想象一下,你只需要打一段文字,比如“一只穿着宇航服的猫在月球上弹吉他”,AI就能给你生成一段栩栩如生的视频!这听起来是不是很神奇?这就是文生视频(Text-to-Video)技术。

OpenAI 的 Sora: 去年一发布就惊艳了全世界,能生成长达一分钟、画面精美、逻辑连贯的高清视频,效果非常接近真实世界。
Google 的 Veo: 同样是业界顶尖水平,强调对物理世界的理解和更精细的控制能力。
还有像 Runway 的 Gen-3、Pika Labs 的 Pika 1.5、快手的 Kling 等等,都在这个赛道上不断突破。

这些模型大多采用了一种叫做“扩散模型 (Diffusion Model)”的技术,你可以简单理解为:AI先看到一堆“雪花点”(噪声),然后根据你的文字提示,一步步把这些雪花点“擦除”,最终还原成清晰的视频画面。

不过,目前很多模型在生成视频时,有点像是在“一次性画完整部电影”。它们倾向于同时处理整个视频片段,考虑所有帧之间的关系。这种方法虽然能保证整体的一致性,但在几个方面存在挑战:
实时性差: 不太适合需要快速响应的直播或互动场景。可控性一般: 想中途修改视频内容或风格比较困难。因果关系弱: 它们有时不太遵循现实世界中“先有因后有果”的时间逻辑。
MAGI-1 的“神来之笔”:像写小说一样生成视频!
现在,Sand AI 带来的 MAGI-1 采用了完全不同的思路——自回归 (Autoregressive) 模式!
传统方法: 像画家一样,先构思好整个画面,再一起画出来。
MAGI-1: 更像作家写小说,一句话(一个视频块)接一句话(下一个视频块)地写。后面的内容是在前面内容的基础上生成的。

MAGI-1 自回归模式的创新点和优势:
严格的因果性: 因为是按时间顺序生成的,所以天然符合“过去决定未来”的逻辑,这对于模拟真实世界的物理规律和连贯动作至关重要。天然支持流式生成: 可以生成一块,就显示一块,不需要等整个视频都处理完。这让实时生成、直播互动成为可能!想象一下,你可以一边输入文字,一边看着视频实时变化!高效推理: 生成长视频时,计算成本和内存占用只跟当前需要处理的“块”有关,不会因为视频总长度增加而无限增长。这对于部署和成本控制非常友好。
精细化控制:
分块提示 (Chunk-wise Prompting): 你可以给视频的不同“块”输入不同的文字指令!比如前3秒是“日落”,后3秒变成“星空”,MAGI-1可以自然地过渡。这让创作复杂叙事的长视频成为可能。
视频续写: 无缝衔接已有的视频片段,继续生成后续内容,而且效果比只看最后一帧的“看图说话”式续写要好得多。
可控转场: 通过巧妙的技术(调整KV Cache范围),可以在保持主体不变的情况下切换背景,或者保持场景不变的情况下改变物体细节。

深入MAGI-1的“内芯”:它是怎么做到的?
虽然自回归很酷,但实现起来挑战巨大。MAGI-1 包含了很多技术细节:
视频分块 (Chunking): 将视频切成固定长度的小段(比如论文里是24帧,即1秒 @ 24FPS)。
Transformer VAE (变分自编码器): 在处理视频前,先用一个基于 Transformer 的 VAE 把视频数据“压缩”成更小的“精华”表示(Latent Space),这样处理起来更快更高效。MAGI-1 特别设计了这个 VAE,速度很快。

核心引擎 (自回归去噪模型):
架构基础: 基于强大的 Diffusion Transformer (DiT) 架构。
关键改造:
块状因果注意力 (Block-Causal Attention): 这是实现自回归的核心!确保每个块在生成时,只能“看到”它自己内部的信息和所有在它之前的块的信息,看不到“未来”的块。
并行注意力 (Parallel Attention): 同时处理自注意力和与文字条件的交叉注意力,提升效率。
其他优化: QK-Norm、分组查询注意力(GQA)、FFN中的Sandwich Norm、SwiGLU激活函数、Softcap调节等,都是为了提升模型在大规模训练时的稳定性、效率和效果。

