
大多数人都经历过这样的尴尬时刻:客服热线另一头的机器人,用一成不变的语调试图解答你的困惑。
你一边努力理解,它一边坚持重复。
这种缺乏个性和情感的语音体验,让人不由得想:如果智能语音技术能变得更自然、更贴近人类,那该多好啊。
OpenAI最近推出的新一代音频模型,似乎就是为了解决这个问题而生。
但这一次,它能搞定中文吗?
定制化语音选项:从“美食主厨”到“中世纪骑士”
OpenAI的新模型提供了名为“美食主厨”和“中世纪骑士”等有趣的预置声音选项。
这些来自不同领域的“角色”,不仅能模仿典型的语调和风格,还能增加对话的趣味性。
想象一下,一个AI用生动的意大利口音向你推荐菜单,或者一个骑士用古韵的中世纪英语跟你对话,这些都是在OpenAI的平台上可以实现的。
用户可以通过选择和调整这些预置选项,来体验不同的交互风格。
这为语音软件带来了一种新鲜的活力,不再是单调乏味的机械声音,而是充满个性和风格。
在测试中,OpenAI的语音生成显得生动,特别是在那些需要表现情感和细节的角色上,比如热情的美食家。

但细心的用户也发现,中文语音的表现似乎并没有达到同样的效果。
中文文本转语音的挑战与改进空间当涉及中文的语音合成,问题就显得棘手了。
虽然这些模型在处理英文或其他西方语言时表现优异,但在中文场景中,声音的自然度和情感表现力仍有较大提升空间。
比如,当智能体尝试执行一个普通的中文语文老师的角色时,结果往往不如人意。
语音缺乏应有的情感起伏,听起来有些生硬。
这是可以理解的挑战。
中文的复杂音调和丰富的语境使得语音合成极富挑战性。
虽然OpenAI在中文识别上已经取得了一些进展,但在流畅性和细腻度上,还有一些路要走。
大家也许会好奇:“为什么中文就那么难?”
这源于中文中每个字的音调差异和更复杂的语音结构,这对任何语音识别技术都是挑战。
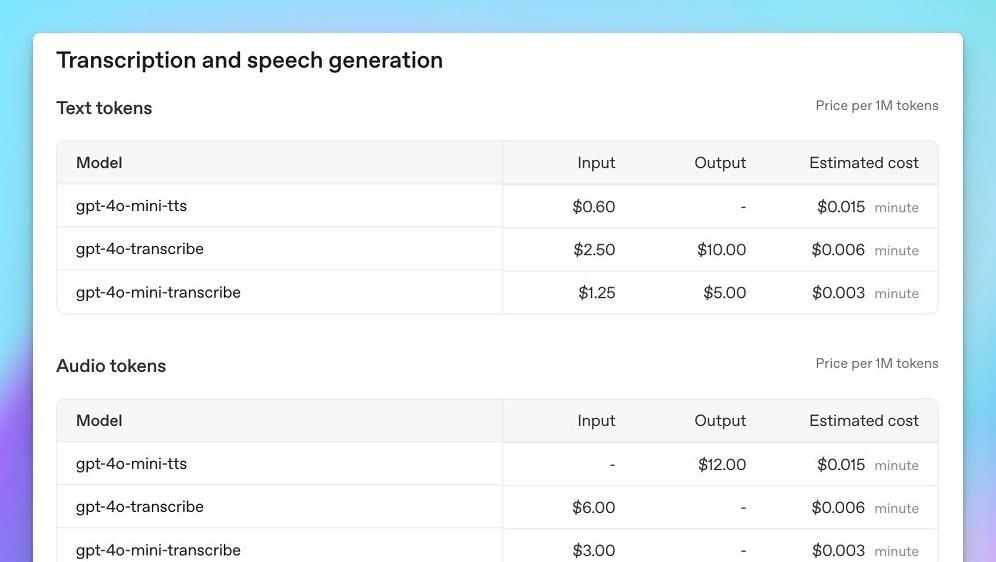
新一代语音转文字模型超越whisper
另一方面,OpenAI推出的新一代语音转文字模型呈现了不错的表现,特别是在单词识别正确率上。
与上一代的whisper模型相比,新的gpt-4o-transcribe模型在识别错误率上显著降下来。
对于用户来说,这意味着更少的误解和更快的响应时间。
在高资源语言如英语和法语上,模型的表现更是令人满意。
尽管中文的提升空间明显,但这些模型在其他语言上的出色表现依然引人注目。
例如,在孟加拉语和古吉拉特语这样的低资源语言领域,它们取得了显著进步。
这些改进依赖于深度学习技术的优化,特别是在模型的预训练和蒸馏过程中的改进。
技术探索:音频模型的未来前景尽管眼下的声音识别技术仍需改进,但未来的前景是令人期待的。
OpenAI及其他科技巨头正在致力于引入自定义声音选项,并提升音频模型的准确性和智能性。
这意味着,未来我们可能看到更加个性化的语音助手,它们能够在各种复杂场景中提供自然流畅的交互体验。
结语:开放语音技术背后,是技术与人性化的不断追求。

在这一过程中,我们逐步探索如何让机器变得更像“人”。
技术的发展不只是为了效率,也是在追求更丰富的情感互动和真实体验。
尽管在中文语音上还有一些需要克服的挑战,但OpenAI的努力显示了一个技术不断进步、突破边界的世界,这也激励着其他领域的创新者继续探索未知的可能性。