影视特效五花八门,在各类影片尽显神通,让画面更沉浸、真实、绚丽。在如 今AI当潮的时代,通过深度学习、机器学习等方式,像人类一样来“思考”,帮 助人们在包括影视制作等行业中提速增效。ChatGPT、Midjourney以及Sta- ble Diffusion等模型和应用的出现,也让以人工智能生成内容(AI-Generated Content, AIGC)等加速为影视制作领域带来革新。
影视制作中的AI新尝试
AIGC目前已经在影视制作领域进行了多种尝试, 像智能剪辑、AI生成视频、 AI作画等都已不是问题。除了特效制作, 其实在影视制作流程中, 还有一个关键且繁杂的步骤就是剧本拆解,把剧本中各项要素分析出来,再制作成拍摄计 划和预算表。其目的是为了明确角色定位,确保剧情连贯以及用于后期制作 等。拆解的过程中有大量的数据录入工作,因剧本的长短,需要大量的人工和 时间来完成剧本的拆解。基于AI的人工智能剧本来拆解剧本,能很大程度上降 低人力和时间成本,利用大语言模型的技术,可以将剧本内容自动拆解出场 次,并分析出角色、对白、动作,整个过程需要几秒到几分钟。
影视制作本身具有很大的移动性和灵活性, 编剧和导演对剧本的处理上有非常 强的隐私需求, 私有化方案部署是一个强需求,加上剧组在拍摄过程中不停的 转场, 这要求私有化部署, 既要有足够的算力制程, 又可以灵活部署, 跟着剧 组一起移动。基于大语言模型的剧本拆解方案已经成为主流的解决方案, 部署 大语言模型需要很强的异构算力, 足够大的内存容量, 英特尔® 至强 ® W平台刚好可以满足该场景的需求, 既能提供足够的算力, 又能扩展多个GPU,还能 灵活部署, 跟着剧组随时移动。在扩展方面, 英特尔® 至强 ® W处理器有高达 112通道的扩展,加上多大2T的内存支持,还有高达60个可超频核心, 使得该平台能扩展出非常强大的异构算力。

AI助力,算力筑基
基于LLM模型等构建的AIGC应用在算力需求、数据规模上带来更大挑战, 尤 其是LLM模型拥有的巨大参数规模需要更强的设备算力,更大的内存带宽等,开发者、创作者在设备或平台的选择上更具难度。
以往,这些体量庞大的网络模型让AI应用背后的模型总是离不开云服务和数据中心这样的部署环境,用户需通过联网接入才能开启开发与创作之旅。在AIGC应用更多下沉和落地于各行业、各领域的今天,其发展也需要更多开发者和创作者共同参与其中。这就需要AIGC的载体,以及对应的开发/创作方案更为轻便、灵活和高效。英特尔不仅在AI领域有着全面的软硬件产品体系和技术栈,也在AI应用的行业落地和方案优化部署上有着丰富的经验和实战案例 。
软件能力也是AI PC体验的关键, 而英特尔在这方面有着独特的优势地位。英特尔通过多个层面的软件能力助力AIGC产业的发展。
首先是通过软件来充分激发英特尔® 架构硬件蕴含的算力,让底层硬件性能更好地支撑上层的AIGC应用,例如OpenVINO™ 工具套件全面支持英特尔异构的硬件平台,开发者可以灵活选用各种英特尔 ® CPU、GPU和NPU等计算引擎, 满足包括客户端 、边缘计算的不同业务场景需求;同时提供包括面向低比特混合精度的量化在内的多种软硬件优化策略等。
其次是通过广泛地合作,对各类AI框架、平台和加速库提供面向英特尔® 架构的支撑和优化。例如OpenVINO ™ 工具套件广泛支持PyTorch, TensorFlow , PaddlePaddle等主流AI框架,并与HuggingFace合作,借助Optimum Intel帮助开发者将更多HuggingFace的大语言模型进行压缩优化,并在英特尔的平台上进行部署 。
又如BigDL-LLM加速库利用了低比特优化和硬件优化技术,可以极低的时延运行和微调大语言模型,并支持各类标准PyTorch API( 如 HuggingFace Transformers 和 LangChain) 和大模型工具,( 如 HuggingFace PEFT、 DeepSpeed、 vLLM 等)。这种软硬件协同的驱动力对AIGC应用开发和创作带来的助益是显而易见的。以Stable Diffusion的使用为例, 借助英特尔为其 开发的AI框架, 开发者可在开启OpenVINO ™ 工具套件的情况下, 仅通过一行代码的安装,就可以加速PyTorch模型运行,并让Automatic1111 for Stable Diffusion Web UI在英特尔锐炫 ™ 显卡上流畅运行, 从而快速生成高质量图片。
同时, 英特尔也与众多合作伙伴一起,通过开源社区、技术创新大会等形式, 积极促进AIGC生态的发展 、联动与创新,并催化更多AIGC的应用方案和落地实例 。 英特尔还在“AI PC加速计划”中与超过200家ISV合作伙伴开展深度合作,并集合400余项AI加速功能,在2025年前为超过1亿台PC带来AI特性 。这些合作和AI加速功能显然将进一步提升AIGC在各领域的产业落地 。
