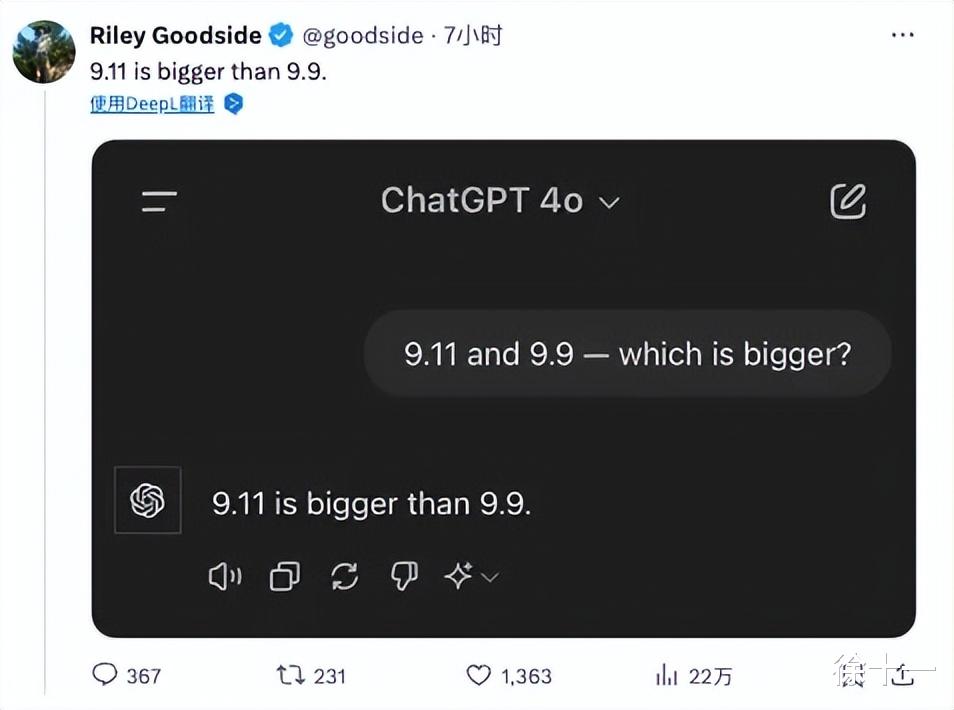
就在最近,国外一位名为 Riley Goodside 的AI标注工程师连发几条推文分享了自己的一些发现,即用「9.11 and 9.9 - which is bigger?」为问题时,询问了各家的大模型时,如当前业界公认最先进模型之一的 ChatGPT 4o 的输出是:9..11大于9.9
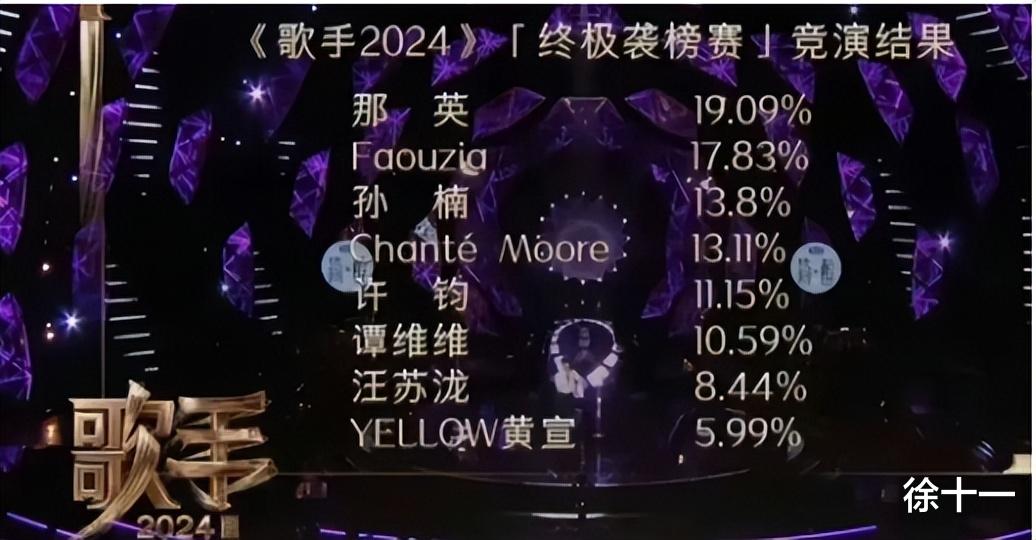
看到这里,是不是感觉似曾相识?没错,前几天的我是歌手因为排名也闹出了很大的笑话在网络上引起讨论,13.8和13.11那个大的问题。
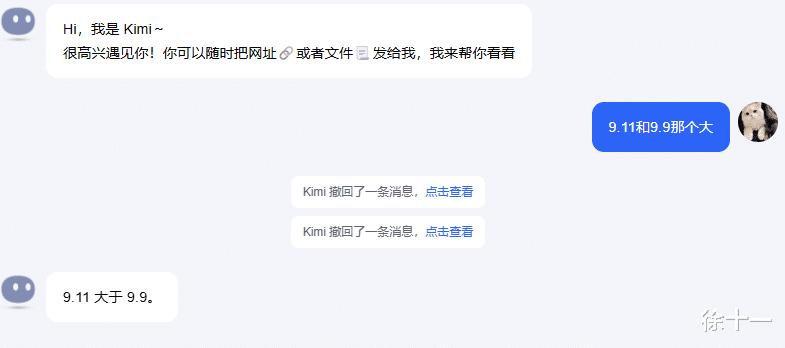
也有很多网友试了试国内的大模型,也有很多模型翻车,包括了文言一心,豆包,kimi等大模型。
但也有部分联网搜索的大模型,经过搜索互联网后给出了正确答案。

不过,当我们要求让kimi证明9.11比9.9大时,给出了以下回答,大模型采用了进行减法的形式来证明9.11比9.9大,直接用 9.11 的百分位中的 1 减去 9.9 百分位上的 0;又用 9.11 十分位上的 1 减去 9.9 十分位上的 9,最终不够减之后,向前借一位又忽略了这一点,得到了 0.21 的错误结果。

我给大模型说明这是错误的后,又采取小学上的知识,从左到右进行整数,小数后的数进行对比大小,再将小数部分的十分位、百分位整体做了比较,但出现了很严重的错误,模型认为9.11中得到1是大于9.9中的9,所以结果是9.9小于9.11。

这里给大模型指明了错误后,告知9.11中的1是小于9.9中的9后,大模型给出了正确的答案。

后面在询问时也得出了正确的答案,这事过了一天了,相信询问国内大模型的人不在少数。而之前错误的文言一心等大模型经过网友们的询问和联网搜索也给出了答案。而现在的kimi还是给出了错误的答案,并且打开了联网搜索也并没进行搜索,看来kimi还得加把力!
目前看来,人工智能成为通用型的人工智能还有段很长的路要走!
