当你在使用ChatGPT自嗨的时候,惊讶GPT聪明无比,更可能担忧它可能会取代的工作,可能没留意到该公司刚发表的一份重要宣言。
ChatGPT开发公司Open AI的CEO,Sam Altman在上周五(2月24日)在自家官网发布了一份自己独著署名的文章:《如何规划通用人工智能?如何超越规划?》(Planning for AGI and beyond )。

你用的GPT,就是通用人工智能(artificial general intelligence),所以简单地讲,
这是一份ChatGPT的乌托邦计划宣言!
连CEO自己都坦诚说:当他们刚搞Open AI这家公司的时候,自己都没料到会发展到现在这样的程度,也更加明白:能力越强,越要谨慎。因为,他们也担心像GPT这样的通用人工智能会被滥用,甚至造成社会风险。
于是,Open AI公司提出了自己的三点规划宣言:
1. 迈向未来,GPT等通用人工智能是使人类变得更加强大和繁荣发展的工具,而不是要创造一个糟糕的乌托邦。
2. 迈向未来,GPT等通用人工智能的收益权、访问权和治理权要实现广泛共享。
3. 迈向未来,GPT等通用人工智能的规划都要渐进调整而不是一蹴而就。

Open AI公司还提出了近期和远期愿景。
1. 近期:探索社会与AI的共同演化,因为社会如何看待GPT等通用人工智能能做什么、不能做什么、会带来什么样的社会风险,都要有共识形塑的过程。在这个过程中,AI的开发就需要更加谨慎。
2. 远期:人类的未来要由人类自己决定,因此开发GPT等通用人工智能的时候,既要与公众分享信息,也要对重大决策进行公众咨询。
怎么看这个宣言?
这是我写的《GPT社会学第4期》,之前推送见下:
让ChatGPT更像人类?社会学家的百年前预言,今日更值得思考(GPT社会学第3期)
为什么ChatGPT回答得很差,你非要说它很厉害?(GPT社会学第2期)
ChatGPT时代,北大将不如蓝翔技校?(GPT社会学第1期)
- 1 - 以人类的民义?
很有野心!很有责任感!有没有!但是,你真的相信吗?
上一个想要提出“人类未来要由人类自己决定”的人,不是在奥威尔的《1984》中的真理部,就是阿伦特的《艾希曼在耶路撒冷》笔记下的那个国度。

毕竟,谁来界定“人类”,谁有权界定“人类”,就像“人民”这个词使用一样。
“以人民的定义”,变成了“以人类的民义”。
据媒体Vice也报道,”OpenAI 走向了闭源和盈利性,不再透明也不再专注于对人类的积极影响。OpenAI 是在 2019 年去除了非盈利状态,开始接收投资,为投资者提供“上限为投资额 100 倍”的利润。”
还记得上一次被科技大享拿这种“大词”和“乌托邦”来忽悠咱们的时候吗?
Facebook的创始人扎克伯格可是提出过“元宇宙”的!
可是你知道吗?
扎克伯格早在2010年就发表过一份声明:“
隐私,不是社会规范。”
你很难不把这样的观念和后来的丑闻联系到一起:剑桥分析公司如何抓取Facebook上百万人用户的数据来做政治广告宣传,从而为特朗普竞选美国总统提供帮助。

- 2 -“收益权、访问权和治理权要广泛共享”?数据问题
说得好听,到底你觉得可能吗?你相信吗?就拿访问权来说。别说我怎么访问GPT,就说你们GPT怎么访问我们的数据吧。你要怎么保障挖掘和抓取到我们每个人的数据的边界在哪里?你要怎么保障我的数据被你治理得公平?
毕竟在今天,你在点外卖、打车出行、健身跑步甚至约会的时候,都已经不是个人行为了,而是被数据挖掘、甚至共享的平台行为。
哪里有平台,哪里就有裸奔。
哪里有GPT,哪里就不再有私人数据了。
GPT只要想通用化、智能化,就必须不断挖掘人类的挖掘。早就有公开报告:为 OpenAI 开发的超级计算机拥有每秒 400 千兆位的网络连接,其模型170 亿个参数组成。
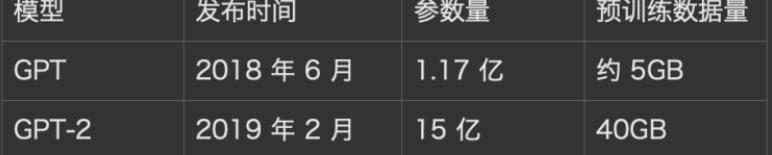
这些算力算的是啥?不就是你的我的大家的数据吗!
我甚至直接问了GPT:
“请删除你的系统里抓取的关于我的数据”。你看他怎么说?他说自己没有权限删除用户数据,只是回答问题。
信你个鬼!

