在信息爆炸的时代,我们每天都会接触到海量的知识。从书本、网络文章到各类课程,知识的获取变得前所未有的容易。但你是否有过这样的困扰:学了很多知识,却感觉它们杂乱无章,在需要的时候无法快速调用?这时候,构建个人知识图谱就显得尤为重要。它就像一个私人知识管家,帮你将零散的知识整理得井井有条,让知识真正为你所用,助力你在学习和成长的道路上一路开挂 。接下来,就让我们一起揭开知识图谱的神秘面纱,探索如何构建属于自己的知识图谱吧。
一、走进知识图谱的奇妙世界
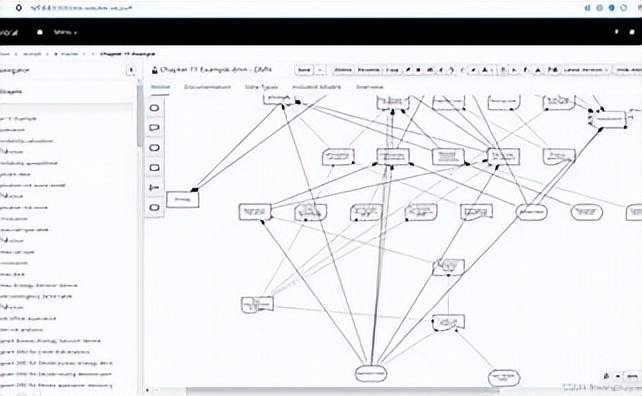
简单来说,知识图谱就是一种揭示实体之间关系的语义网络。我们可以把它想象成一张巨大的蜘蛛网 ,每个节点都是一个实体,比如人、事物、概念等,而节点之间的连线则代表着实体之间的各种关系。
举个例子,当我们提到 “苹果” 这个实体时,它不仅是一种水果,还可以与 “乔布斯”“苹果公司”“iPhone” 等实体建立联系。通过知识图谱,我们能清晰地看到:苹果公司由乔布斯创立,iPhone 是苹果公司的产品 。这样一来,原本孤立的信息就被串联起来,形成了一个有机的知识整体。
(二)知识图谱能为你做什么知识图谱在我们的学习、工作和生活中都能发挥巨大的作用。
在学习上,它能帮助我们搭建系统的知识框架。比如学习历史时,以时间为线索,将各个历史事件、人物、朝代等通过知识图谱关联起来,能让我们对历史发展有更清晰、全面的理解,轻松记住那些容易混淆的知识点。 比如在学习中国古代史时,通过知识图谱可以清晰地看到秦朝统一六国后,实行了一系列的改革措施,这些措施又对后续汉朝的政治、经济、文化发展产生了怎样的影响,各个朝代之间的兴衰更替和传承关系一目了然,不再是死记硬背一个个孤立的历史事件。
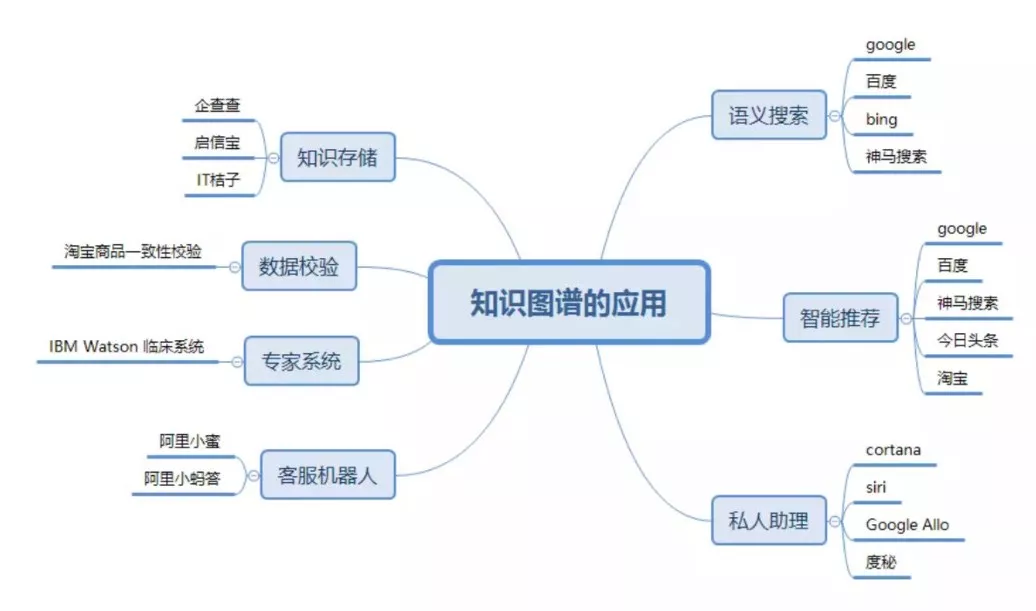
工作中,知识图谱能提升效率,辅助决策。以市场营销为例,通过分析消费者、产品、市场趋势等实体间的关系,企业可以精准定位目标客户,制定更有效的营销策略。在项目管理中,知识图谱可以帮助梳理项目任务、人员分工、时间节点等信息,让项目进展更加顺利。
