
梁文峰与杨植麟,DeepSeek与月之暗面,颇有些当代版“既生瑜,何生亮”的意思。
之所以将二者放在一个语境下讨论,一是因为这是中国大模型最有希望的两个“年轻人”;二是因为他们在同一个领域“打”得火热,实实在在短兵相接;三是需要提醒大家,即便如今所有的镁光灯都聚焦在DeepSeek-R1上,但光环之外仍有人在努力,简单地归因和粗暴地判断于当下而言都是极其傲慢的。
在DeepSeek「炸街」之前,月之暗面(以及杨植麟),是中国最酷的大模型创业公司。
当春节期间DeepSeek以万夫莫当的气势冲击到全球大模型,并强行撞开大模型开源时,梁文锋的不语,让DeepSeek成为了当下最神秘以及最酷的大模型创业公司。
AI界大牛的认可、股票市场的反应、真实用户的选择都从月之暗面及Kimi转向了DeepSeek,甚至前者一直没有做到的:成为中国大模型的代名词,也被DeepSeek轻松斩获。
但一味的流量转移并不能说明问题,脱离技术和产品的讨论都显得太过于表面。事实上在技术路线的选择和研发上,二者也正在展开真刀真枪地较量。
1、DeepSeek比Kimi更狠2月18日,DeepSeek与月之暗面在同一天发布了两篇论文,前者由梁文锋在2月16日亲自提交,后者,杨植麟的名字鲜少出现在了论文作者的关键位置(名字越靠后,贡献越大)。


更为巧合的是,二者的新论文想要解决的是同一个问题:挑战一直困扰大模型的Transformer架构的注意力机制,通过自研的架构使它能处理更长的上下文。
这里需要解释的是,Transformer是今天所有大模型繁荣的基础,但它却有一个魔咒:就是全注意力机制,当它要处理一个问题,需要把所有“词”都跑一遍以获得更高的准确性。当模型小的时候,这样的弊端称不上是问题,但当处理的文本越来越长,越来越复杂,算力消耗越高、时间越长、技术越卡,甚至崩溃。
2024年下半年,一边学术界提出了一些新的架构(比如RVKW)试图替代Transformer,另一边,也有人基于Transformer进行优化,试图解决这个问题。
很明显,DeepSeek和月之暗面属于后者。
话说回两篇新论文,稀疏注意力机制是优化全注意力机制的一个有效方法,也是二者新架构同样选择的起点。