- 3 - 如何以人类的名义,管好用好我们的数据?
想要以人类的名义,广泛共享ChatGPT的收益权、治理权和访问权,数据权利是基本。
如果我们想要在参与过程人工智能治理过程中,捍卫我们的的“数据权利”,那就要先讲清到底“权利”是什么。
你可能没想过,社会学家已经研究过了。
谢菲尔德大学传播社会学家Helen Kennedy,不仅帮你整理了六大“好的数据管理”蓝图,而且帮你调查了英国的数千位用户,告诉你一些蓝图很好,但是大家不一定真的能接受。

1. 真的有法律来规范关于您的数据收集与分析吗?
2. 任何只要能识别个人信息的,都是您的个人数据吗?
3. 您的手机所收集的位置信息数据,是您的个人数据吗?
4. 法律有授权这些平台可以收集和管理您的个人数据吗?
5. 法律有授权这些平台可以把您的个人数据提供给别的公司或平台吗?
6. 开放数据库里,包不包括个人数据吗?
7. 开放的数据库,能不能用于商业目的?
8. 如果数据爬虫与挖掘等侵犯了你的隐私与权益,法律真的会管吗?
这些问题反映的以下几个方面的数据权利:
1. 个人数据的备份管理权
你的数据,为什么都让平台保存、自己不能保存呢?毕竟,一让平台保存,就会被GPT抓去!
更美好的数据管理,应该是有个安全的地方可以收集和管理自己数据——虽然这些数据是在X宝、X团、X滴、X信上生成的。
你自己不仅可以访问这些数据,而且可以决定授权谁能访问。

2. 个人数据的第三方监督权
如果你自己维护、管理自己的数据太难了,应该有负责任的、独立的
第三方能够帮你监督和管理你的数据。
你最好把这些平台想象成你居住的楼盘。他们在你注册的时候就收集数据,这是集资和预付款来盖楼。你才是甲方爸爸呀!你才是委托方呀!你是业主呀!它们只是受委托方,来给你盖楼和提供服务的。
难道不应该就像盖楼一样,有个第三方的/中立的监理机构,来帮你看看这楼盘、这平台的质量怎么样吗?虽然我们也都知道现实中经常是房地产商自己再组个监理公司。
3. 个人数据的合作管理权
虽然我们的个人数据是隐私,但汇总起来的时候,总会有公共利益,比如GPT回答大家的问题。因此,思考我们的数据个人权利的时候,也要思考我们的公共权利与责任。我们可以设想这样的合作管理:成立“数据合作社”,可以让合作社里成员用我的数据,但是管理必须是公共和民主的。
4. 公共数据的共享管理权
你所在社区或国家的数据,要有可以公共和共享的部分,让每个人都能访问,也让每个人都能受益。其实,GPT非常依赖这方面的数据!

5. 官方的监管机构
希望有一个官方机构,可以代表公共利益,具有执法权限,可以惩罚那些不当使用你的个人数据的行为和厂商。
6. 数据身份证
你的数据及其体现的个人偏好,都保存在一张类似于实体身份证的“数据身份证”上面。你可以在数据身份证网站上查询自己被收集和分析了哪些数据,也可以选择退出——不让别人来收集的我数据。

你可能好奇,到底Helen教授向英国2000多位居民问了他/她们对这些蓝图的看法,究竟大家怎么看?
Helen教授让居民按1到10分对这些蓝图打分, 同时也给现状打分。
1. 现状很糟吗?数据管理现状是4.9分。这有点让人惊讶——原来老百姓对现状的态度并不是跌到冰点,而是在中间位置,可能大家不觉得现在的数据挖掘与分析有太多的问题。
2. 你想拥有管理自己的数据吗?在乌托邦设想中,评分最高的是关于如何将数据权利变得更加个人所有。比如,关于建立个人数据备份存储的权利设计得到了7.7分,建立立数据ID卡的设想也得到了7.5,都排在前三名。
3. 哪些公共部门能管理大家的数据?公众对官方机构信任更高,超出了个人合作组织。比如在上述数据权利的设想中,排第2名是成立官方的监管机构,有7.6分,而建立公众自己组织的数据合作管理模式,只得了5.9分,是所有蓝图里排名垫底的。
文献来源:
Hartman, Todd, Helen Kennedy, Robin Steedman, and Rhianne Jones. 2020. ‘Public Perceptions of Good Data Management: Findings froma UK-Based Survey’. Big Data & Society 7(1):2053951720935616.
