CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search
Nikita Sorokin1, Dmitry Abulkhanov1, Sergey Nikolenko2, andValentin Malykh1
1Huawei Noah’s Ark Lab, valentin.malykh@huawei.com,
2St. Petersburg Department of the Steklov Institute of Mathematics, sergey@logic.pdmi.ras.ru
引用
Sorokin, Nikita, et al. "CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search." arXiv preprint arXiv:2305.11626 (2023).
论文:https://arxiv.dosf.top/abs/2305.11626v1
摘要
本文讨论了源代码的克隆检测和信息检索问题,被认为是任何编程语言都重要的任务。本文提出了多语言克隆检测问题,并提出了一个新的从CodeForces提交数据集中生成的基准数据集XCD。此外,本文还提出了一种新颖的训练过程——交叉一致性训练(CCT),将其应用于在不同编程语言中训练语言模型的源代码。该方法下的CCT-LM模型,以GraphCodeBERT为初始模型,并用CCT进行微调,在所有编程语言的新创建的多语言克隆检测基准XCD上展现了最佳结果。
1 引言
克隆检测问题源于软件开发实践中的一个重要需求:识别具有相同行为和有效输出的代码;这对于代码统一化、重构和控制副作用等方面是有用的。在自动化语言处理中,Mou等人为C/C++源代码制定了克隆检测任务,后来这个问题被扩展到其他编程语言。这个问题的自然下一步是在不同编程语言中检测相同的行为。本文制定了跨语言克隆检测任务,为此收集了一个数据集,并在这个数据集上建立了合理的基线。
在代码搜索方面的早期工作大多依赖于经典的信息检索方法。一些研究人员使用了三种基于Transformer的模型,其中两种作为编码器,一种作为分类器,用于对代码和文本进行分层表示;虽然他们尝试了共享编码器参数,但这降低了模型的最终质量。相比之下,我们的模型使用单个编码器来嵌入查询和文档,并跳过了分类器部分。
针对克隆检测任务已经开发出了各种方法,从算法方法开始,到机器学习模型。大多数机器学习方法都是基于学习代码片段的表示(嵌入);这种方法允许通过在潜在空间中嵌入它们的嵌入之间的相似性来找到重复的代码片段。但是这种系统的性能在很大程度上取决于嵌入的质量。最早尝试检测类似程序代码的是Baker,他提出了在精确和参数化形式中查找重复代码的方法,该方法可以重新表述为代码混淆和搜索混淆的精确匹配。在自然语言的BERT-like模型取得成功之后,这些方法也被应用到了编程语言。最近提出了几种预训练编程语言模型,包括:CodeBERT,一种基于RoBERTa Transformer架构的双模预训练模型,用于源代码和自然语言,训练时采用了掩码语言建模(MLM)和替换令牌检测目标;GraphCodeBERT,它在预训练过程中使用数据流来解决MLM、边预测和节点对齐任务;SynCoBERT ,它使用多模态对比学习,在预训练中进行标识符预测和AST边预测。
本文提出了一种新的训练技术和管道,称为CCT,用于语言模型,它可以以有效的方式嵌入代码片段。通过在现有的克隆检测数据集POJ-104和新制定的跨语言克隆检测数据集XCD上取得最先进的结果来证明这一点。本文提出的CCT技术使模型能够产生对代码搜索有用的表示。所谓的代码搜索,是一种查询是文本描述。
本文工作的主要贡献如下:
(1)提出了一种预训练方法CCT,使模型能够对不同编程语言中的代码片段进行对齐;
(2)基于CodeForces提交提出了一个新的跨语言克隆检测数据集XCD;
(3)展示了通过CCT训练的语言模型CCT-LM在克隆检测数据集POJ-104和XCD2上获得的最新结果;
(4)展示了CCT-LM在AdvTest数据集上进行代码搜索的最新结果。
2 方法介绍
本章介绍了预训练方法CCT(交叉一致性训练)。其目标是稳健地学习代码片段的嵌入空间,并在不同编程语言中解决相同问题的代码片段之间创建强大的对齐。强对齐和弱对齐之间的区别在图1中进行了说明:在一个弱对齐的嵌入空间中,最近的邻居可能是来自不同语言的语义相似的代码片段,但通常大多数邻居都是同一种语言,而在一个强对齐的空间中,相似性纯粹是语义上的,根本不考虑语言。
为了实现强对齐,本文引入了一个新的对比学习目标 LXCD:对于一个随机屏蔽的代码片段,我们训练 [CLS] 向量,使 [CLS] 嵌入更接近于另一种语言中解决相同问题的片段,或以不同方式屏蔽的相同片段,而不是随机片段或相似但不同的片段。本方法还使用了两个额外的损失函数:错误检测损失Lerr和语言建模损失LLM。本文最终损失函数是这三种损失的组合:
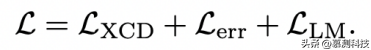
下面我们将详细介绍这些损失。
2.1噪声对比估计和损失
为了学习与语言无关的跨语言表征空间,本文提出了一种基于噪声对比估计(NCE)的训练程序。假设 X 和 Z 是一些有限集合,sθ : X × Z → R 是一个在 θ∈Rd 中可微分的相关性得分函数。本方法的目标是学习θ,使分类器 x → arg maxz∈Z sθ(x, z) 具有最佳预期损失。这就引出了条件密度估计:对于每个 x ∈ X

