,难以应用于大型软件系统。与ATM类似,LTM也是一种基于相似性的方法,其运行前提是测试用例集多样性与其故障检测能力之间存在正相关关系。我们的目标是找到一种信息量更大的相似性度量,以更好地指导搜索算法,帮助它更快地收敛到更高的故障检测能力,从而减少搜索时间。为了实现这一目标,采用了预训练语言模型来生成代码嵌入,并将其作为衡量测试用例对之间相似性的基础。语言模型能够根据测试用例代码的语法和语义捕获模式,而不需要预处理或特征提取,使其成为我们的上下文中更合适的替代方案。
图1概述了LTM最小化测试用例集的主要步骤。关于前两个步骤,我们描述了如何标记测试用例的源代码,然后使用语言模型提取嵌入。然后,我们描述了我用于测量这些嵌入之间相似性的算法(余弦相似度和欧氏距离)。最后,描述了以相似度作为适应度来最小化测试用例集的搜索算法(遗传算法)。
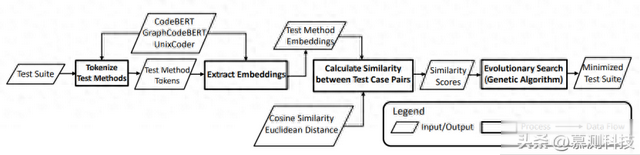
图1 LTM执行测试用例集最小化的主要步骤
2.1 标记化测试方法
语言模型将测试代码片段(方法)作为标记序列处理,并使用字节对编码(BPE)对其进行分割,这是一种子词分割算法,将单词分割为子词序列。这使得语言模型能够更好地处理词汇表之外的单词,例如方法名和变量名。例如,标记赋予器将方法名测试克隆分割为G˙test(其中G˙表示一个空格)、Cl和控制,因为测试克隆单词在词汇表中不存在,因此被分割为这三个子单词。
CodeBERT和GraphCodeBERT分别在每个标记序列的开始和结束处添加两个特殊标记,即[CLS]和[SEP]。CLS标记是一个特殊标记,表示整个输入序列,而[SEP]标记是一个分隔符标记,表示序列的结束。总之,每个测试方法都表示为[CLS],c1,c2,...,cm,[SEP],其中ci表示ith代码令牌,m是代码令牌的总数。对于UniXcoder,除了[CLS]和[SEP]标记之外,还在输入的开头添加了一个额外的特殊标记([Enc]、[Dec]或[E2D]),分别表示模型的预训练模式为仅编码器模式、仅解码器模式或编码器-解码器模式。这些模式在预训练期间的模型架构和训练任务方面有所不同,从而支持各种下游任务。我们使用仅编码器模式来生成上下文化的代码嵌入,因为与解码器相关的模式用于代码生成。因此,UniXcoder的最终输入表示为[CLS],[Enc],[SEP],c1,c2,...,cm,[SEP]。在预训练期间,对于上述所有语言模型,每个标记都被映射到包含该标记的语义和上下文信息的768维向量表示。
2.2 生成测试方法嵌入
测试方法嵌入是测试方法的数值向量表示,从源代码捕获语义和上下文信息。CodeBERT基于一个名为CodeSearchNet[28]的大型语料库预训练代码表示,该语料库包含六种编程语言的自然语言(例如代码注释)和源代码。其后续模型(GraphCodeBERT和UniXcoder)在预训练期间利用数据流信息,分别捕获输入代码片段中的变量和源代码的ast之间的关系,以增强代码表示。CodeBERT采用了一个多层双向Transformer作为模型架构,以帮助模型从整个输入序列中捕获每个token的上下文和位置信息。GraphCodeBERT使用图引导的掩码注意力函数扩展了这种架构,以帮助模型编码基于图的数据流信息。另一方面,UniXcoder基于多层Transformer,前缀表示模型的预训练模式。LTM采用的纯编码器模式的模型架构允许模型为每个标记学习整个输入序列的上下文信息。
在预训练期间,CodeBERT采用了掩码语言建模(MLM),这允许模型从输入序列中预测掩码标记,以及是否在给定序列中随机替换标记。这两个任务帮助模型生成包含更准确上下文信息的代码嵌入,考虑到标记在源代码输入中的位置。GraphCodeBERT还将MLM用于两个额外的任务:边缘预测和节点对齐。边预测允许模型预测数据流图中给定变量的哪些边(表示变量之间的依赖关系)被屏蔽了。节点对齐允许模型预测哪个代码令牌与数据流图中的给定变量相关。这两个任务利用数据流信息进一步增强了代码表示。UniXcoder还将MLM任务用于仅编码器模式,并进一步学习测试方法嵌入,首先通过取所有token嵌入的平均值(即均值池化)生成,然后通过利用多模态对比学习和跨模态生成进一步训练,这都利用AST和代码注释来进一步增强测试方法嵌入。多模态对比学习为相同的输入生成不同的嵌入,但具有不同的dropout mask,这允许模型使用其他生成的嵌入来预测原始嵌入。该任务帮助模型更好地区分不同的方法嵌入,从而可以更好地处理下游任务,例如测试方法相似性分析。跨模态生成为输入测试方法生成代码注释。这有助于模型将代码注释中描述代码功能的语义信息融合到测试方法嵌入中。
对于LTM使用CodeBERT和GraphCodeBERT,我们使用对应于[CLS]标记的嵌入作为测试方法嵌入,因为它聚合了该方法的所有标记的信息。对于LTM使用UniXcoder,我们使用对应于每个测试方法的预训练测试方法嵌入。
2.3 测试方法嵌入的相似性度量
LTM使用两种相似度计算测试方法嵌入之间的相似度:余弦相似度和欧氏距离。它们从不同的方面衡量测试方法嵌入之间 的相似性:余弦相似性衡量两个向量之间的角度,而欧氏距离 计算它们之间的直线距离。
余弦相似度。这是两个向量之间的相似性度量,基于它们之间夹角的余弦,即向量的点积除以它们长度的乘积,计算方法如下:

其中T1和T2分别表示测试用例T1和T2的嵌入。余弦相似度的取值范围为−1 ~1。余弦相似度的值越 大,说明两个测试用例越相似。为了限定0和1之间的余弦相似度的值,我们将其归一化如下:

欧氏距离。这是一种基于两个向量对应元素差值平方和的平方根的相似性度量,计算方法如下:

其中t1i和t2i分别是嵌入T1和T2的i th元素。m是每个嵌入中的元素总数(768)。
欧氏距离的取值范围为0 ~。欧氏距离的值越高,两个测试用例的相似度越小。为了限定0和1之间的欧氏距离并获得相似性度量,我们将距离归一化如下:

我们使用Scipy Python库中的‘pdist ‘函数,该函数对大 型数据集进行两两计算。‘pdist ‘采用高度优化的C代码来 提高基于向量数据的相似度计算的效率,并将输出存储在一个压缩的矩阵中,这进一步减少了所需的内存资源。
2.4 基于搜索的测试用例集最小化
考虑到测试用例集最小化是一个NP-hard问题,它可以使用元启发式搜索算法有效地解决,这有助于找到可行的、接近最优的解决方案(在我们的上下文中,包含给定预算的不同测试用例的最小化测试用例集)。对于适应度函数,我们使用相似度得分的最大平方之和(即归一化余弦相似度和归一化欧氏距离),如下所示:

其中Mn是大小为n的最小化测试用例集,Sim(ti,tj)是测试用例对ti和tj的归一化相似度分数。虽然搜索也可以通过各种方式进行优化,我们计划在未来进一步研究,但我们选择使用与ATM相同的算法和实验设置,而专注于评估基于语言模型的相似性度量的性能。具体来说,我们遵循了与ATM相同的发布指南2用于GA搜索超参数,使用的种群大小为100,突变率为0.01,和交叉率为0.90。重复遗传进化过程,直至适应度值改进小于0.0025。
3 实验评估
3.1 实验设置
不同的语言模型和相似性度量的组合,总共有六种配置(三种不同的llm和两种相似性度量),使用与ATM相同的实验设计和数据集。我们在1,340节点的集群上进行了实验,每个节点有83216个可用的CPU内核,每个节点有一个2xAMDRome7532,2.40GHzCPU,256McacheL3,249GBRAM,运行CentOS7。我们将每个Java项目版本视为一个独立的主题,并在数据集中的所有Java项目版本(共661)上进行了实验,以增加实验评估的实例数量,从而增强了我们结论的可靠性。每种TSM方法都在每个项目版本上执行,并运行10次数来考虑随机因素并得出统计上有效的结论,使用三种最小化预算(25%、50%和75%),对于每种配置,总共运行19,830(661Java项目版本×10每个版本×3最小化预算)。总的来说,实验花费了大约45天的日历时间,相当于14年的计算时间。从效能和效率两方面确定了LTM的最佳配置,并将其与ATM的两种最佳配置进行了比较。
3.1.1Baseline approach(ATM)
我们将LTM与ATM进行了比较,ATM是一种基于相似性、基于搜索的仅依赖于测试用例源代码的测试用例集最小化方法。ATM对测试代码进行预处理,删除与测试逻辑无关的信息,然后将测试代码转换为ASTs。ATM计算4种不同的基于树的测试用例相似度度量:自上而下相似度、自下而上相似度、合并相似度和树编辑距离相似度。然后采用基于相似度得分的搜索算法(GA和NSGA-II)去除冗余测试用例,寻找最优测试用例子集;与SOTA测试用例集最小化方法FAST-R相比,利用GA和组合相似度,ATM在有效性和效率方面取得了更好的权衡。然而,它受到可伸缩性问题的影响,例如,为最大的测试用例集最小化4k测试用例花费了超过10小时。这促使我们在故障检测能力,更重要的是最小化时间方面,将LTM与ATM进行比较。我们的目标是评估LTM是否可以比ATM更可扩展,同时实现可比甚至更高的故障检测能力。我们用遗传算法(ATM/combined)和树编辑距离(ATM/Tree Edit Distance)对LTM与ATM的两种最佳配置进行了比较。考虑效果与效率的权衡,前者是最佳配置;后者具有更高的故障检测能力,但在总最小化时间上比前者更耗时。我们进一步评估了为LTM和ATM的每个最小化测试用例集所节省的测试时间。我们依赖于作者提供的ATM3的公开可用复制包。
3.1.2 数据集
我们使用与ATM相同的数据集进行了实验,以评估其有效性,更重要的是,LTM与ATM相比的可扩展性。该数据集由16Java项目组成,这些项目是从DEFECTS4J4收集的,这是一个著名的数据集,提供了从真实的、开源的Java项目中提取的真实和可重现的错误,以支持软件测试研究。每个项目都有许多错误版本,导致项目版本总数为661。每个版本都包含一个真实的错误,它存在于生产代码中,会导致一个或多个测试用例失败。值得注意的是,目前还没有公开可用的数据集可以为每个版本提供多个真实错误,因为自动建立错误和测试用例失败之间的明确联系将具有挑战性。表1列出了每个项目的特征。KLoc方面的项目大小从2到92KLoc,相应的测试大小从4到73KLoc。错误版本的数量在项目之间从4到112,每个版本的平均测试用例数量在项目之间从152到3918。项目大小和测试大小(即代码行数)是通过使用CLOC5工具分析每个项目的最新版本来提取的。
表1 16 Java项目的总结

3.1.3 评价指标
采用了与ATM相同的评价指标,特别是错误检测率和最小化总时间,并实现了最小化测试用例集的测试时间节省。故障检测率(FDR)。我们使用FDR来评估LTM与ATM相比的有效性。假设每个项目版本包含一个故障,每个版本对应的故障检测率可以是1(故障检测到)或0(故障未检测到)。因此,我们考虑每个项目的所有版本,计算每个项目的错误检测率,如下所示:

其中m表示项目的总版本数。对于项目版本i,如果在最小化的测试用例集中包含至少一个失败的测试用例,则fi等于1,表明检测到该版本的错误,否则为0。例如,在Chart项目中,总共有26个错误版本,如果最小化的测试用例集在21个版本中检测到错误,而在5版本中没有检测到,那么FDR将被计算为21/26,得到的FDR为0.81。请注意,我们为每个版本运行了总共10次实验,以减少随机性。因此,每个项目的最终FDR是通过取整个10运行的平均FDR结果获得的。总最小化时间(mt)。
我们通过计算(1)准备时间,包括加载语言模型、标记化测试用例代码、提取测试方法嵌入和计算所有测试用例对之间的相似度分数所需的时间,以及(2)搜索时间,这是运行GA所需的时间,来评估LTM与ATM的效率。节省时间率(TSR)。我们使用TSR来量化由于测试用例集最小化而实现的测试时间节省。重要的是要注意,测试执行时间的减少可能并不与测试用例集大小的减少成正比,因为执行单个测试方法所需的时间可能不同。我们为每个项目版本(总共661版本)运行测试用例集,并使用DEFECTS4J基础设施收集每个测试方法的执行时间。然后,我们计算每个最小化测试用例集的TSR,如下所示:
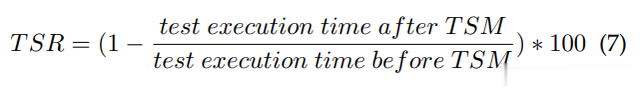
Fisher精确检验。我们使用Fisher精确检验,一种非参数统计假设检验,来评估备选LTM和ATM配置之间检测到的故障比例的差异是否显著。
3.2 结果分析
如图2与表2分析得到LTM获得了较高的FDR结果(0.80,on)平均(跨配置),最小化50%预算。UniXcoder/Cosine是最好的LTM配置当考虑有效性(平均 年龄0.84FDR)和效率(平均26.73分钟)时TSR平均值为40.38%。

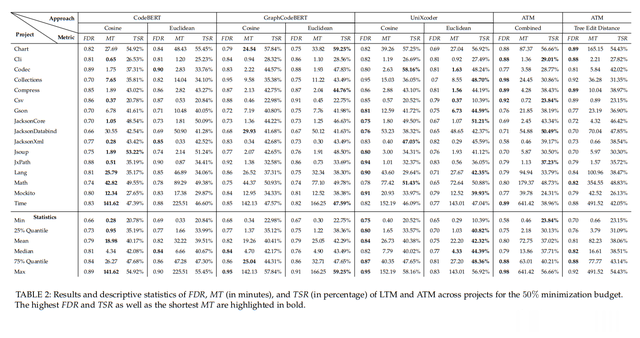
从图3分析可知:LTM优于ATM,实现了FDR结果显著提高(0.84vs0.81)平均)。然而,LTM的主要好处是运行速度比ATM快得多(26.73分钟vs平均72.75分钟)时间(最多快两个数量级)和搜索时间(快一个数量级)。考虑到急性在工业环境中遇到的可伸缩性问题,这个结果是具有高度的实际重要性。

图3:针对LTM(UniXcoder/Cosine)和ATM的测试用例和MT数量、准备时间和搜索时间(以分钟为单位)的散点图,跨50%最小化预算的所有项目版本(总共661版本)
3.3 结论
文中提出了LTM,一种基于预训练语言模型的可扩展的基于黑盒相似性的测试用例集最小化方法。我们研究了三个替代语言模型——CodeBERT、GraphCodeBERT和UniXcoder——来提取测试方法嵌入和两个相似度度量(即余弦相似度和欧氏距离),用于基于这些嵌入的相似度计算。采用遗传算法(GeneticAlgorithm,GA)寻找测试用例集的最优子集,以这些相似性度量作为适应度指导搜索。我们在一个由16 Java项目和从DEFECTS4J收集的661版本组成的大型数据集上评估了可选LTM配置的性能。我们使用故障检测率(FDR)、最小化时间(MT)和时间节约率(TSR)作为评估指标来评估LTM的有效性和效率。我们确定了LTM的最佳配置,并将其与ATM进行了比较,ATM是一种最近的黑盒TSM方法,在有效性和效率方面取得了比替代SOTATSM方法(FAST-R)更好的权衡。结果表明,最好的LTM配置(即UniXcoder/Cosine)通过实现显著更高的FDR结果(平均0.84与0.81)优于ATM的最佳两种配置,更重要的是,在准备时间(最多快两个数量级)和搜索时间(快一个数量级)方面,运行速度比ATM快得多(平均26.73分钟与72.75分钟)。同时为50%测试最小化预算实现了在测试执行时间上的40.38%节省。未来的工作。本文旨在通过研究其他预训练语言模型来扩展LTM,如PLBART和CodeT5。我们还计划评估LTM在工业系统和其他编程语言项目上的性能,以进一步推广我们的结论。
转述:王朝澜