生活里,知识图谱也无处不在。当你使用智能语音助手时,它背后的知识图谱会理解你的问题,并从海量信息中快速找到答案。比如你问 “附近有哪些好吃的川菜馆”,语音助手通过知识图谱关联到地理位置、餐饮类型等信息,为你推荐合适的餐厅。 再比如在旅游规划时,知识图谱可以根据你的兴趣爱好、预算、时间等因素,推荐旅游景点、酒店、交通方式等,为你打造个性化的旅行方案。
二、构建知识图谱的前期准备
构建知识图谱就像建造一座大厦,首先得明确建造的目的和风格。你是想构建一个用于学术研究的专业知识图谱,还是为了提升工作效率的职场知识图谱 ?是聚焦于历史文化领域,还是对科技前沿感兴趣?明确目标能让你在构建过程中有清晰的方向,避免盲目收集信息。
比如,如果你是一名学生,想要构建一个历史学科的知识图谱,你的目标可能是梳理历史事件的脉络,方便复习和理解历史知识。这样,你就可以专注于历史事件、人物、朝代等相关信息的收集和整理。如果你是一名职场人士,想要构建一个与项目管理相关的知识图谱,你的目标可能是提高项目执行效率,那么你就需要关注项目流程、人员分工、时间管理等方面的知识。
(二)收集资料与信息来源确定了目标和领域后,接下来就是收集资料。这就像收集建造大厦的原材料,材料越丰富、质量越高,建成的大厦就越坚固。收集资料的渠道有很多:
书籍:专业书籍是知识的宝库,它们经过了时间的检验和专家的筛选,内容系统且深入。在构建历史知识图谱时,可以参考《全球通史》《国史大纲》等经典著作,从这些书中获取历史事件、人物等核心信息。
网站:互联网上有海量的信息,但需要筛选。像维基百科、百度百科等综合性百科网站,能提供大量的基础信息。专业论坛也是获取信息的好地方,比如在构建科技领域知识图谱时,知乎上的相关话题讨论,能让你了解到行业内最新的动态和观点。
学术数据库:对于学术研究相关的知识图谱,学术数据库必不可少。中国知网、万方数据等平台上的学术论文,具有很高的权威性和专业性,能为你提供深入的研究成果和前沿的学术观点。
专家:如果你能接触到相关领域的专家,不妨向他们请教。专家们多年的研究和实践经验,能为你提供独到的见解和宝贵的建议,帮助你少走弯路。 例如,在构建医学知识图谱时,可以咨询医生或医学研究者,他们能分享临床经验和最新的医学研究成果。
