
AI 大模型人类反馈强化学习(RLHF)是一种结合人类反馈来优化大模型的技术。它借助人类的判断和偏好,让模型学习到更符合人类期望的行为和输出,从而提升模型的性能和表现。
 一、背景
一、背景在大模型发展初期,预训练模型虽然能学习到大量的基础知识,但在处理实际任务时,其输出可能不符合人类的需求和价值观。例如,在回答问题时可能给出不准确或不恰当的内容。
传统的有监督微调方式效果有限,因此需要一种新的技术来让模型更好地理解人类的意图和偏好,人类反馈强化学习技术应运而生。
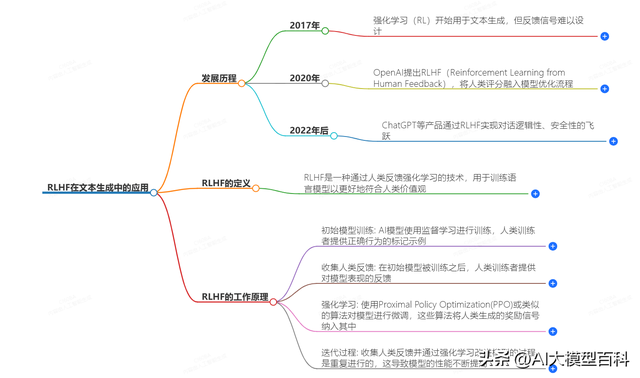
2、发展历程2.1 2017年:强化学习(RL)初步探索文本生成
背景:传统强化学习在游戏、机器人控制等领域已取得成果,但在文本生成中面临反馈信号设计难题。文本的复杂性(如逻辑连贯性、语法正确性、语义合理性)难以通过单一指标量化。局限性:需人工预定义奖励函数(如BLEU分数),但这类指标无法全面反映人类对文本质量的综合评判,导致模型生成内容可能“高分低质”12。2. 2020年:OpenAI提出RLHF技术框架
核心突破:通过人类反馈替代预定义奖励函数,直接优化模型输出与人类偏好的对齐。具体流程包括:初始监督微调(SFT):基于高质量标注数据训练基础模型。奖励模型训练:人类对模型输出排序,构建偏好数据集,训练奖励函数模拟人类评分。强化学习微调:使用PPO等算法,结合奖励模型信号迭代优化策略12。优势:解决复杂任务中奖励函数难以设计的瓶颈,使模型能捕捉更抽象的人类价值观(如安全性、逻辑性)。3. 2022年后:RLHF推动对话模型跨越式发展
代表性应用:ChatGPT及GPT-4通过RLHF实现两大提升:逻辑性:减少自相矛盾或脱离上下文的回答,增强多轮对话连贯性。安全性:规避有害、偏见性内容生成,符合伦理约束(如拒绝回答敏感问题)。技术迭代:RLHF与大规模预训练结合,形成“预训练-SFT-RLHF”三阶段范式,成为当前大语言模型训练的行业标准。3、原理与核心技术 3.1 原理:
3.1 原理:人类反馈强化学习的核心思想是让模型在与环境交互的过程中不断学习,通过人类的反馈来调整自己的行为策略,以获得最大的奖励。具体流程:
让模型生成一些结果,然后人类对这些结果进行评价(比如打分、排序等)这些评价作为奖励信号反馈给模型。模型根据奖励信号,利用强化学习算法调整自己的参数,使得在后续的生成中能得到更高的奖励,也就是生成更符合人类期望的结果。例如,一个文本生成模型生成了一段文案,人类用户认为这段文案逻辑清晰、语言流畅就给它打高分,模型收到高分奖励后,就会强化生成类似文案的策略;如果用户认为文案存在问题,打了低分,模型就会调整策略避免生成类似的内容。
3.2 步骤拆解监督微调(SFT):用人工标注的高质量问答对,初步训练模型。奖励建模(RM):人类对不同回答排序(如A比B好),训练一个能自动评分的模型。强化学习(RL):用RM的评分作为奖励信号,通过PPO等算法优化大模型。3.3 关键技术难点奖励模型设计:需平衡多样性(避免模型只生成单一答案)和安全性(过滤有害内容)。数据标注效率:采用对比学习(让人类比较答案而非逐条打分),降低标注成本。4、系统架构 4.1 数据收集模块
4.1 数据收集模块该模块负责收集不同类型的数据,为后续的训练和优化提供基础。
环境数据:从交易市场、游戏场景、自然语言处理任务中的文本语料库等环境中收集状态信息。在量化交易中,这些数据可能包括股票价格、成交量、宏观经济指标等。在自然语言处理中,可能是输入的文本序列及其相关的上下文信息。人类反馈数据:通过人工标注、问卷调查、用户评分等方式收集人类对模型输出的反馈。例如,在图像生成任务中,人类评估者可以对生成的图像进行打分或提供具体的改进意见;在智能客服场景中,用户可以对客服的回答进行满意度评价。4.2 预训练模型模块使用大规模无监督数据对模型进行预训练,使其学习到通用的语言、图像或其他领域的模式和特征。
模型选择:可以选择如 Transformer 架构的语言模型(如 GPT 系列)或卷积神经网络(CNN)架构的图像模型(如 ResNet)作为基础模型。训练过程:利用大量的文本、图像等数据,通过自监督学习的方式,让模型学习到数据中的内在结构和规律。例如,在语言模型的预训练中,通过预测下一个词或填充文本中的掩码部分来训练模型。4.3 奖励模型训练模块奖励模型用于学习人类的偏好和评价标准,为策略模型的优化提供奖励信号。
