·内森·汤普森,博士
·11月8日2016

项目反应理论(IRT)代表了心理测量学领域的一项重要创新。虽然现在已经50岁了——假设“出生”是经典的Lord and Novick(1969)文本——但它仍然没有得到充分利用,对许多从业者来说仍然是一个谜。那么什么是项目反应理论,为什么会发明它呢?
项目反应理论不仅仅是一种分析考试数据的方法,它还是一种推动设计、构建、交付、评分和分析评估的整个生命周期的范例。它比它的前身经典测试理论复杂得多,但也要强大得多。IRT需要相当多的专业知识,以及专门设计的软件。点击下面的链接下载我们的软件Xcalibre,它为实施IRT提供了一个用户友好的可视化平台。
驱动因素:经典测试理论的问题经典测试理论(CTT)已有大约100年的历史,并且仍然被普遍使用,因为它适用于某些情况,并且它足够简单,可以被许多人使用,而无需接受过正式的心理测量学培训。大多数统计数据仅限于均值、比例和相关性。然而,它的简单性意味着它缺乏处理许多非常重要的测量问题的复杂性。这里仅举几例。
·样本依赖性:经典统计量都依赖于样本,并且在不同的样本上不可用;来自IRT的结果在线性变换中与样本无关(即,不同能力水平的两个样本可以很容易地转换为相同的尺度)
·测试依赖性:经典统计与特定的测试形式相关联,不能很好地处理由多个形式、线性动态测试或自适应测试引入的稀疏矩阵
·弱链接/等值:CTT有许多方法可以链接多种形式,但与IRT相比,它们很弱
·衡量学生的范围:经典测试是为普通学生建立的,不能很好地衡量高或低的学生;相反,非常困难或容易的项目的统计数据是可疑的
·CTT 无法进行垂直缩放
·缺乏猜测: CTT不能解释对多项选择题考试的猜测
·评分:经典测试理论中的评分不考虑项目难度。
·自适应测试:在大多数情况下,CTT 不支持自适应测试。
在此处了解有关CTT 和 IRT 之间差异的更多信息。
那么什么是项目反应理论呢?它是一系列数学模型,试图描述考生如何对项目做出反应(因此得名)。这些模型可用于评估项目性能,因为描述本身非常有用。然而,项目反应理论最终做了更多的事情 - 即解决上述问题。
IRT是模型驱动的,因为假设有一个特定的数学方程。有不同的参数可以根据不同的需求塑造这个等式。这就是定义不同 IRT 模型的原因。
项目反应理论的基础IRT的基础是由项目参数定义的数学模型。对于二分项目(得分正确/不正确的项目),每个项目都有三个参数:
a:判别参数,衡量项目在低考生和高考生之间差异的指标;通常范围从 0 到 2,其中越高越好,尽管没有多少项目高于 1.0。
b:难度参数,项目适合哪个级别的考生;通常范围从-3到+3,0是平均考生水平。
c:伪推理参数,它是较低的渐近线;通常侧重于 1/k,其中k是选项数。
这些参数用于以图形方式显示项目反应功能(IRF)。下面是一个示例 IRF。此处,a 参数大约为 1.0,表示一个相当有区别的项。b 参数约为 0.0(曲线中点所在的 x 轴上的点),表示平均难度项;中等能力的考生有60%的几率正确回答。c 参数约为 0.20。

这在概念上意味着什么?我们试图模拟考生对项目响应的交互作用,因此命名为项目反应理论。将 x 轴视为标准正态量表上的 z 得分。能力较高的考生更有可能做出正确的反应。+2.0(第 97 百分位)的人有大约 94% 的几率获得正确的项目。与此同时,-2.0的人只有37%的几率。
当然,参数可以而且应该因项目而异,以反映项目性能的差异。下图显示了五个 IRF。深蓝色线是最简单的项目,b 为 -2.00。浅蓝色项目是最难的,b为+1.80。紫色的c=0.00,而浅蓝色的c=0.25,表示它很容易被猜测。