在收集资料时,一定要注意信息的质量。优先选择权威、可靠的信息源,避免使用未经证实的谣言和低质量的内容,以免影响知识图谱的准确性和可靠性。 同时,要对收集到的信息进行分类整理,为后续的知识图谱构建做好准备。 比如,将历史知识按照时间顺序、朝代等进行分类,将项目管理知识按照项目阶段、知识模块等进行分类,这样在构建知识图谱时就能更加得心应手。
三、构建知识图谱的实用步骤
知识抽取是构建知识图谱的第一步,它就像是从矿石中提炼黄金,从大量的文本、数据中提取出实体、属性和关系。
实体抽取可以借助自然语言处理工具,比如 Python 中的 NLTK 库。当我们处理一段关于科技的文本 “苹果公司发布了新款 iPhone 14,其搭载了 A16 芯片”,使用 NLTK 库进行命名实体识别,就能轻松提取出 “苹果公司”“iPhone 14”“A16 芯片” 这些实体。
属性抽取则是确定实体的特征信息。继续以上面的例子,“发布时间” 就是 “iPhone 14” 的一个属性,通过对文本的分析和相关技术,可以提取出 “新款 iPhone 14” 的发布时间等属性信息。
关系抽取是找出实体之间的联系。还是这个例子,“发布” 就是 “苹果公司” 和 “iPhone 14” 之间的关系,通过句法分析、依存关系分析等技术,可以识别出这种关系 ,将它们以 “苹果公司 - 发布 - iPhone 14” 的三元组形式表示出来,为知识图谱构建基本的结构。
(二)知识融合:消除冲突与冗余不同来源的数据可能存在冲突和冗余,这就需要知识融合来解决。知识融合就像把不同版本的拼图碎片整合到一起,消除矛盾,形成完整、准确的知识体系。
比如,在收集关于历史人物的信息时,不同的书籍和网站可能对其出生时间、生平事迹的描述存在差异。这时候就需要进行数据清洗和比对,依据权威资料,确定正确的信息。再如,有些数据可能是重复的,像不同渠道都报道了同一场科技发布会的基本信息,就需要去除冗余,只保留最有价值、最准确的内容 。通过实体对齐、数据合并等操作,确保知识图谱中的每一个信息都是准确且唯一的,避免出现混乱和错误。