θ∗ = arg minθEx,z [- log pθ (z|x)] 为最优。实际上,直接优化这一目标是不可行的:如果 Z 较大,则 (1) 中的归一化项是难以实现的。(1) 中的归一化项是难以实现的。因此,NCE 采用子采样,因此 (1) 变为

其中,Bx,z = {Z1–,Z2–,... ,Zn–}是一组从 Z 中采样的否定答案,对于x,这些否定答案与肯定答案与正向答案 z +不匹配。 NCE 还经常使用与 (2) 类似的目标 与 (2) 类似,但使用 πθ (zˆ|z),其中 z 和 zˆ 来自同一空间,目标对应于某种相似性函数。目标对应于某种相似性函数。
跨语言目标。对比学习经常采用预文本任务来学习数据表示,而无需标记的示例。在从多语言文档集中学习的情况下,一个可能的预文本任务是训练一个网络来区分内容相似但使用不同语言编写的文档(正对)和内容不相似的文档(负对)。这导致了损失函数
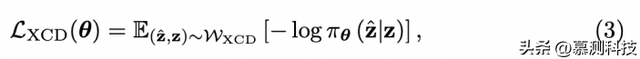
其中WXCD是来自XCD数据集(第3节)中不同编程语言提交对集合的分布,该分布显示了提交是否解决了相同的问题。
语言建模目标是噪声对比估计的标准实现,类似于Devlin等人的方法,其中WLM是词汇表上的令牌分布,在我们的案例中是从XCD中收集的:
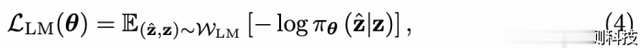
错误检测目标。对于错误检测损失Lerr,我们使用二元交叉熵进行分类,判断代码在执行过程中是否可能引发错误:
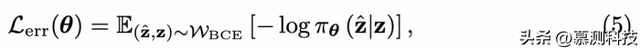
其中WBCE再次是XCD上的分布,但在这种情况下反映了提交是否成功的裁决。Lerr是针对源代码数据的特定目标,旨在帮助模型理解代码语法并识别错误。
2.2 严格负例挖掘
先前的对比学习工作表明,训练中使用严格负例样本是非常重要的。这些工作使用迭代训练来获取严格负例;然而,我们的数据已经包含了一些强烈的负例,即同一用户的初步解决方案,它们解决了相同的问题,但在某些测试中失败(这就是为什么用户会提交更新后的解决方案以获得“接受”裁决)。因此,我们的严格负例样本是从同一用户的失败解决方案中挖掘出来的,如果存在的话;如果没有,我们就使用随机用户的失败解决方案,仅当没有这样的解决方案时(例如,对于一个不太受欢迎的问题),我们才使用一个随机问题的随机提交。
3 实验评估
3.1 预训练
本文使用预训练的GraphCodeBERTbase模型来初始化模型;结果模型称为CCT-LMbase。本文完整的比较设置遵循了Ruder等人和Tien和Steinert-Threlkeld的方法,其中将区分克隆和非克隆的相似度分数截断值分别针对每对语言进行了优化。相似度分数是基于[CLS]向量表示的点积计算得到的。
超参数。使用AdamW优化器,学习率为1e-4,权重衰减为0.01,并且使用线性学习率衰减。本文使用渐变缓存进行预训练,累积批量大小为500。在4块NVIDIA Tesla V100 GPU上训练模型,总共花费了384个GPU小时进行基础模型的预训练。
3.2 单语言结果
表1展示了我们的CCT-LM模型(从一个带有CCT的GraphCodeBERT检查点预训练而来)与现有方法的比较结果。结果显示,即使在这个单语言设置下,CCT-LM的表现也远远优于所有先前的模型。这表明,CCT预训练所强制的强对齐不仅有助于多语言转移,而且也普遍改善了潜在空间结构。
表1:在POJ-104数据集上的代码克隆检测结果和在AdvTest数据集上的代码搜索结果。

