

作者:张叶子
编辑:Mark
出品:红色星际(ID:redplanx)
头图:自动驾驶数据智能体系 “MANA(雪湖)”
12月24日,毫末发布Q4最新进展,其中的亮点是:
——A轮融资近10亿,晋升独角兽俱乐部;
——在乘用车方向,这个季度增加了三款车型,玛奇朵、拿铁、哈弗神兽,至此,毫末成立2年的时间里,搭载毫末产品的乘用车车型达到5款;
——小魔盒辅助驾驶里程已经突破400万公里,再次刷新前一季度的百万里程成绩单;
——发布数据智能系统MANA,真正意义上完成智能数据的闭环,城市NOH 34分钟无接管“一镜到底”曝光。
毫末常规的技术日也和特斯拉一样,改名为AI DAY,显示了自己在人工智能和自动驾驶方面的雄心,实力能否撑得起雄心,我们以Q4最新发布为线头来具体扒一扒。

1. 数据智能系统“MANA(雪湖)”
冬天是适合思考的季节。
在三体中,罗辑被选为面壁人之后,遁世到一片只有森林、雪山、湖泊、木屋、壁炉、红酒的世外桃源,在那里,它和庄严度过了梦幻的五年。
五年之后,当所有面壁者都被破壁之后,庄严和孩子被“人质”,罗辑不得不直面人类危机,寒冬深夜,罗辑一人在结冰的湖面上散步,掉入冰窟,窒息中,他看到旋转的黑暗星空,顿悟宇宙社会学真相,总结出黑暗森林法则,发出恒星咒语,为地球人扳回一局。
这个湖是天才思想、战略转机横空出世的地方,然而在三体中,这是一个没有名字的地方,因为女神庄严的一句话,不需要知道它在世界上的具体地点,知道了,感觉离世俗的距离就近了。
在中国西藏,有这样一个地方,叫Mana(雪湖)。毫末用这个名字命名数据智能系统,用意十分明显,希望在这里,数据能真正变成知识和智慧,长成“破壁”自动驾驶的战略武器。
智能系统是一家人工智能公司的核心竞争力,恰如一个学霸天才的大脑,拿到信息数据的原材料,学得又快又深,还可以举一反三,不断进步。
而且这种数据对毫末来讲,早已不是实验室级别的训练集、也不是你知道它去哪也知道做了什么事情的采集车数据,而是真正量产后来自真实世界千奇百怪的数据。
毫末的MANA系统在这个时间节点推出,完全基于企业面对的现实需求,而非口号。这个现实是什么?
四百万公里的现实里程带来令工程师兴奋的数据洋流,让算法和架构迅速迭代,丰富饵料投喂之下,自动驾驶快鱼迅速调整底层架构。
