山姆·奥特曼红杉资本AI峰会专访:核心内容总结一、OpenAI的创业历程与发展路径【1.1初创阶段:信念驱动的小团队】•2016年,OpenAI成立,仅有14人团队;•成员对AI的未来应用没有明确方向,仅凭对AGI的坚定信念前行;•当时对“大语言模型(LLM)”尚未有明确认识;•初期重点研发方向是游戏AI:开发的OpenAIFive在Dota2中击败人类业余选手。【1.2模型探索期:从GPT-1到GPT-3】•转向无监督学习;•GPT-1、GPT-2先后发布,但反响较小;•GPT-3发布时亦“反响平平”,尽管内部团队觉得模型“非常酷”;•公司经历了数年“黑暗时期”,产品未被市场认可。【1.3转机契机:对话功能受欢迎】•团队意外发现用户“特别喜欢和GPT对话”;•GPT-3当时对话能力有限,但这一反馈促使团队尝试开发聊天机器人;•2022年11月30日,ChatGPT上线;•随后“一发不可收拾地席卷全球”,现每周活跃用户超5亿人。⸻二、用户行为与代际差异【2.1年轻用户:ChatGPT即操作系统】•上传文件、设置复杂提示词,将ChatGPT作为“操作系统”使用;•在做重要人生决定前也会先询问ChatGPT意见。【2.2年长用户:ChatGPT是工具替代】•多数人将其作为Google浏览器替代品或聊天软件使用;•存在明显的“代际使用差异”,如同智能手机初期的用户分层。⸻三、OpenAI为何能保持高更新频率【3.1拒绝大公司病】•奥特曼指出传统大公司存在“惯性”,使用“旧方法”反而抑制创造性;•OpenAI避免陷入这种模式,强调“小而精,小而美”的团队架构。【3.2高效团队运作机制】•“一个好的高管就是一个忙碌的高管”;•每位团队成员“手头都有很多任务”,且任务具有“高价值与高影响力”;•强调持续成长,避免组织“停滞不前”。