
想象一下,机器人不再只是按照预设程序执行任务,而是能够像人类一样理解语言、学习技能,甚至还能举一反三地应对新的挑战。
这并非科幻电影的场景,而是智元机器人正在努力实现的目标。
3月10日,智元机器人发布了首个通用具身基座大模型——智元启元大模型(GO-1),它究竟是如何让机器人拥有通用能力的呢?
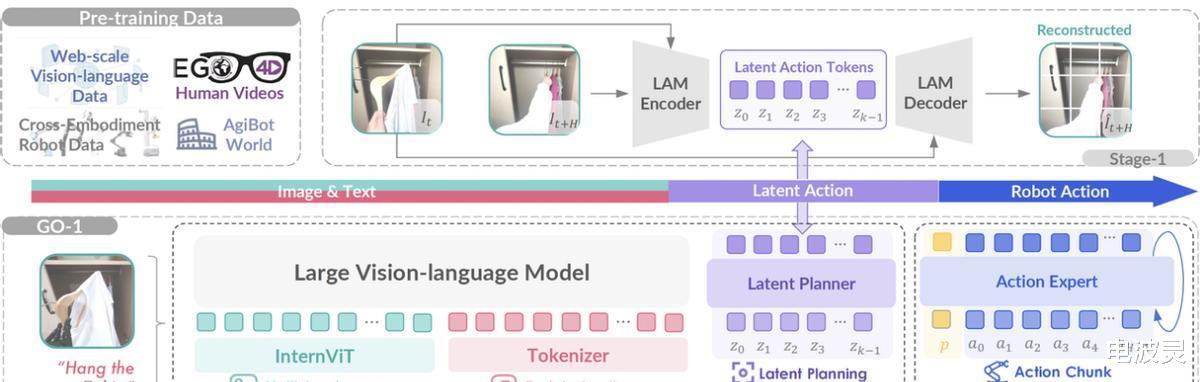
GO-1的核心在于其创新的ViLLA架构(Vision-Language-Latent-Action)。
不同于传统的VLA(Vision-Language-Action)架构,ViLLA架构巧妙地引入了“隐式动作标记”(Latent Action Tokens)。
这一关键改进弥合了视觉、语言输入与机器人实际动作执行之间的差距,使机器人能够更有效地利用各种数据进行学习。
ViLLA架构由VLM(多模态大模型)和MoE(混合专家模型)两部分组成。
VLM负责处理多模态信息输入,例如视觉信号、力觉信号和语言指令等,并将其转化为机器人可理解的表达。
MoE则包含两个关键模块:隐式规划器和动作专家。
隐式规划器利用大量的人类操作和跨本体操作视频数据,使机器人能够理解动作的含义和执行方式。
动作专家则利用高质量的仿真数据和真机数据,进一步提升机器人动作执行的精度和效率。
GO-1的强大能力离不开“数字金字塔”的支撑。
这个金字塔包含了多维度、多类型的数据,从互联网上的海量文本和图文数据,到人类操作视频、仿真数据,再到高质量的真机示教数据,这些数据共同构成了机器人学习的“养料”。
通过ViLLA架构,GO-1能够有效地利用这些数据,逐步建立起对世界的理解和对动作的掌控。
GO-1的独特之处在于其四大核心特点:人类视频学习、小样本快速泛化、一脑多形和持续进化。
通过学习人类视频,GO-1能够更好地理解人类行为,并为人类提供更贴切的服务。
小样本快速泛化能力则使GO-1能够在少量数据甚至零样本的情况下适应新的场景和任务,大大降低了使用门槛和后训练成本。
一脑多形的能力让GO-1可以快速迁移到不同的机器人本体上,实现群体智能。
而持续进化则保证了GO-1能够在实际使用中不断学习和进步,越用越聪明。
那么,GO-1如何在实际应用中发挥作用呢?
想象一下,你对机器人说“挂衣服”。
GO-1首先会通过VLM理解你的指令和当前场景,然后利用隐式规划器设想挂衣服的操作步骤,最后通过动作专家控制机器人完成任务。
在这个过程中,GO-1会综合运用从“数字金字塔”中学习到的各种知识,例如对“挂衣服”这一指令的理解、对衣物和衣柜的识别、对挂衣服动作的规划等等。
为了让机器人能够理解“挂衣服”的含义,GO-1的VLM部分继承了开源多模态大模型InternVL2.5-2B的权重,并利用互联网上的海量文本和图文数据进行训练。
这使得GO-1具备了通用的场景感知和理解能力。
隐动作专家模型则利用大规模人类操作和跨本体操作视频数据,让GO-1能够理解动作的含义和执行方式。
动作专家模型则利用高质量的仿真数据和真机数据,使GO-1能够精准地控制机器人的动作。
GO-1的发布标志着具身智能向通用化、开放化、智能化迈出了重要一步。
它将推动机器人从单一任务向多种任务、从封闭环境向开放世界、从预设程序向指令泛化的转变。
未来,机器人将不再是依赖特定任务的工具,而是具备通用智能的自主体,在商业、工业、家庭等领域发挥更大的作用。
智元机器人通过GO-1的发布,为我们描绘了一个充满希望的未来:机器人将成为人类的得力助手,帮助我们完成各种任务,提升生活质量。
通往通用人工智能的道路并非一帆风顺。
如何让机器人更好地理解人类意图,如何在复杂多变的环境中做出正确的决策,如何保障机器人与人类的安全和谐共处,这些都是亟待解决的挑战。
未来,机器人能否真正拥有像人类一样的智能?
这仍然是一个值得我们深入思考和探索的问题。