与此同时,未来可预期的海量数据(长城爸爸的掌上明珠,没有猜忌链,没有悬念,稳稳地上车)带来的挑战也要求底层构架能Hold住这种变化,存储、传输、计算训练、验证、仿真、标注等等,各个方面都对系统提出更高要求(就在发布日前一天官宣融资10亿,钱也有了,PK特斯拉超算中心也安排上了)。
MANA架构
下面我们来了解一下MANA的具体构架。
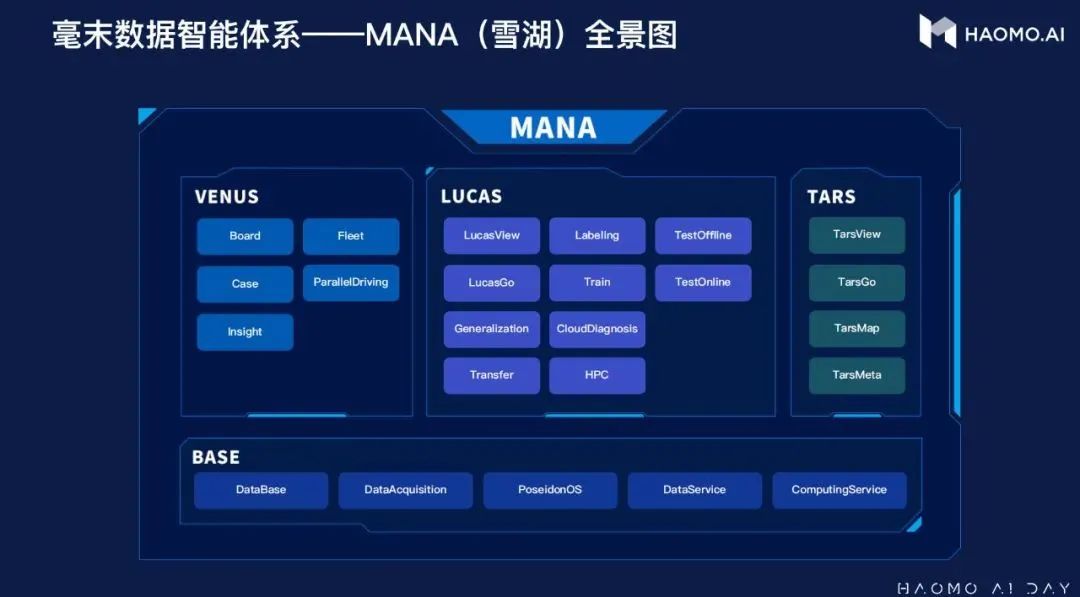
(毫末智行数据智能体系 “MANA(雪湖)”)
MANA是毫末体系完善的研发体系,由四个大部分组成,分别是:数据看板系统(VENUS)、车端系统(TARS)、大规模不间断学习系统 LUCAS(Large Scale Autonomous Continuous Learning System)、底层系统(BASE)。
VENUS是数据看板,我们去展示、审查、洞悉数据可视化的能力。
TARS是车端能力,包括TrasView(感知),TrasGo(认知),规划决策控制、Map(地图定位),Meta(仿真引擎),它们更多为车端算法服务。
LUCAS是基于数据学习研发的一套系统,主要有诊断、分析、检索三个模块。核心是数据驱动,通过迭代数据来自动化地迭代模型。目前业内普遍迭代模型的思路是利用工程师来人工分析错误,将错误进行提炼总结,然后设计出合适的方案。这种方法在错误数据频次高、共性多的时候能够较好地解决问题,但面对海量数据和长尾,就会无能为力,LUCAS解决了这个问题。
BASE是中间件、数据存储、数据计算相关的服务。
四部分的功能分别是:
TARS解决的是从0到1的问题。
LUCAS里主要解决大规模泛化问题,从0到1之后如何从1到N,包括感知泛化、认知泛化、车型泛化、芯片间泛化,标注、训练,云端自动问题的分拣、诊断,以及一些云端和离线在线的评测。
BASE表达一种通用性,不管是车端做从0到1的原型研发,还是做大规模量产之后从1到N的泛化,都依赖于BASE。
MANA意义
表面上看,似乎每个自动驾驶公司的智能系统构架都大同小异,在之前也有一套数据系统运作,那Q4大力推出全新系统,与之前一直存在的有何不同呢?