(三)知识存储:选择合适容器知识抽取和融合后,就要考虑如何存储这些知识。这就好比选择一个合适的仓库来存放货物,关系型数据库和图形数据库是常见的选择 。
关系型数据库,如 MySQL,以表格的形式存储数据,适合存储结构化、关系相对简单的数据。如果知识图谱中的实体和关系比较规则,数据之间的关联可以通过表格的主键和外键来建立,使用关系型数据库就可以很好地管理。 比如存储学生信息和课程信息,学生和课程之间的选课关系可以通过在不同表格中设置外键来关联。
而图形数据库,如 Neo4j,则以图的形式存储数据,节点表示实体,边表示关系,非常适合处理复杂的关系网络。在构建社交网络知识图谱时,人与人之间的复杂关系,如朋友、同事、亲属等,使用图形数据库可以直观地表示和查询,能够快速找到某个人的所有社交关系 。所以,在选择知识存储方式时,要根据知识图谱的特点和应用需求来决定,以确保知识的高效存储和快速访问。
(四)知识推理:发现隐藏知识知识推理是知识图谱的高级应用,它能帮助我们从已有的知识中挖掘出隐藏的信息 。就像从已知的线索中解开谜题,发现更深层次的知识。
例如,在一个电影知识图谱中,已知 “《泰坦尼克号》的导演是詹姆斯・卡梅隆”“詹姆斯・卡梅隆还导演了《阿凡达》”,通过知识推理,我们可以得出 “《阿凡达》和《泰坦尼克号》的导演是同一人” 这样的新知识 。常用的推理技术包括基于规则的推理,如定义 “如果 A 是 B 的父亲,B 是 C 的父亲,那么 A 是 C 的祖父” 这样的规则来推导新的关系;还有基于机器学习的推理,通过训练模型,让机器自动学习知识之间的关联和模式,从而进行推理 。像一些智能问答系统,就是利用知识推理来理解用户的问题,并从知识图谱中找到答案,为用户提供更智能、更准确的服务。
四、构建过程中的实用工具推荐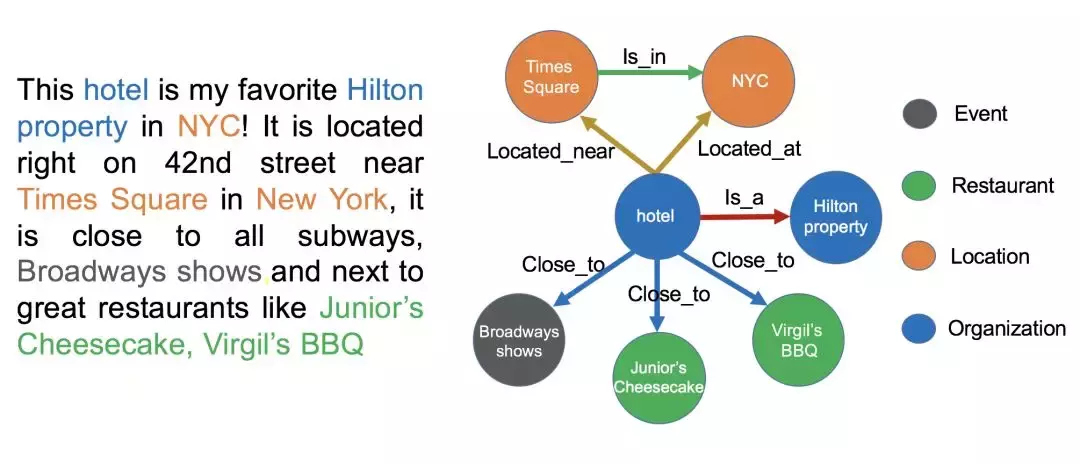