数据准备:将收集到的人类反馈数据进行整理和标注,形成训练数据集。例如,将人类对不同交易决策的评分与对应的市场状态和交易动作进行关联。模型训练:使用有监督学习的方法训练奖励模型。将市场状态、模型的动作等作为输入,人类的反馈分数作为输出,训练模型学习到输入和输出之间的映射关系。模型评估:使用验证数据集对训练好的奖励模型进行评估,确保其能够准确地反映人类的偏好和评价标准。4.4 策略优化模块基于奖励模型提供的奖励信号,对策略模型进行优化,使其生成更符合人类期望的行为。
强化学习算法选择:可以选择深度 Q 网络(DQN)、近端策略优化(PPO)等强化学习算法来优化策略模型。训练过程:策略模型在环境中进行交互,根据当前的状态选择动作,并从奖励模型中获得相应的奖励。通过不断地与环境交互和接收奖励信号,策略模型调整自己的参数,以最大化累积奖励。探索与利用平衡:在训练过程中,需要平衡探索新的动作和利用已有的经验。例如,可以使用 ε - 贪心策略,以一定的概率随机选择动作进行探索,以发现更好的策略。4.5 交互与部署模块该模块负责模型与环境的交互以及最终模型的部署和应用。
在线交互:在实际应用中,策略模型与环境进行实时交互,根据当前的状态做出决策,并将决策执行到环境中。例如,在量化交易中,策略模型根据市场状态做出买入、卖出或持有的决策,并将这些决策发送到交易系统中执行。监控与调整:实时监控模型的运行情况和性能指标,如收益率、准确率等。如果模型的性能出现下降或不符合预期,可以及时调整模型的参数或重新训练模型。部署与应用:将优化后的模型部署到实际的应用场景中,为用户提供服务。例如,将训练好的智能客服模型部署到客服系统中,为用户解答问题。4.6 反馈循环模块反馈循环是 RLHF 系统架构的重要组成部分,它使得系统能够不断地学习和优化。
反馈收集与更新:持续收集人类的反馈数据,并将其添加到数据收集模块中。同时,根据新的反馈数据更新奖励模型和策略模型。迭代优化:通过不断地重复数据收集、奖励模型训练、策略优化等步骤,使模型的性能不断提升,更好地符合人类的期望和需求。4.7 以下是一个简单的表格总结 RLHF 系统架构的各模块及其功能:模块名称
功能描述
数据收集模块
收集环境数据和人类反馈数据
预训练模型模块
使用大规模无监督数据对模型进行预训练
奖励模型训练模块
学习人类的偏好和评价标准,为策略模型提供奖励信号
策略优化模块
基于奖励信号对策略模型进行优化,生成更符合人类期望的行为
交互与部署模块
负责模型与环境的交互、监控和最终的部署应用
反馈循环模块
持续收集反馈数据,更新模型,实现迭代优化
5、本地部署与API集成5.1 本地部署方案本地部署 AI 大模型人类反馈强化学习是一个复杂的过程,一般需要以下步骤:
环境准备:安装必要的软件和库,如 Python、深度学习框架(如 PyTorch、TensorFlow 等)、相关的依赖库。数据准备:收集和整理用于训练和评估的数据,包括输入数据和人类反馈数据。模型选择与下载:选择合适的预训练模型,并下载到本地。代码实现:编写代码实现人类反馈强化学习的流程,包括数据加载、模型训练、奖励模型训练、策略优化等。资源配置:根据本地硬件资源(如 CPU、GPU)进行合理的配置,以确保训练和推理的效率。操作示例:硬件要求:至少16GB显存的GPU(如RTX 4090),推荐使用Hugging Face的transformers库。步骤示例:from transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained("gpt2-medium") # 加载本地模型tokenizer = AutoTokenizer.from_pretrained("gpt2-medium") 5.2 API集成方案API 集成可以方便地使用已有的大模型服务进行人类反馈强化学习。一般步骤如下:
注册与获取 API 密钥:在提供大模型服务的平台上注册账号,并获取 API 密钥。阅读文档:仔细阅读 API 文档,了解 API 的使用方法、接口参数、返回格式等。代码实现:使用编程语言(如 Python)调用 API,将输入数据发送到 API 接口,获取模型的输出结果。人类反馈处理:收集人类对模型输出的反馈,将反馈数据与输入数据、输出结果一起进行处理。反馈回传:根据平台的要求,将人类反馈数据回传到 API 接口,用于模型的优化和调整。以OpenAI为例操作示例:import openaiopenai.api_key = "YOUR_KEY"response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": "你好"}])print(response.choices[0]().message['content']) 6、 基于 OpenAI Gym 和 PyTorch 实现简单的强化学习使用 OpenAI Gym 环境和 PyTorch 实现简单的强化学习示例,虽然不是完整的人类反馈强化学习,但可以帮助我们理解强化学习的基本原理。
import gymimport torchimport torch.nn as nnimport torch.optim as optimimport numpy as np# 定义一个简单的策略网络class PolicyNetwork(nn.Module): def __init__(self, input_dim, output_dim): super(PolicyNetwork, self).__init__() self.fc1 = nn.Linear(input_dim, 128) self.fc2 = nn.Linear(128, output_dim) self.softmax = nn.Softmax(dim=-1) def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) x = self.softmax(x) return x# 初始化环境env = gym.make('CartPole-v1') input_dim = env.observation_space.shape[0] output_dim = env.action_space.n # 初始化策略网络和优化器policy = PolicyNetwork(input_dim, output_dim)optimizer = optim.Adam(policy.parameters(), lr=0.01)# 训练参数num_episodes = 500gamma = 0.99for episode in range(num_episodes): state = env.reset() states, actions, rewards = [], [], [] done = False while not done: state = torch.FloatTensor(state).unsqueeze(0) probs = policy(state) action = torch.multinomial(probs, 1).item() next_state, reward, done, _ = env.step(action) states.append(state) actions.append(action) rewards.append(reward) state = next_state # 计算折扣回报 discounts = [gamma**i for i in range(len(rewards)+1)] R = sum([a*b for a,b in zip(discounts, rewards)]) # 计算损失 loss = 0 for i in range(len(states)): state = states[i] action = actions[i] probs = policy(state) log_prob = torch.log(probs.squeeze(0)[action]) loss += -log_prob * R # 优化网络 optimizer.zero_grad() loss.backward() optimizer.step() if episode % 10 == 0: print(f"Episode {episode}: Total reward = {sum(rewards)}")env.close()示例中,我们使用 PyTorch 定义了一个简单的策略网络,使用 OpenAI Gym 的 CartPole-v1 环境进行训练。通过策略梯度算法优化网络参数,使智能体在环境中获得更高的奖励。