据技术Leader介绍,不同主要在两个方面:首先,之前的各个子单元虽然存在并运作着,但存在很多配合不好的环节,新系统对这些地方做了重新的整理和规划。

(毫末智行MANA(雪湖)系统与特斯拉对比图)
比如说LUCAS和TARS之间的配合。核心在于LUCAS和TARS之间的交互和配合,感知和认知是完全两套不同的LUCAS和TARS的配合方法,感知比较常见的是TARS提供模型,LUCAS提供数据,1+1最后达到N的效果。在认知上不一样,相当于LUCAS提供数据里学到的毫末想要达到的目标,TARS通过强化学习、模仿学习把它再学习过来,最后部署到车端。
第二,梳理出了清晰完善的理论框架,相当于公司技术研发的一套顶层设计。在任何一个组织里,顶层设计的重要性不言而喻,没有顶层设计,公司的长短期目标、部门任务、业务权责无法有序展开,大家都不知道怎么思考。有了MANA,数据智能处理能有序循环起来,组织也能更好分工协作,培育出自我生长的力量。
2. 技术亮点
感知:从后融合到前融合
感知方面,业界和毫末的通用做法是:拿到一张图片,通过一个骨干学到不同的特征层,再基于不同的Head区隔不同任务,比如说一些分割,比如说一些道路元素,比如说一些障碍位等等。包括点云也一样,像小鹏和毫末的下一代车,搭载有激光雷达,多个激光雷达之间拼到一起,完成分割和障碍物检测功能。
一张图片描绘相关的东西,但是前视相机不会和侧前相机、激光雷达有什么互动,更多是在后融合的阶段把目标结果进行融合。这样的做法存在很多问题,最大的问题是——它没有很好地利用好多个传感器之间的配合和交互。
既然后融合弊端这么大,为何还能成为业内主流呢?
原因是之前大家都跑高速,前面有一个摄像头,一个Mobileye,很多主机厂做PNC相关的事情就够了。
这些量产产品大多就前面有一个摄像头,它所谓的融合是这个相机和毫米波雷达的融合,这种融合相对比较简单的。
但到了复杂的城市,光看前面一个摄像机肯定不够,360度都要视觉和点云。以毫末的车为例,硬件里有12个摄像头,还有激光雷达和毫米波雷达,那就是12个摄像头之间的融合,难点会变很多。
那么,如何把这些传感器的信息有效融合到一起?
毫末采用的方法是前融合的Tensor map思路。先是不同的相机、点云提取特征,提取到张量的层次,在这个环节下再进行拼接,拼到俯视图的视角,3D的维度,在3D维度上再去检测相关的障碍物、车道线等等,形成一个Tensor map新的模式。
通过这种方式就可以有效解决后融合所引发的跨相机的追踪,跨相机障碍物的分裂等等这种问题,可以提高复杂场景下对于障碍物和车道线感知能力。
此外,还有一个和其他的一些国内公司稍微不太一样的点是——毫末会直接预测深度信息(和特斯拉一样)。很多公司采用的技术方案是——模型只预测2D的信息(比如说图像上像素点上的信息),再通过后处理的方法(比如说IPM),通过一些几何关系去倒推计算深度信息。
这个方法毫末之前尝试过,在高速上面没有什么问题,在城市场景里面效果不太好,因为高速上车少,也比较简单,车也没有什么特别诡异的、逆行的,而在城市里面这种效果就会很差,它的测距精度不太高,深度信息回归的不好。
和特斯拉不一样的是,毫末在预测之前先把特征维度就做了一次融合,基于这个融合之后的特征,再去预测这个东西是障碍物还是车道线,相当于是一个后融合。
那么,两者的效果如何呢?
公司每隔一段时间都会做竞品测试,目前来看,两者都很不错,但也都是刚刚开始(特斯拉最近才将前视和前玻璃融合),可以相互借鉴,取长补短。

(毫末智行Transformer与CNN深度融合理念)
正如公司CEO顾维灏所说,Transformer技术可以帮助自动驾驶感知系统更深刻地理解环境语义,与CNN技术的深度融合将会解决AI大模型量产部署的难题,Transformer与CNN深度融合将会成为自动驾驶行业下半场竞争的关键技术。
而这个融合也是MANA(雪湖)系统的精华之处。
认知智能:让人工智能更像人
认知智能,这又是今年的一个热门提法,但究竟是什么,大部分人还是一头雾水,为什么呢?和感知一比较就知道了。
感知要解决的是从传感器信号中重建客观世界的问题,感知当前相对成熟,虽然大家感知做的程度不太一样,有些人做得好,有些人做得一般。但是感知它有最重要的特点,它有清晰标准。客观世界什么样的,你看到的感知出来的结果就是什么样的,完全白盒的,没有歧义,剩下的就是用巨量的数据去保证覆盖掉所有的Corner Case。
而认知要解决的是从客观世界到驾驶动作的映射问题,它本身就没有这种共识性的衡量标准。比如说一个人现在要左转,对向正好来车,老司机一脚油就过去了,而对于刚拿本的司机可能就选择让行。那在安全的前提下,究竟哪种是更好的驾驶策略呢?