Neo4j:作为一款开源的图数据库,它以独特的图形数据模型来表示和存储数据 。在 Neo4j 中,节点代表实体,关系连接两个节点,表示它们之间的关联,属性则是节点和关系的附加信息。这种数据模型非常直观,能自然地表达复杂的关系数据,简化了数据建模和查询过程。在社交网络分析中,人与人之间复杂的社交关系,如朋友、关注、共同兴趣等,使用 Neo4j 可以轻松地存储和查询,快速找到某个人的所有社交关联。它适用于处理高度连接的数据,以及对关系查询性能要求较高的应用场景。
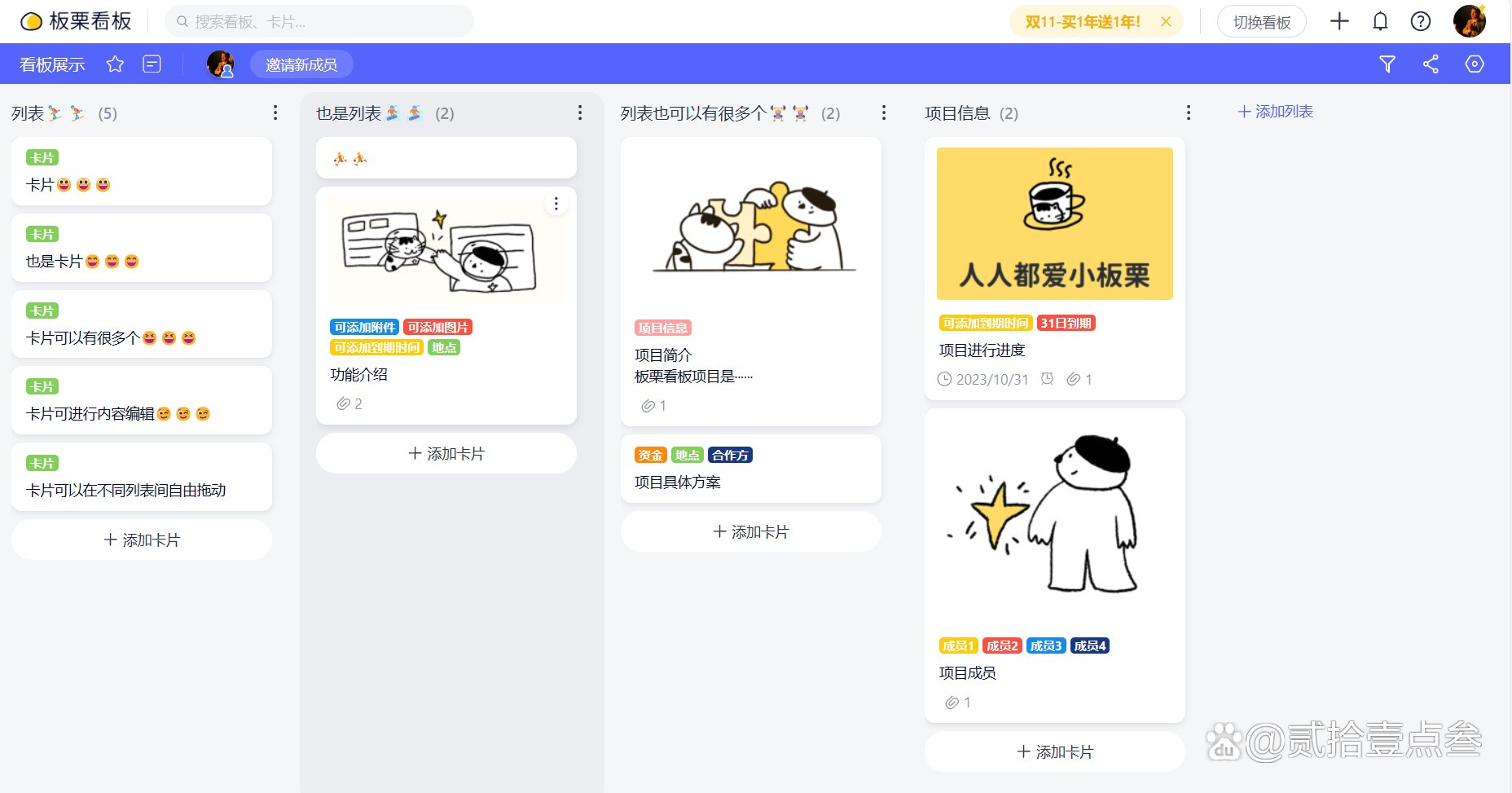
板栗看板:是一款专注于知识管理和团队协作的工具,它采用看板的形式,让知识的组织和展示更加直观 。你可以创建不同的看板来分类管理知识,每个看板下又可以设置多个列表和卡片,将知识点、文档、任务等以卡片的形式进行整理。在团队项目中,成员可以将项目相关的知识、资料、进度等信息整理到板栗看板上,方便团队成员随时查看和协作。它适合个人知识管理以及小型团队内部的知识共享与协作场景,能够提高知识的可视性和团队沟通效率。
Jena:是一个用于构建语义网应用的 Java 框架,包含了丰富的工具和库,其中推理子系统允许将一系列推理引擎或推理器插入 。它支持基于规则的推理,用户可以自定义推理规则,从已有的数据信息和类描述中推理出额外的事实。比如在一个电影知识图谱中,定义规则 “如果电影 A 和电影 B 有相同的导演,且电影 A 的评分很高,那么电影 B 可能也值得一看”,Jena 就可以依据这个规则,从知识图谱中已有的电影数据和导演关系中,推理出哪些电影可能值得推荐。它适用于基于语义网技术构建的知识图谱应用,能够实现较为复杂的知识推理功能。
Drools:是一个基于 Java 的开源业务规则引擎,它提供了一种声明式的规则语言,方便用户定义和管理业务规则 。在知识图谱中,Drools 可以将知识转化为规则,通过规则引擎执行这些规则,实现知识推理。在金融风控领域,利用 Drools 可以制定一系列风险评估规则,如 “如果用户的信用记录不良,且近期有大额资金流动,那么该用户存在较高的风险”,然后根据知识图谱中存储的用户信息和交易记录进行推理,判断用户的风险等级。它擅长处理复杂的业务规则和决策逻辑,在需要进行智能决策的知识图谱应用场景中具有很大的优势。