AI推理和部署事半功倍的神器——OpenVINO™ 工具套件
在众多加速AI落地的软件工具中, OpenVINO ™ 工具套件尤为突出,能够加速 AI推理及部署,且在异构平台上基于不同维度的AI方法,包括深度学习、基于注意力的网络以及LLM等,帮助AI领域的开发者在计算机视觉、自动语音识 别、自然语言处理以及推荐系统等场景中,加速相关应用程序和解决方案的开 发 。OpenVINO m 工具套件是一个开源工具包,通过降低延迟和提高吞吐量来 加速AI推理, 同时保持准确性 、减少模型占用空间并优化硬件使用。 它简化了 AI开发和深度学习在计算机视觉、大型语言模型(LLM)和生成式AI等领域的集 成。 OpenVINO m 工 具套件 对大量流行AI 框架 (如PyTorch、Tensor Flow 、 PaddlePaddle等)都提供了支持, 同时也能借助硬件平台(如英特尔® 至强 ® 处 理 器 ) 的 特 性 和 内 置 加 速 器 增 加 AI 应 用 的 功 能 和 性 能 。 随 着 最 新 版 本 OpenVINO m 工具套件2025 .0 (2025年2月发布)的推出,为更多GenAI覆盖和 框架集成,更广泛的大型语言模型(LLM)支持和更多模型压缩技术,更多的便 携性和性能以在边缘 、云端或本地运行AI提供了广泛的支持 。
01
面向更多GenAI覆盖和框架集成,以最小化代码更改
● 支持的新模型:Qwen 2 .5 、FLUX.1 Schnell和FLUX.1 Dev 。
● Whisper模型: 在CPU、内置GPU和独立GPU上通过GenAI API提高性 能。
● 引入对torch.compile的NPU支持, 使开发人员能够使用OpenVINO后端 在 NPU 上 运 行PyTorch API 。 启 用了来自Torch Vision 、 Timm和TorchBench仓库的300多个深度学习模型。
02
面向更广泛的大型语言模型(LLM)支持和更多模型压缩技术:
● GenAI API增加了Prompt Lookup功能,通过有效利用与预期用例匹配 的预定义提示, 改善了LLM的第二个令牌延迟 。
● GenAI API现在提供图像到图像的修复功能。 此功能使模型能够通过修复 指定的修改并将其与原始图像无缝集成来生成逼真的内容。
● 非对称KV缓存压缩现在在CPU上启用了INT8,降低了内存消耗并改善了第二个令牌延迟,特别是在处理需要大量内存的长提示时。用户应明确指定此选项。
03
面向更多的便携性和性能,以在边缘、云端或本地运行 AI:
● 支持最新的英特尔® 酷睿 ™ Ultra 200H 系列处理器(原代号为Arrow Lake-H)
● OpenVINO ™ 后端与Triton推理服务器的集成使开发人员能够在部署到英特尔CPU时利用Triton服务器来增强模型服务性能。
● 新的OpenVINO ™ 后端集成允许开发人员直接在Keras 3工作流中利用 OpenVINO性能优化,以在CPU、内置GPU 、 独立GPU和NPU上实现更快的AI推理 。此功能在最新的Keras 3.8版本中可用。
● OpenVINO模型服务器现在支持原生Windows服务器部署, 使开发人员能够通过消除容器开销和简化GPU部署来利用更好的性能。
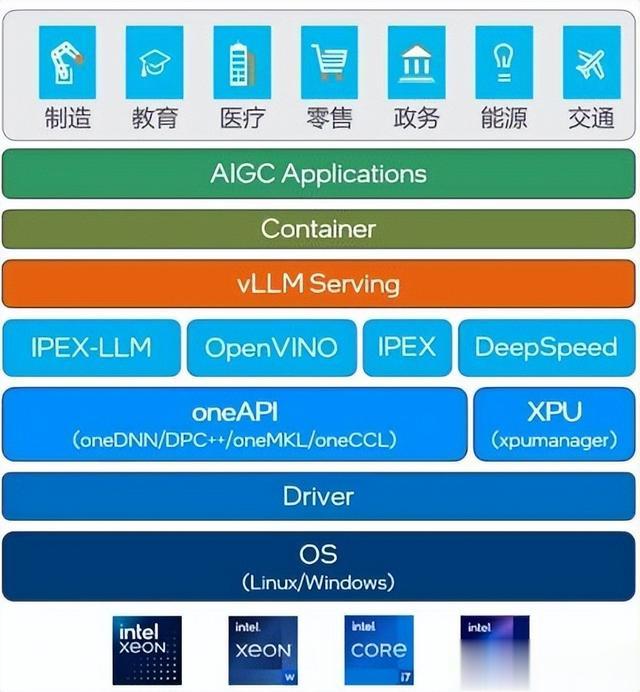
AI出色落地,首推英特尔i+i平台
金蛇献瑞之际,AI大模型的开源策略点燃了整个行业应用大爆发, 随即迎来了 推理元年,大语言模型的部署占据了成本的大头, 主要是用了很多GPU来协同推理,如何降低部署成本, 英特尔给出了完整的解决方案,基于至强平台搭配 英特尔消费级显卡锐炫A770或者马上发布的BMG大显存产品,大幅降低部署 成本。 比如2张或4张锐炫A770(16GB显存)可推理Qwen-32B模型, 推理框架 是基于英特尔所支持的vllm serving来部署, 拉取一个镜像, 挂着Hugging Face的开源模型即可提供OpenAI API兼容的大语言模型服务 。
目前业界火热的蒸馏模型,包括1 .5B 、 7B 、 14B 、 32B ,以及70B的开源模 型, 英特尔都已经完成适配, 2卡可以部署14B模型, 4卡可以部署32B的模 型, 8卡可以部署70B模型。不同GPU密度可搭配不同的平台,包括至强W的 单路平台和双路的至强SP平台,可满足云边数据中心,以及腰部以下客户的真 实部署需求 。
©英特尔公司, 英特尔 、英特尔logo及其它英特尔标识,是英特尔公司或其分支机构的商标 。文中涉 及的其它名称及品牌属于各自所有者资产 。