(MANA认知智能数据图片)
认知智能的核心是通过大量数据在复杂场景里学习人开车的规律和人开车的方法,用这个数据来指导算法和迭代。
他要解决的问题是让机器达到像人一样开车的体验,而非充满机械化痕迹。
虽然目前不少公司也都在朝这个方向做,但发展阶段存在差异,大部分公司还停留在从传统机器人理论衍生出来偏几何学、偏机器人运动学的阶段,通过规则式的、求解的方式来进行轨迹规划。比如精确测量出来这个车距离我20.5米,那个车距离我16.8米,所以我就要这么走。
而显然人在开车时并非如此,而是在一些基本的社会常识和驾驶规范的基础上,按照自己的目的更智能地去选择自己的驾驶行为,而不是通过纯粹的数学计算来驾驶车辆。
通过复杂的认知算法体系,毫末想要实现的第一步是,让自动驾驶符合大众的口味,第二步则是通过用户画像,实现自动驾驶司机的千人千面。这点很容易理解,先要达到平均分,让大部分人感觉OK,然后让各种人都满意。因为高级白领林妹妹、肌肉达人李逵、霸道总裁周瑜开车、小鲜肉唐僧的驾驶风格和对驾驶体验的要求肯定是非常不同的。
所以毫末专门建立了一套体系。这套系统包括三个向量,安全、舒适、高效。
以安全为基础,通过将场景和动作被数字化后,从大量的数据中提炼出舒适和高效的量化标准,这样就可以避免纯机械的操作,让用户感觉是老司机在开。
3.进阶之路
从原始社会进入封建社会,看天吃饭的原始人不懂,面对同一片土地,为什么有的部落冬天也能吃到粮食了。
从封建社会进入资本社会,地主们不明白,为什么土地、劳动力、生产工具都在我手里,还是被资本家干翻了。
一如以后新一茬的Old Money不懂,资源都在我手里,怎么就被革命了呢?
原因高中课本说得很清楚,新的生产要素出现,带来生产力和文明形态的大变革。
而数据就是让人类文明产生第四次大变革的那个新生产要素。
为了表达对数据信仰的重视程度,毫末用“思想钢印”来表达它,每个三体读者都知道思想钢印的威力,它代表深入骨髓的坚信,不需要再去接受任何理性判断的审视。
但在通往L5的路上,信仰需要正确的战略思想,风车战略和渐进路线是毫末的选择。
风车战略
什么样的公司能成功?一定是掌握规律并最领先于对手的,Why?