甚至他们的核心思路都出奇地一致,将语义压缩后进行分组,再利用动态选择减少计算量,最后通过查看最近的上下文信息来校对并保持连贯性。
技术看不懂没关系,简单的说,就是他们英雄所见略同,只不过DeepSeek用了解法1,而月之暗面用了解法2。
表面上的不同在于,DeepSeek提出的新架构名为NSA(原生稀疏注意力),而月之暗面提出的新架构,命名为MoBA(混合块注意力机制)。
但实际的区别是,DeepSeek的改造更为果断和彻底,而月之暗面兼顾了老机制和新机制,动态平衡,即为混合。
在NSA的论文中提到:“然而,大多数方法主要在推理过程中应用稀疏性,同时保留预先训练的 Full Attention 主干,这可能会引入架构偏差,从而限制它们充分利用稀疏注意力优势的能力。”
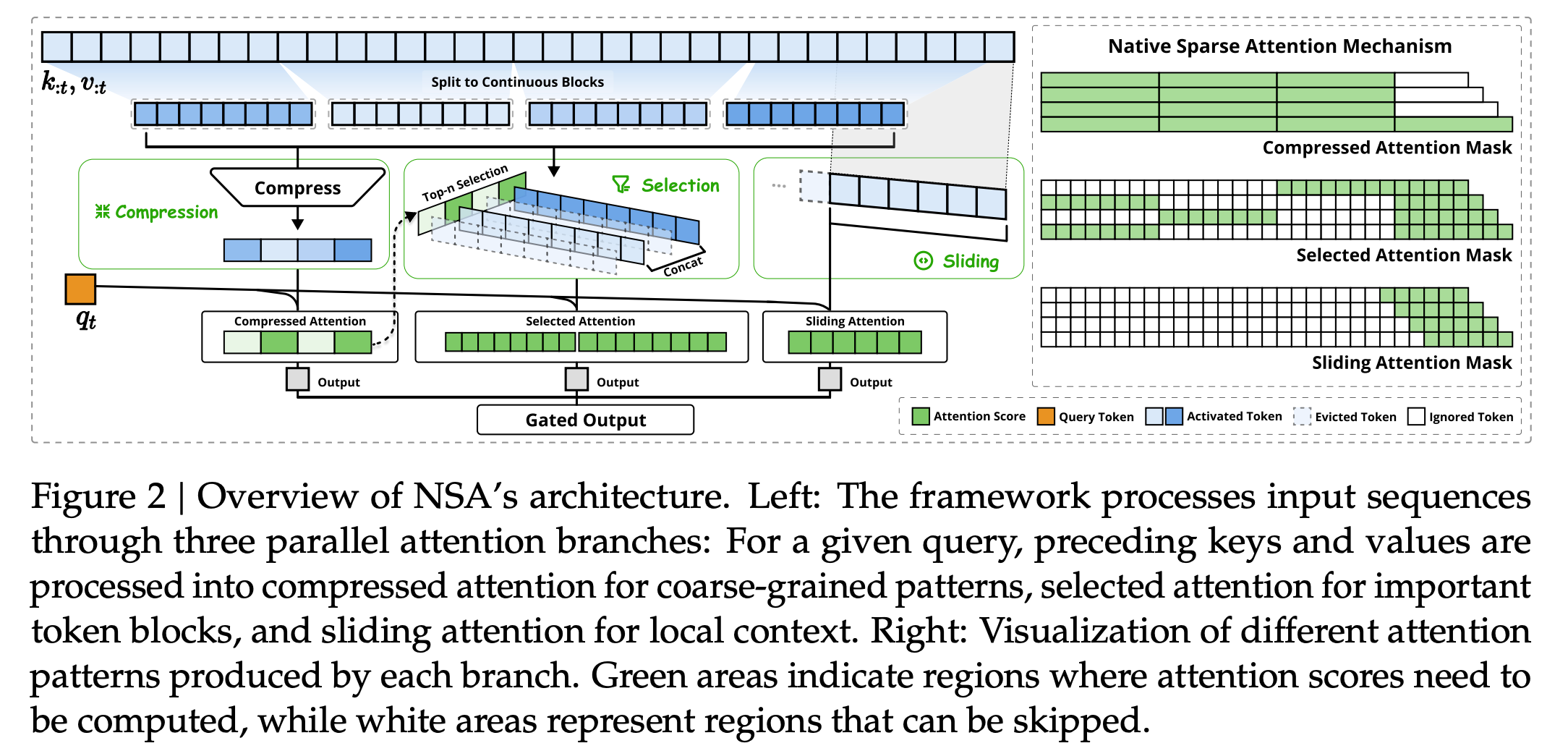
DeepSeek认为牺牲部分性能但是“兼顾”二者的方式具有局限性,试图从根本上重新设计稀疏注意力机制,遂提出了NSA。
尽管月之暗面同样认为现有的方法都行不通,但他们的解法是保留Transformer框架的同时遵循稀疏结构的原则,使模型能够在全注意力机制和稀疏注意力之间过渡。

一家完全丢弃传统结构做绝对的创新,另一家则保留传统结构的基础上做创新。
由于评测的标准和模型规模不同,从论文中无法直接对比二者的效果,NSA在保持模型性能的同时实现了训练和推理的加速,而MoBA在处理超长序列(如1M tokens)时展现出很好的扩展性,也持续了月暗一度的长长长文本策略。
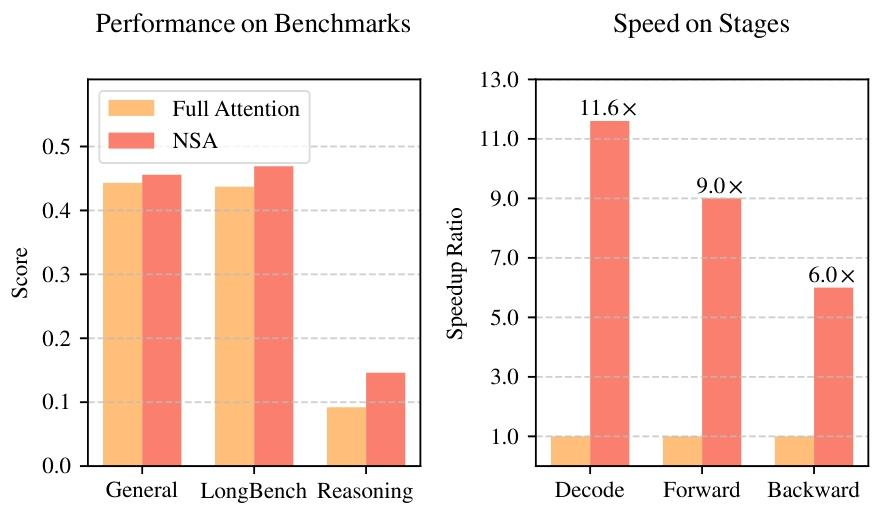
但在外界的评价而言,讨论NSA的热度显然高于MoBA,一方面梁文锋亲自上阵,一方面延续了R1的震惊,还有一方面,或许是人们更希望看到“反骨仔”,以及认可他坚定的态度。
2.两次交锋,两次惜败这并不是DeepSeek与月暗的第一次交锋。
如很多媒体报道的那样,同样作为推理模型,R1固然很牛,但K1.5也不差。
就连OpenAI罕见的发布了o系列的论文中都特别提到,中国的DeepSeek-R1和Kimi k1.5通过独立研究显示,利用思维链学习(COT)方法,可显著提升模型在数学解题与编程挑战中的综合表现。

