说起未来的互动方式,越来越多的人会想到可以自由对话且理解人类语言的“智能助手”。
但当你尝试用中文和大多数助手对话时,它们总是显得有些“能听不能懂”。
这种“鸡同鸭讲”的感觉确实让人困扰。
不过,最近发布的Seedream 2.0似乎打破了这个局限,那么它究竟有多懂中文呢?
Seedream 2.0的双语解析与文字渲染优势我们来聊聊Seedream 2.0的绝活——双语解析与文字渲染。
在使用种种语言工具时,很多人都会遇到一个头疼的问题:非英语环境下,中文文字渲染总是不能尽如人意。
这是不是很让人抓狂?
Seedream 2.0的推出改变了这样的局面。
你可以用中文提示词生成图片,比如“猫头鹰在树枝上栖息,背景是夕阳下的树林”。
Seedream 2.0不仅能理解这些词,还能精准地将它们转化成惟妙惟肖的图像。
更厉害的是,它还能在图片中加入逼真的中文汉字。
这到底是怎么办到的呢?
如何在Seedream 2.0中生成高质量的图片实际操作中,我们发现使用Seedream 2.0真的是一种享受。
比如,你想生成一张“猫咪在草地上嬉戏”的图片,只需要用中文描述,系统就会给你一个几乎完美符合的图像。
我们测试了一下,用“摄影,特写,一只橙色虎斑猫,猫咪抬起前爪,眼神好奇……”这样的提示词,生成的图片简直让人惊叹。
不仅猫咪的动作栩栩如生,细节如毛发、草地、太阳光线等,也处理得非常自然。

不过,也不是完全没有瑕疵,比如背景中的云层景深还略有不足。
但总体来说,Seedream 2.0在这个方面的表现已经超出我们的期望。
技术细节解析:扩散式Transformer和ByT5字形对齐模型那么,Seedream 2.0是怎么做到这些的呢?
这里涉及到几个关键技术,首先是扩散式Transformer,它的自注意力层能够同时处理图像和文本信息。
这样,模型可以理解我们输入的提示词,并将它们和图像进行关联。