在这里,黑暗森林两条基本公理同样适用:
第一,生存是文明的第一需要。
第二,文明不断增长和扩张,但宇宙中的物质总量保持不变。
毫末对自动驾驶实现的判断是自动驾驶商业化三定律:
第一,从低速到高速;
第二,从载物到载人;
第三,从商用到民用。
从目前来看,封闭场景的餐厅酒店服务机器人、仓库仓储机器人、家庭的扫地机器人都已经被商业化。开放场景的无人物流也在今年快速走向商业化。
先从最快商业化的无人物流小车、乘用车辅助驾驶、智能硬件三个战略主战场入手,取得造血能力和数据能力。但核心是打造自己的核心——数据智能,在总量有限的市场上,争取领先优势,形成对资金、人才、数据迭代的马太效应。
董事长张凯对自动驾驶的另一个判断是:对于赛道参与者而言,在2022年没有形成自己相对稳定的商业模式是致命的。
从外部环境来看:
第一,与前几年智能手机市场比较类似,行业将会从最初的倒三角型形态向呈现T字形态转变,头部效应越发明显。2022年,有高效、低成本的数据智能体系,实现规模量产的企业与其他企业的差距将有显著拉开。
第二,数据安全与数据合规将进一步增加自动驾驶数据智能体系的闭环难度和成本,对于没有在此之前打好基础的企业,随着2022年国家层面将会出台细则强制执行数据安全上位法,完成同样的体系建设,难度和成本骤增。对于新进入者,更是相当与加高了行业进入壁垒,机会窗口几乎已经关闭。

(毫末智行董事长张凯)
从各个方面看,2022年将是毫末拉开与友商差距的一年。张凯提到的要打赢“无人物流车”、“城市场景辅助驾驶”和“数据智能”三场战役,都有比较坚实的基础。且公司目前已经准备好了充足的技术弹药和资金,营业额已达数亿元,加上刚融资的近10亿人民币。
整个毫末团队都在摩拳擦掌准备2022年的三大战役。
“无人物流车”方面,实际上智能硬件核心就是智能底盘,而毫末只是把这个智能底盘用在无人物流车上,其实最早公司有一个产品做Mini bus,但当时的判断,Mini bus的商业机会来的更晚一些,因此暂时封存了Mini bus的很多技术,直接把底盘拿出来更多的去拓展无人物流。
市场上现在很多初创项目做自动驾驶底盘,而究竟做得好不好,取决于团队基础能力:第一,是不是真的能设计出来,第二,取决于它的供应链能力,是不是真的能够做低成本。本质上,汽车硬件拼的就是规模效应。而长城的背景让毫末能迅速推出十多款相关硬件产品。
正如美团的李达总所说,市场上找了一圈,最后发现毫末的底盘最好。
12月份,毫末智行迎来第1000辆末端无人物流车的量产下线,2022年,毫末智行团队打算将无人物流车项目扩大3倍,达到3000辆(这些计划都是根据合作伙伴的2022年规划)。
这些并不是拍脑袋拍出来的数据,而是通过团队沙盘推演推出来的。

(毫末智行智能驾驶产品路线图)
其次是城市辅助驾驶场景之战。2022年,乘用车辅助驾驶的竞争将会进入下半场,下半场的竞争主要集中在城市开放场景的领航自动驾驶。毫末智行为此储备了小魔盒3.0计算平台、新一代AI自动驾驶技术、MANA数据智能体系,以及其最强的技术工程化经验。
最后是数据智能MANA(雪湖)系统,MANA的推出将帮助毫末在数据处理和智能分析上建立更大的优势。
打破自动驾驶分级思维
长期以来,自动驾驶分级是各种迷思和争论的重灾区。
比如宣传中的PK,你说L2、L2+、L3、L3+,和孔乙己写茴香豆似的。再比如行业中L2搜集的数据L4到底能不能用的问题。
那L2到L4,对毫末来说,数据到底能否通用呢?
公司技术Leader告诉笔者,一方面,从硬件和软件开发上来看,并没有看到L4和所谓的L2之间有什么区别,唯一的区别可能在于用户接管策略的不同。比如说用户不扶方向盘,所谓的L4不扶就不扶,无所谓,可能所谓的L2来说,你不扶我就提醒提醒你等等。这些简单来说是一些软件的开关,区别不在硬件和算法上。
另外,不管L几都有自己的数据价值,问题的本质不在于数据本身的质量和结构,而在于怎么能够更好地应用。
所以毫末选择先要盯着更多功能、更好的用户体验去做。在之前的技术日上,CEO 顾维灏也曾经说过,做L2的,包括特斯拉在内,无论是硬件设计、软件开发、还是产品策略,都是瞄着更高级别的,对用户带来更好体验的,往更好的目标去做的。
在目前来看,用户并不关心L几,而是更关心安不安全、体验好不好、接管率高不高这些指标,所以,这个分级的概念也正在淡化。


