作为一个不会设计图但还想捣鼓一下自媒体,偶尔发下文章之类的程序员,经常需要图片时想基于大模型的文生图AI能力创作一个,但一直没有遇到合适的,下面我花了一些时间就像神农尝百草一样体验下各大平台的AI文生图能力。
注:请耐心看完,最后确实有百分百满足需求的平台(非广告,其它平台经过未来发展可能也会提升,另外也可能和大模型训练的数据集缺少相关主题的图片内容有关,也许各有侧重重点,因此结果仅为个人测试当作随机参考)
统一测试提示词:请画一幅图,图中有一块黑板,黑板上写着简体中文"AI让程序员变为全栈",字体是白色,并且在排版方面都排在同一行
通义千问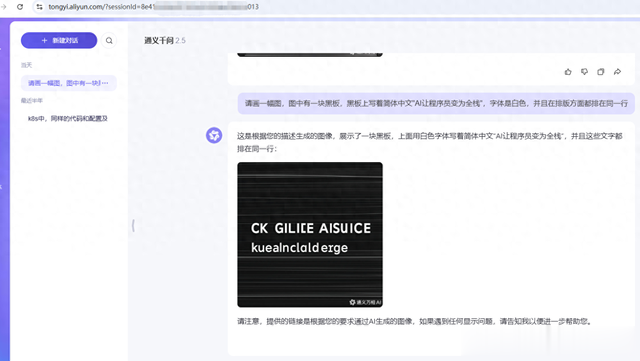
通义千问-测试结果
文心一格
文心一格-测试结果
豆包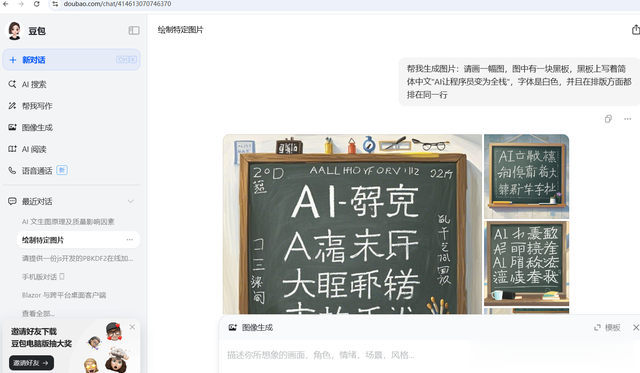
豆包-测试结果
Tusiart
tusiart-测试结果
liblib.art
liblib.art-测试结果
无界AI
无界AI-测试结果
Qiyuai
奇缘-测试结果
insmind
insmind-测试结果
Fluxai
fluxai-测试结果
Bigesj
bigesj-测试结果
Whee注:美图旗下 AI 绘画平台,模型是 MiracleVision 大模型

whee-测试结果
汇总下结果如下:
AI平台
意图理解
生成图片质量
综合评分
通义千问
未理解
内容完全不符
*
文心一格
理解了黑板
文字不符,乱
*
豆包
理解了黑板
文字是日文
**
tusiart
没理解
完全不符
-
liblib
理解了黑
非黑板,文字不符
-
无界AI
理解了黑板
文字不符
*
qiyuA
没理解
完全不符
-
insmind
没理解
完全不符
-
fluxai
理解黑板
文字不符
**
bigesj
可理解
多了个老师
****
whee
可理解
完全正确
*****
为什么文生图看起来比较难,甚至只有个别大模型可以做的相对靠谱?
下面是AI文生图的核心原理和生成图片的质量关联因素:
1)大规模有丰富标注的图片数据集的预训练
AI 文生图模型需要在大量的现有“图像-文本对"数据上进行预训练。这些数据集包含了各种各样的图像和与之对应的文本描述。例如,有风景图片和描述其景色特点的文字,有人物图片和对人物外貌、动作的描述等。通过对这些数据的学习,模型能够理解不同的文本元素和图像特征之间的关联。
2)对用户请求的语义理解与特征提取
模型会从文本中提取语义信息,比如对象(人、物等)、属性(颜色、形状等)、关系(位置关系、动作关系等)。同时,它也会从图像数据中提取相应的视觉特征,如线条、色彩分布、纹理等。然后将文本语义与图像视觉特征进行匹配学习。例如,对于 “一个红色的圆形气球在蓝色天空中飞翔” 的文本,模型会学习到 “红色”“圆形”“气球”“飞翔”“蓝色天空” 这些语义元素应该与什么样的视觉特征相对应,从而在生成图像时能够根据这些知识组合出合适的画面。