此外,针对中文和英文的不同特性,Seedream 2.0采用了多层感知机(MLP),并通过自适应层归一化来调节注意力和层之间的关系。
这让模型在处理中文提示时能够更加敏锐。
针对文字渲染的挑战,Seedream 2.0引入了ByT5字形对齐模型。
这个模型可以准确编码渲染文本的字形内容,确保汉字和英文字母的形态在图像中得以精确呈现。
这简直是中文用户的福音!
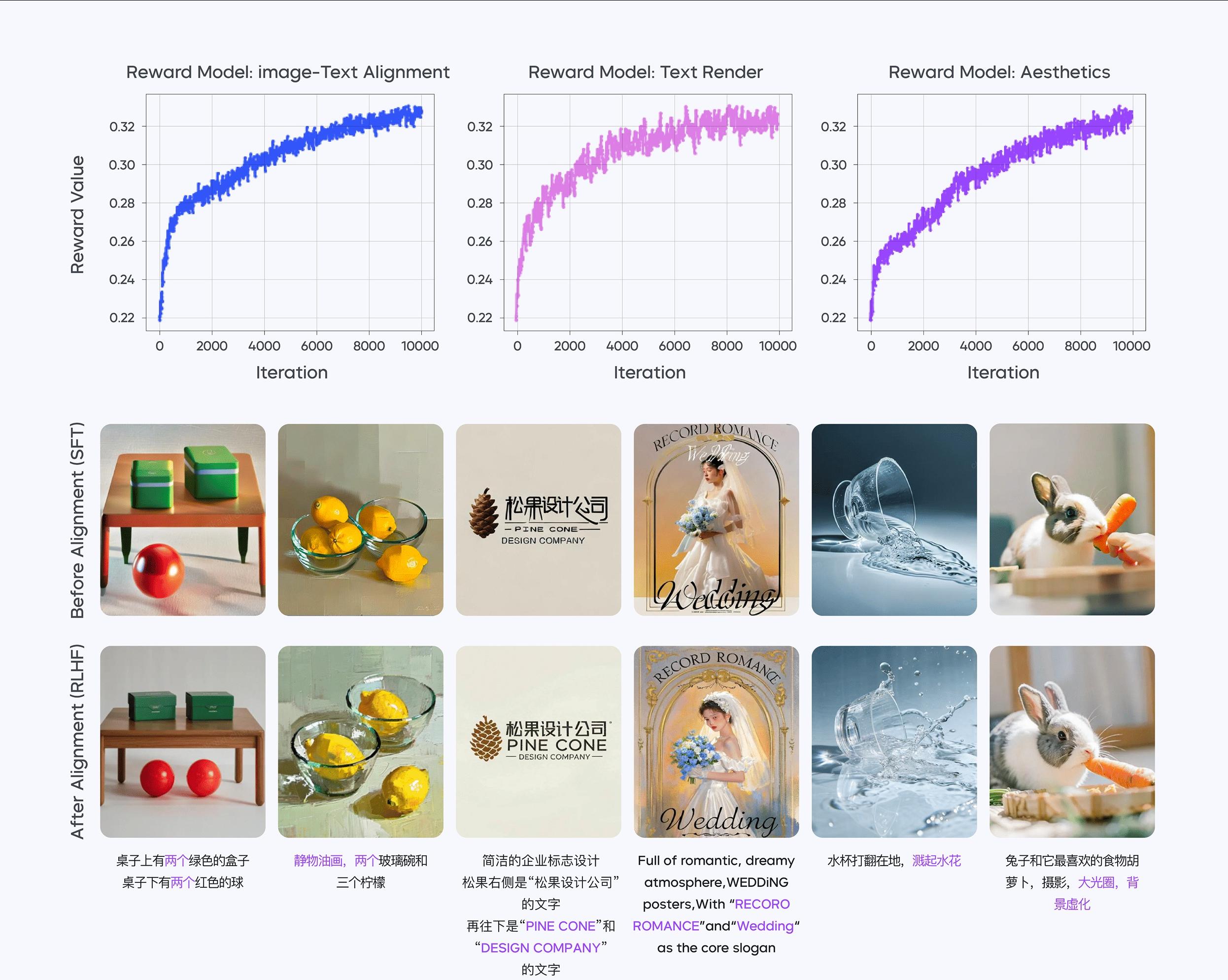
多阶段训练:提升模型表现的新方法不过,要达到今天的效果,Seedream 2.0的训练过程可不简单。
团队采用了多阶段的方法,持续训练(CT)、监督微调(SFT)、人类反馈对齐(RLHF)等方式来不断优化模型。
在RLHF阶段,他们引入了专为扩散模型设计的优化过程,包括偏好数据和奖励模型等。
这个过程大大提升了模型的图文一致性、美学效果和结构正确性。
用大白话来说,就是用户告诉模型“我更喜欢这样的图片”。
模型就会根据这些反馈不断改进。
还有一点值得一提,在实际应用中,用户普遍反映Seedream 2.0在中英文解析、图像细节呈现和文字渲染方面表现优异。
这不仅是因为技术细节的公开透明,更是因为团队在数据处理和训练优化上的不懈努力。
最终,Seedream 2.0不仅在技术上实现了突破,也在用户体验上提供了更多信心。
作为一款能用中文提示词,并且能生成中文汉字的国产大模型,它对于广大中文用户来说,确实是一大神器。
在未来,相信会有更多类似Seedream 2.0这样懂中文、能精准渲染中文内容的工具出现。
它们不仅仅是技术的进步,更是我们迈向更加智能、友好的数字世界的一大步。
在这个过程中,我们每个人都是见证者,也是受益者。
希望有一天,不管我们说什么语言,AI都能懂,并且给出最贴心的回应。
期待Seedream 2.0能在未来带给我们更多惊喜!