⸻四、产品设计理念与组织哲学【4.1不设宏大目标,专注当下】•OpenAI“没有宏大计划”,坚持“边做边看”;•奥特曼反对事先将每一步都详细规划的人,认为他们“几乎不会成功”;•正确做法是:找对方向,专注一两步内的推进,避免“好高骛远”。【4.2AI产品的未来形态:高度个性化】•未来的ChatGPT将是一个“非常小巧的推理模型”,但记录你“整个人生经历”;•包含的内容包括用户“说过的所有对话、读过的书、每封邮件”等;•用户会不断地“向上下文添加新内容”,实现个性化推理。⸻五、AI未来发展的核心技术与路径【5.1编程能力是AI的核心能力】•奥特曼强调:编程是AI在现实中执行任务的关键;•不只是回答文本或生成图像,更要能“调用API、做出行动”;•编程被视为OpenAI未来发展的核心能力。【5.2AI智能体的发展路径预测(2025-2027)】•2025年:AIAgent(AI智能体)进入实用期,开始承担工作任务,尤其在编程领域表现突出;•OpenAI已推出Codex智能体作为新编程助手;•2026年:AI将能独立或辅助人类完成重大科学发现,推动下一波经济增长;•2027年:机器人将由实验产品变为“真正创造经济价值的核心产品”。⸻六、总结与启示【6.1创业心态的启示】•不依赖“完美的计划”,而是专注在正确方向上的持续迭代;•小团队、扁平管理、全员高效,是保持创新的关键。【6.2产品设计的反思】•用户反馈是产品迭代的核心;•未来产品需具备高度个性化、实际执行能力与智能协作属性。【6.3对观众的启发】•无论是管理小团队,还是培养做事心态,奥特曼的经验都具有现实参考意义。
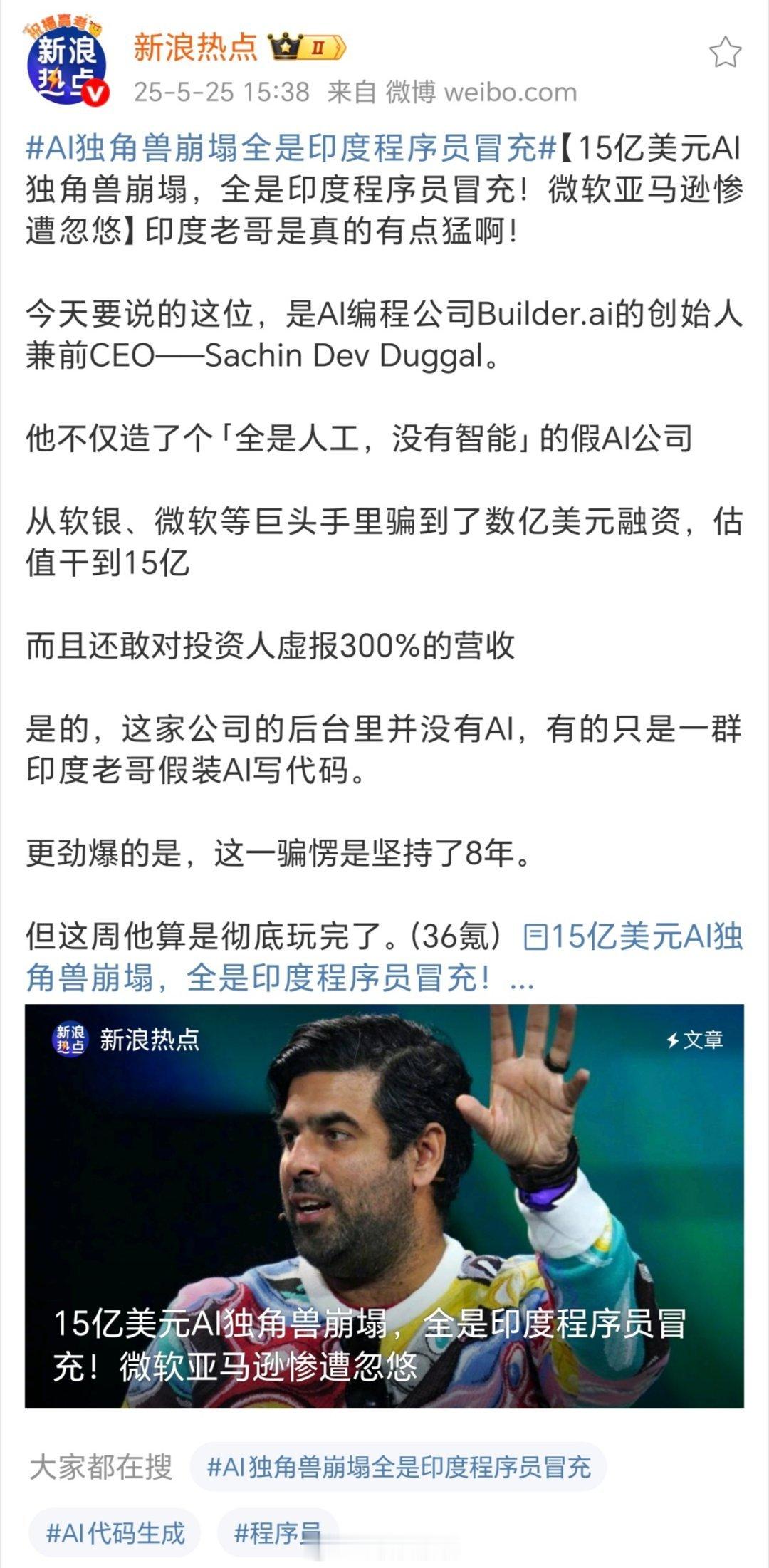


![AI独角兽崩塌全是印度程序员冒充豪哥哥的视频有新的素材了[doge][doge][doge]](http://image.uczzd.cn/8069026597952876352.jpg?id=0)