3.3 多语言结果
在提出的XCD数据集上的多语言设置结果如表2的上半部分所示。在完整的比较设置中,来自POJ-104数据集的知识转移也没有起到帮助作用,度量指标仍然非常低。然而,由于CCT预训练的多语言设计,CCT-LM表现出了更好的结果。在这个设置中不评估BM25,因为它不适用于比较两个文档。
对于检索式评估,结果显示CCT-LM明显优于所有基线,并实际上为该问题提供了可行的解决方案,而GraphCodeBERT在任何编程语言中都没有产生合理的结果。此外,BM25(对自然语言IR任务的强基线)不适用于克隆检测,因为它依赖于相同的令牌,即使是在解决相同问题的代码片段之间,这些令牌可能也很稀缺。
混合评估设置的结果也呈现相同的情况:BM25仍然不起作用,代码语言模型可以在不同解决方案之间在一定程度上传递知识,而在完全无监督的方法和在POJ-104克隆检测上进行训练之间的度量指标改进在这里显著更大。尽管如此,CCT-LM在这里远远超过了其他方法,并且通常为多语言代码相关任务设定了一个新的基准。
表2:XCD数据集上的多语言和跨语言克隆检测在三种评估设置中的结果。

3.4 跨语言结果
这个设置中的结果呈现在表2的下半部分。所有在多语言情况下得出的结论(第2.3节)在这里也适用,但与多语言设置相比,跨语言任务更加困难,所有数值都较低。因此,编程语言结果的差异可能是由预训练数据集的不平衡造成的。
3.5 零-shot 结果
本文研究了从 Python 到 Java、Ruby、PHP、Go 和 JavaScript 在 CodeSearchNet 数据集上的零-shot 转移,针对先前引入的代码语言模型以及我们的 CCT-LM。零-shot 结果显示在表3中。作为预训练语言模型能力的证据,我们可以看到,即使这些方法尚未在检索任务上进行训练,它们也显示出相当不错的结果。通过利用其多语言能力,CCT-LM 在除了 JavaScript(JS)之外的所有语言的零-shot 设置中都优于基线。
3.6 潜在空间结构

图1:强和弱跨语言对齐
图1显示了基本 CCT 思想的抽象表示,即语义对齐的语言无关嵌入空间。图2将这一理论转化为实践,通过投影显示了 CCT 训练前后示例代码片段的实际嵌入。这些片段代表了六种编程语言中 12 个样本任务的解决方案。我们可以看到,在 CCT 后,代码片段的表示不是按语言对齐,而是按问题对齐(图2b),而在 CCT 之前,它们的对齐是依赖于语言的(图2a)。这说明了 CCT 训练显著改善了代码片段的多语言潜在空间,使其具有语义性且与语言无关。
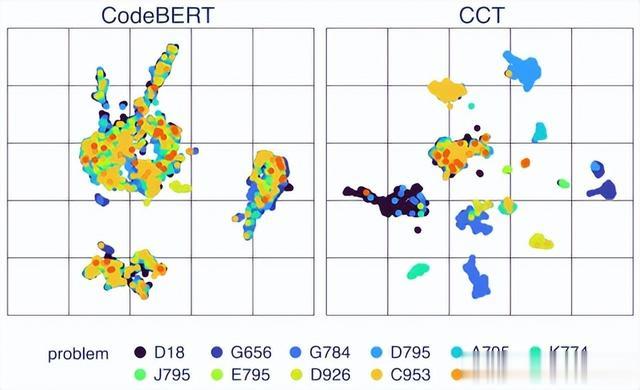
(a) 12个编码问题的投影嵌入。
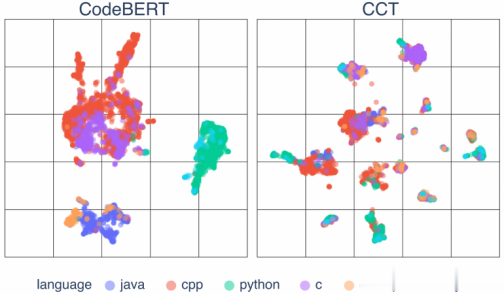
(b) 相同的嵌入按编程语言显示。 图2:示例多语言嵌入
4 总结
理解语义相似性是语言处理的重要方面,它为解决许多不同的任务打开了途径,无论是自然语言还是编程语言。本文提出了一种新方法CCT-LM,通过一种新颖的CCT预训练方法改善了这种能力,并展示了其在克隆检测和代码搜索任务中的可行性。此外,本文还制定了一个新颖的多语言克隆检测任务,提出了用于多语言和跨语言源代码分析的XCD数据集,并在三种评估设置中进行了规范化。所提出的CCT-LM模型在所有提出的任务中都表现出色,证明了CCT预训练为语言模型提供了更好的语义相似性理解。跨语言设置被证明对当前的语言模型来说更难解决,留下了很大的改进空间。
转述人:石孟雨