7、RLHF在量化交易方面的案例RLHF(人类反馈强化学习)在量化交易领域具有提升交易策略表现、更好适应市场变化的潜力。以下为你介绍相关实操案例及过程:
7.1 项目背景与目标某量化交易团队希望开发一个能适应复杂多变市场环境的交易策略,利用 RLHF 技术结合人类交易专家的经验和市场数据,优化交易策略,实现更高的投资回报率和更低的风险。
7.2 项目实现基本流程7.2.1 数据收集与预处理市场数据收集:从各大金融数据提供商获取股票、期货等交易品种的历史数据,包括开盘价、收盘价、最高价、最低价、成交量等信息。例如,收集过去 10 年沪深 300 成分股的日交易数据。人类反馈数据收集:邀请资深的交易员和投资专家,根据他们的经验和市场判断,对不同市场情况下的交易决策进行标注。比如,在市场出现突发重大利好消息时,专家认为应该采取何种交易操作(买入、卖出或持有)。数据预处理:对收集到的数据进行清洗,去除缺失值和异常值;进行标准化处理,将不同类型的数据统一到相同的尺度上,以便模型更好地学习。7.2.2 基础交易策略模型构建选择模型架构:选用深度强化学习算法,如深度 Q 网络(DQN)作为基础的交易策略模型。该模型可以根据市场状态预测不同交易动作的价值,从而选择最优的交易决策。定义状态空间:将市场数据(如价格、成交量、技术指标等)和交易账户信息(如持仓数量、资金余额等)作为模型的状态输入。例如,将股票的当前价格、过去 10 天的平均成交量、账户的可用资金等作为状态的一部分。定义动作空间:定义交易动作,如买入、卖出、持有等。可以根据不同的交易品种和交易规则进行细化,例如,买入可以分为不同的买入比例(10%、20%等)。定义奖励函数:设计奖励函数来衡量交易策略的好坏。奖励可以基于交易的收益、风险等因素。例如,每次交易的实际盈利可以作为正奖励,而交易的风险(如最大回撤)可以作为负奖励。7.2.3 人类反馈收集与标注设计反馈界面:开发一个专门的反馈界面,让交易专家能够方便地对模型的交易决策进行评价。界面可以显示当前的市场状态、模型的交易决策以及相关的历史数据。收集反馈:让交易专家在界面上对模型的交易决策进行打分(如 1 - 5 分),并提供具体的意见和建议。例如,如果模型在某一时刻做出了买入决策,专家认为该决策过于激进,可以给出较低的分数,并说明理由。标注反馈数据:将专家的反馈信息进行整理和标注,与对应的市场状态和模型决策进行关联,形成人类反馈数据集。7.2.4 基于 RLHF 的模型优化训练奖励模型:利用人类反馈数据集训练一个奖励模型,该模型可以学习到专家的评价标准和偏好。奖励模型的输入是市场状态和模型的交易决策,输出是一个奖励分数。更新策略模型:使用训练好的奖励模型来更新基础的交易策略模型。在模型的训练过程中,将奖励模型给出的奖励分数作为新的奖励信号,引导模型学习更符合专家意见的交易策略。迭代优化:不断重复收集人类反馈、训练奖励模型和更新策略模型的过程,逐步优化交易策略,使其在不同的市场环境下都能取得更好的表现。7.2.5 回测与实盘验证回测:使用历史数据对优化后的交易策略进行回测,评估策略的性能指标,如收益率、夏普比率、最大回撤等。通过回测可以了解策略在过去市场环境下的表现,发现潜在的问题和改进空间。实盘验证:在模拟交易环境中对策略进行验证,观察策略在实际市场中的表现。如果策略在模拟交易中表现良好,可以逐步将其应用到实盘交易中,并实时监控策略的运行情况,根据市场变化和实际交易结果进行进一步的调整和优化。7.3 案例效果经过一段时间的优化和验证,该量化交易团队的 RLHF 交易策略在实盘交易中取得了显著的效果。与传统的量化交易策略相比,该策略的收益率提高了 20%,最大回撤降低了 15%,表现出更好的风险控制能力和盈利能力。同时,策略能够更快地适应市场的变化,及时调整交易决策,为投资者带来了更稳定的收益