也就是说,OpenAI自己将R1与K1.5作为比较的对象。
这事还要从o1出现开始说起。上一次大模型界这么热闹的时候,是OpenAI发布了思考模型o1,打开了大力出奇迹的另一条路。
当全世界范围都在思考o1是怎样炼成的,如何复刻时。他们发现OpenAI的最后一篇论文名为《Let’s Verify Step by Step》,就是一步一步的、逐句逐句的训练模型。于此同时还有一个惊喜的发现,OpenAI公布了一个PRM800K的数据集,题目给出了每一步的推理过程,并进行打分。

于是很多人都认为,这篇论文+这份数据集,是复现o1的关键。只有两个年轻人没信,就是DeepSeek和月暗。
后来的事实证明了,这不仅仅不是正确的方法,是OpenAI放出的烟雾弹,甚至是一个完全相反的路线:一步一步地调会限制模型的想象力,越训越笨。
而没有相信的这两位年轻人,同时选择了RL(强化学习)作为技术方向,并没有掉进OpenAI设置的陷阱中去。只不过R1从Zero开始,更加纯粹,上线更早,同步开源模型。
这里不得不佩服月暗的是,一家创业公司,正陷入与投资人的天价官司里,又要搞产品大规模营销投放,没有一个成型的商业模式,但技术研究却也没落下。相比于幻方用卡和钱为DeepSeek创造了十分纯粹的科研环境,为K1.5的诞生,再增添一份难得。
事情的结果我们都知道了,DeepSeek的热浪完全掩盖了关于K1.5的讨论,人们不曾记得这是闭源的月暗第一次发布K1.5的技术报告,也不曾发现K1.5早已在Kimi里上线,可以联网且完全不会出现“服务器繁忙,请稍后重试”。
在这两次交锋里,月暗已经足够聪明足够正确反应速度也足够快了,但却因为不够“狠”不够绝对而惜败,于是,惋惜大过思考,才有“既生瑜,何生亮”的感慨。
NSA与MoBA都已经应用在了各自的模型和产品上,大模型的路还长,月暗未必要强行开源,但却与DeepSeek,必有一战。
参考文章:
「硅星人Pro」杨植麟和梁文锋,论文撞车了
「真格基金」万字赏析 DeepSeek 创造之美:DeepSeek R1 是怎样炼成的?
