随着DeepSeek的持续高热,DeepSeek的混合专家模型(MoE)也进入人们视野,那么什么是MoE模型,下文我们将针对混合专家模型(MoE)做一个简单介绍。
1.当AI模型开始「分科室看病」近年来,AI模型参数规模从亿级暴涨到万亿级,但计算成本也成倍增加。科学家们发现,让一个「全能大脑」处理所有任务,远不如组建一支「专家团队」高效。混合专家模型(Mixture of Experts, MoE) 应运而生,其核心思想如同医院的分诊系统:每个患者(输入数据)由最擅长的科室(专家模块)处理,再汇总诊断结果。
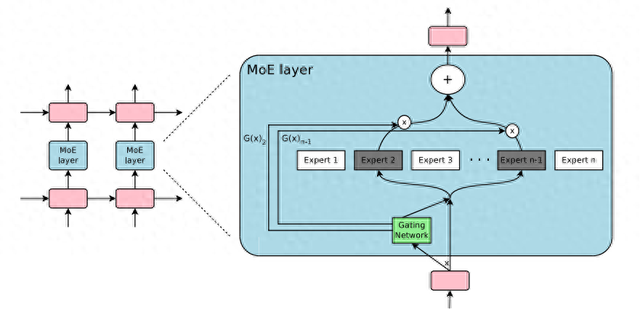
混合专家模型(MoE)架构
2.MoE如何实现「术业有专攻」?2.1 专家网络(Experts)模型包含多个独立的小型神经网络,每个专家专注学习特定数据特征。例如在图像识别中,可能有专家专攻纹理识别,另一个擅长形状分析。
2.2 门控机制(Gating Network)作为智能调度中心,可以直观理解为医院的分诊台,它实时分析输入数据的特性,动态分配任务。比如面对「斑马照片」,门控网络会激活「动物识别专家」和「条纹分析专家」。
3.3 动态计算(Dynamic Computation)每次推理仅调用部分专家,相比传统模型全程激活所有参数,计算量大幅降低。这种「按需调用」模式,让万亿参数模型也能高效运行。

MoE模型和Transformer模型的区别
3.MoE的「超能力」与「软肋」✅ 三大优势计算效率提升10倍:Google的Switch Transformer在同等算力下,训练速度比传统模型快7倍。模型容量突破天花板:单个MoE模型可集成数百个专家,参数量轻松突破万亿。任务适应性更强:专家模块可针对不同领域单独优化,实现多任务「一专多能」。⚠️ 三大挑战训练难度陡增:专家模块容易陷入「偏科」,需复杂算法平衡学习过程。通信开销巨大:百亿级参数的专家协同工作时,数据传输可能成为瓶颈。硬件资源消耗:虽然单次计算量少,但存储所有专家需要超大显存支持。4.主流MoE模型「英雄榜」模型名称
研发机构
核心突破
典型应用场景
Switch Transformer
2021年
首个将MoE与Transformer结合的模型
文本生成、机器翻译
GShard
支持6000亿参数的分布式训练框架
多语言翻译
Mistral 8x7B
Mistral AI
开源MoE模型,46.7B激活参数
代码生成、推理任务
DeepSeek-MoE
深度求索
146亿参数实现70B模型性能
中文NLP场景
以Mistral 8x7B为例,这个开源模型仅激活12B参数即可达到70B参数模型的性能,推理速度提升40%,成为当前性价比最高的MoE模型之一。
5.从实验室到产业化的飞跃在谷歌云平台,MoE模型已用于实时翻译系统,支持超过100种语言互译;医疗AI公司利用MoE开发出可同时处理CT影像、病历文本和基因数据的多模态诊断系统。而国内团队也在这一领域取得重要突破——深度求索(DeepSeek)公司推出的DeepSeek-MoE模型,凭借独特的架构设计,成为中文大模型领域的标杆。
DeepSeek-MoE的「中国智造」密码小身材,大能量:仅用146亿参数(相当于常规模型的1/5体量),在阅读理解、文本生成等任务中达到700亿参数模型的性能水平。中文理解「专家团」:专门针对中文语法、成语、诗歌等设计独立专家模块,在古文翻译任务中准确率提升35%。推理成本革命:通过动态激活约20%的专家网络,相比同性能传统模型,GPU显存占用减少60%,企业部署成本大幅降低。2023年,该模型在司法文书生成、电商客服等场景落地,某省级法院接入后,法律文书撰写效率提升4倍,错误率下降至0.3%以下。这种「轻量高效」的特性,让MoE技术从实验室走向产业应用的步伐进一步加速。