这些IRF不仅仅是一个漂亮的图表或描述项目性能的方式。它们是实现前面提到的这些重要目标的基本组成部分。接下来...
使用项目反应理论改进评估项目反应理论将IRF用于多种目的。这里有一些。
1.解释和提高项目性能
2.使用最大似然法或贝叶斯方法对考生进行评分
3.Form assembly,包括线性动态测试 (LOFT) 和预等效
4.计算考生分数的准确性
5.开发计算机化自适应测试(CAT)
6.Post-equating
7.项目功能差异(查找偏差)
8.数据取证以查找作弊者或其他问题。
除了用于单独评估每个项目外,IRF还以各种方式组合在一起以评估整体测试或形式。两种最重要的方法是条件标准误差测量(conditional standard error of measurement,CSEM)和测试信息功能(test information function,TIF)。测试信息功能越高,测试提供更多关于考生的测量信息;如果在一定范围内考生能力相对较低,则这些考生没有得到准确的衡量。CSEM是TIF的反面,并且具有可用于置信区间的可解释优势;一个人的分数加上或减去SEM的1.96倍是其分数的95%置信区间。下图显示了我们FastTest平台中form assembly过程的一部分。
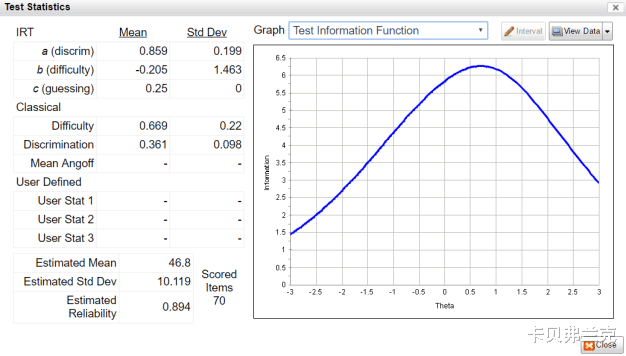
那么,为什么这很重要呢?让我们回到经典测试理论的问题。为什么 IRT 更好?
·尺度的样本独立性:经典统计都是样本依赖的,并且在不同的样本上不可用;IRT 的结果在线性变换中与样本无关。两个不同能力水平的样本可以很容易地转换到同一个量表上。
·测试统计:经典统计与特定的测试形式相关联
·稀疏矩阵是可以的:经典检验统计不适用于由多种形式引入的稀疏矩阵、线性动态检验或自适应检验
·链接/等值:IRT具有更强的等价性,因此,如果您的考试有多种形式,或者您每年使用新形式提供两次,则可以在分数的可比性方面具有更高的有效性。
·衡量学生的范围:经典测试是为普通学生建立的,不能很好地衡量高或低的学生;相反,非常困难或容易的项目的统计数据是可疑的
·垂直缩放:IRT 可以进行垂直缩放,但 CTT 不能
·缺乏猜测:CTT不考虑多项选择题考试的猜测
·评分:经典测试理论中的评分不考虑项目难度。使用IRT,您可以在任何一组项目上对学生进行评分,并确保其处于相同的潜在量表上。
·自适应测试:在大多数情况下,CTT 不支持自适应测试。自适应测试有自己的好处清单。
·错误表征:CTT假设每个考生的分数(SEM)中都有相同数量的错误;IRT认识到,如果测试都是中等难度的项目,那么低或高的学生将有不准确的分数
·更强大的表单构建:IRT 具有构建表单的功能,使其更强地等效并满足考试目的
·非线性函数:当不可能时,IRT 不假定学生-项目关系的线性函数。CTT在明显不可能的情况下假设线性函数(点双序列)。
一个幸福的大家庭请记住:IRT实际上是一系列模型,可以灵活使用参数。在某些情况下,仅使用两个(a,b)或一个参数(b),具体取决于评估类型和数据的拟合。如果存在多点项目,例如 Likert 评级量表或部分信用项目,则模型将扩展为包含其他参数。在此处了解有关部分信用情况的更多信息。
以下是家谱的快速细分,以及最常见的模型。
·单维
o二分法
§Rasch
§1PL
§2PL
§3PL
§4PL
oPolytomous
§Rasch partial credit
§Rasch rating scale
§Generalized partial credit
§Generalized rating scale
§Graded response
·多维
§Compensatory
§Non-compensatory
§Bifactor
在哪里可以了解更多信息?欲了解更多信息,我们推荐Embretson&Riese(2000)的教科书《心理学家的项目反应理论》(Item Response Theory for Psychologists),供那些对数学程度较低的处理方法感兴趣的人使用,或者推荐de Ayala(2009)进行更数学化的处理。如果您真的想深入研究,你可以试试由van der Linden编辑的3卷本的《Handbook of Item Response Theory》,其中有一章讨论了ASC的IRT分析软件Xcalibre。
想与我们的专家讨论如何应用IRT吗?保持联系!