训练策略:
多阶段训练: 从低分辨率、短视频开始,逐步增加分辨率和视频长度,让模型先学习基础再精通细节。
多任务合一: 通过巧妙的数据配置,用一套模型同时训练文本生成视频 (T2V)、图像生成视频 (I2V)、视频续写 (Continuation) 三种任务!这非常高效。
噪声调度和采样: 精心设计了噪声添加和采样策略(基于Logit-Normal),让模型在训练时更关注“困难”的部分(噪声较大的早期阶段),提升效率和效果。

推理 (生成视频时):
引导 (Guidance): 使用 Classifier-Free Guidance (CFG) 来平衡“听从指令”和“自由发挥”的程度。特别地,它还考虑了前一个块的影响力 (w_prev)。
精细控制: 在去噪的后期阶段(比如 t > 0.3),降低引导强度,让模型专注于细节优化,避免画面“饱和”或出现奇怪的伪影。
KV Cache: 缓存之前计算过的“块”的关键信息,新块生成时直接调用,避免重复计算,极大提升长视频生成速度。
蒸馏 (Distillation): 训练了一个“快捷方式”模型 (Shortcut Model),可以用更少的步数生成视频,实现更快的推理,适合需要快速出结果的场景。

强大的数据处理: 训练这么大的模型需要海量、高质量的数据。MAGI-1 开发了一整套数据处理流水线,包括视频切分、质量筛选(用了多种AI工具,如DOVER、RAFT光流、LAION美学模型等)、去重、以及用多模态大模型进行高级过滤和生成详细描述(包括逐秒描述)。

定制化基础设施: 为了高效训练和推理这个独特的模型,Sand AI 还开发了专门的分布式训练和推理框架,特别是 MagiAttention,用于处理超长序列和复杂的注意力模式。

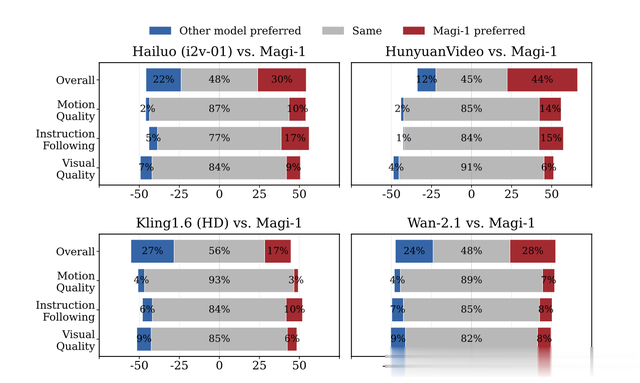
MAGI-1 的表现如何?
论文展示了 MAGI-1 在多个基准测试(如 VBench-I2V 和 Physics-IQ)上的优异表现:
运动质量和指令遵循: 表现突出,优于很多现有模型。
物理理解: 在 Physics-IQ 测试中(预测物理现象),V2V 版本得分远超其他模型,I2V 版本也名列前茅,显示出对因果关系和物理规律的良好理解。
时间连贯性: 自回归特性使得视频的时间连贯性更好。
视觉质量: 视觉质量也很高,但在某些方面(如人脸细节)与最顶尖的模型(如Kling)相比还有提升空间。
MAGI-1 通过其创新的块状自回归扩散方法,为文生视频领域带来了:
更强的因果建模能力真正的流式实时生成潜力更精细的多样化控制高效处理长视频的能力
它不仅在效果上达到了业界领先水平,更重要的是,它提供了一个统一、可扩展的框架,为未来视频生成的发展,特别是在交互性、可控性和长视频叙事方面,打开了新的大门!文章中的截图很多都是官方 demo 视频的截图,可以到官方网站查看 demo 视频。
magi1.aigithub.com/SandAI-org/MAGI-1
