HighService(High-Performance Pythonic AI Service) 是在支持阿里妈妈业务过程中,不断提炼抽象出的高性能Python AI服务框架,支持视频、图文、LLM等多种模型,能够显著加快模型的推理速度,提高集群的资源利用效率。随着SD (StableDiffusion),LLM (Large Language Model) 等大模型在阿里妈妈各个业务场景落地越来越广(覆盖了创意素材生产、广告投放、内容风控、商家运营、自动调价等全流程),算力的需求呈现出指数级增长,但GPU的供给却远远跟不上需求增长。另一方面,HighService支持业务种类繁多,不同场景对于系统的要求各不相同。在线场景(用户实时等待结果返回)对请求时延比较敏感,而离线场景(批处理任务,非用户触发)更加关注单位时间内处理的任务量。因此如何充分利用已有资源,在保证在线用户体验的前提下,尽可能多地提高离线业务的产量,成为我们最重要的工作。同时,在大模型日新月异的时代,也要求HighSerivce能够快速支持模型的试用和业务上新,提高研发和迭代效率。
综合以上业务背景,HighService框架的能力建设主要围绕以下三个方面进行:
提高大模型推理速度,提升硬件资源利用率;
全局资源调度,充分利用空闲算力提高离线产量;支持新业务快速上线及迭代。二、HighService产品介绍2.1 设计理念HighService的设计理念,并不是简单的追求推理加速,而是在支持大模型业务的过程中,面对各种复杂的问题,将解决方法不断沉淀总结,从而形成的一套完整的解决方案。我们把HighServcie拆分成三个维度:
首先,HighService是一个多功能的服务框架。大模型在线预估服务,其基本功能还是将模型加载起来,供客户端调用。HighService选择了通用的HTTP协议,只需几行代码便能轻松上线一个模型。同时对于常用的功能,如监控请求时延、QPM、失败率、报警等必要功能,默认开启,大大降低了服务部署的成本,减少了重复劳动。
其次,HighService是一个大模型推理加速库。1) 对于常见的LLM模型,HighService集成并优化SOTA的开源推理框架,如TensorRT-LLM、vLLM等,用户无需了解太多的框架细节,即可按照用户文档部署起来一个LLM服务。对于常见的加速方法,如并行、低精度量化、前缀缓存、MoE等能力,也是开箱即用。2) 对于图文类模型,提供了CPU/GPU分离的多进程架构,降低了Python GIL锁的影响,提高了GPU利用率。
最后,HighService是一个全局资源调度器。资源利用率提升,从来不是优化某一个服务能解决的,而是从集群的视角,随着各服务流量波动,动态调整资源。HighService通过在集群之间动态扩缩容,能够做到对于突发流量及时扩容,降低失败率和超时率,对于低流量集群随时缩容,避免资源浪费。另一方面,将同一模型的在线/离线集群合并在一起,保障在线流量不超时的前提下,尽可能高地提高离线产量。通过多种手段,解决资源不足的问题。
2.2 主要功能为了实现上面三个层次的功能,HighService的功能架构设计如下图所示:

HighService功能架构
三、HighService详细功能介绍3.1 系统架构HighService系统架构如下图所示:

HighService系统架构
从上图可以看到,HighService采用CPU/GPU分离的架构,CPU进程负责接收用户请求,并完成业务逻辑处理,然后将模型Inputs发送给GPU进程进行推理,从而避免Python GIL锁造成的GPU利用率低的问题(详细分析参见 广告深度学习计算:多媒体AI推理服务加速利器high_service)。从目前支持的阿里妈妈业务场景来看,GPU进程有三种类型:
场景1:传统小模型(如ResNet等)。 小模型的特点是相比于单次推理的时延(通常ms级别),CPU与GPU进程传输Inputs和Outputs的耗时无法忽略。实验发现,直接通过进程间消息队列传输Tensors效率低,导致GPU因等待Inputs而空闲。HighService 使用 共享内存 + 进程间消息队列 的模式,大大提高了数据传输效率。使用方法上,所有继承了hs.CudaProcessBase类的模型,都会自动创建一个GPU进程来加载模型,CPU侧通过hs.CPUClient.get方法与GPU进程通信,写法如下:
import high_service as hsclass CudaDetInfer(hs.CudaProcessBase):def load_model(self, model_paths):return DetInferModel(model_paths)# 调用方法,调用DetInferModel的forward方法out = hs.CPUClient.get('CudaDetInfer').run('forward', [torch.ones([2, 3])])
场景2:LLM服务。LLM服务的使用方式比较标准,HighService内置了常见的Loader来加载,如TBStars系列,Qwen系列等。
import high_service as hsmodel = hs.llm.start_llm_engine(model_paths)out = model.forward(inputs)
场景3:用户自定义场景。用户代码(make_app.py)中创建子进程,通用性较强,但是相比场景1和场景2,无法用到HighService提供的加速能力。
3.2 全局资源调度能力3.2.1 资源调度场景介绍1)在离线集群资源调度阿里妈妈的业务规模,决定了其海量的算力需求。以智能图文创意为例,每天需要生产大量图文创意,资源缺口很大;但另一方面,在线业务的潮汐属性,又造成了其夜间大量的GPU算力空闲。因此急需将GPU在各个集群之间动态调配,以提高离线任务产量。基本流程如下图所示。

不同集群之间动态调整机器数
如上图所示,当服务1的流量上涨时,HighService调度节点能够感知到服务1的流量大,因此从相对空闲的服务2转移GPU资源至服务1,从而做到资源自动在各个集群之间转移。
2)在离线流量动态调度对于部分模型服务,既有在线流量(即用户实时请求),又有离线流量(批处理任务),通常情况下为了避免离线流量过大影响在线流量的时延,会隔离资源部署两个集群。这就会造成在线集群低峰时段资源浪费,离线集群产量不足。通过上一小节的在离线集群资源调度,可以解决这个问题。但是如果能在一个集群中,动态的将机器分为两个Group,分别承接在离线流量,能够更加快速的应对突发流量(节省了容器的创建和销毁开销)。
针对这个需求,HighService提供了在离线流量混布能力。即在线流量和离线流量分发到同一集群的不同机器上,根据在线流量的大小,动态调整在离线机器的数量,保证在线流量不超时的前提下,将尽可能多的机器分配到离线集群,从而为离线流量提供尽可能多的算力。

在线流量低时,在线分组机器少

在线流量增多时,动态调整机器分组
3.2.2 调控指标上一节介绍了两种类型的动态调控,这里有一个很重要的内容,就是调控指标,该指标要能够准确反映出当前系统的忙闲程度,还要具备通用性,避免不同业务手工设置不同的值。
常用的调控指标包括CPU/GPU利用率、请求时延、QPS等等。经过试验发现都不具备通用性,即需要为不同的服务设置不同的阈值,使用较复杂。最终,我们设计了忙碌率(Busy)这一通用指标,其反映出了当前系统是否还有空闲CPU进程来接收请求,其计算方法如下图:

Busy统计方法
对于N个CPU进程,选取10秒的时间窗口,统计该时间窗口内,各个CPU进程的平均工作时间比例。由于CPU进程需要将模型处理任务发送给GPU进程,因此当GPU进程忙碌时,各个CPU进程的等待时间变长,从而使得Busy值变高;当GPU不忙碌时,Busy值变低。通过该值,能快速判断出系统状态,进而决策机器如何调整。
3.3 多功能服务框架HighService提供了部署服务需要的一系列基础能力,提供标准方案来解决共性问题,避免重复性的劳动,让工程、算法、设计师等岗位同学能够更加专注于本领域的技术问题。
3.3.1 HTTP/SSE流式服务HTTP/SSE流式服务,是最基本的功能。使用HighService启动一个单机的HTTP服务非常简单,仅需几行命令就可以完成。
3.3.2 分布式架构HighService作为单个HTTP服务,可以满足大部分场景需求。但是实际业务的复杂性,会带来一些特殊问题,比如:
问题一:Vipserver请求分发不均匀,造成的部分请求超时,如下图所示:

请求不均造成超时
对于视频生成等时延较长的应用,一旦出现请求分配不均的情况,就会造成请求超时。在使用Vipserver的过程中,这种情况经常出现,时延毛刺现象严重,限制了集群的总QPM (Query Per Minute)
问题二:多台机器加载不同的模型,需要根据请求申请不同的Vipserver给调用方,使用复杂,对于调用方开发和维护成本很高。

多模型造成多域名困扰
为了解决上面两个问题,我们设计了分布式架构,结构图如下:
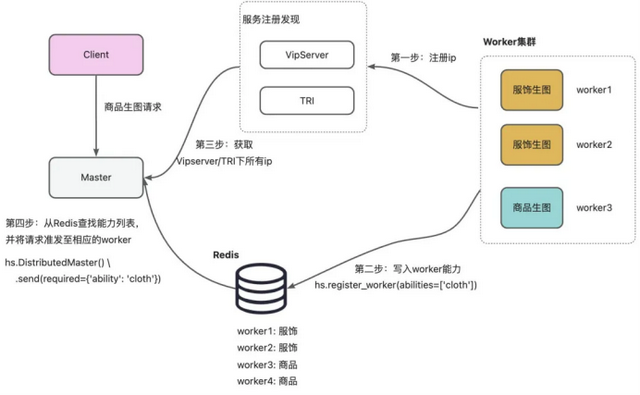
HighService分布式架构图
系统拆分为两个角色:
Master:流量接入层,获取Worker的状态,并将请求转发至空闲的Worker;
Worker:执行模型推理任务。
完整的服务流程包括以下四个步骤:
第一步:Worker挂载Vipserver或TRI,使得其ip:port能够被Master发现;
第二步:Worker通过hs.register_worker(abilities=['cloth']),注册自己的模型能力;
第三步:请求到来时,Master实时查找所有Worker的空闲状态;
第四步:根据ip:port实时获取满足要求,且当前最空闲的Worker,转发请求至Worker处理。
3.3.3 监控报警除了CPU、Mem、GPU、Disk、core、QPM、失败率等常规监控外,机器是否可服务,也是重要的监控内容。在《全局资源调度能力》一节,我们介绍了忙碌率(Busy)指标,这一指标同样可以用于监控系统是否“卡死”。当系统忙绿率Busy为1时,说明所有的CPU进程都被占用,无法再接收新的请求,即当前机器不可服务,需要预警。HighService默认服务卡死等监控,不需要用户额外开发,避免重复劳动。从监控看卡死如下图所示:

机器“卡死”监控
3.4 应用及推理加速本小节我们按照模型的种类,分别介绍HighService支持的业务场景,以及在每个场景的优化工作。
3.4.1 StableDiffusion应用及推理加速1)业务场景介绍StableDiffusion类模型在阿里妈妈落地场景主要包括三类:
创意图文业务,包括面向商家的万相营造、一键制图等工具。
创意视频业务,包括阿瞳木系列视频生成场景。智能出价业务,除了AIGC场景外,阿里妈妈异构计算团队与决策智能平台、AIS策略平台合作,将Diffusion模型应用于AIGB (AI Generated Bidding) 场景。✅ 延展阅读:智能创意技术专题 | AIGB系列详解
2)主要优化工作StableDiffusion类模型优化工作,从性能优化加速的角度来说,主要工作包括以下几个方面:
Pipeline并行:在部分生图场景中,会使用Classifier-Free Guidance (CFG)算法来得到效果更好的结果。使用CFG算法时,需要使用positive和negative两个prompt推理,使用同机房两台单卡GPU资源做CFG并行算法加速,整体可加速约1.8倍。

算子加速:主要使用了FlashAttention算法加速推理过程。FlashAttention可以几乎无损的加速Attention的计算过程,已经逐渐成为各大深度学习框架和LLM加速库的标配。
Batching推理优化:AIGB场景单次推理的计算量,相较于AIGC场景较小,单次推理无法用满GPU的算力资源,因此Batching对于提升GPU利用率尤其重要。HighService在内部消息队列中,对请求进行Batching处理,然后一次性送至GPU推理,经验证在一定延迟的约束下,可以提升1到10倍的单机极限吞吐。
HighService Batching能力
3.4.2 LLM应用及推理加速1) 业务场景介绍AI小万
“AI小万” 是阿里妈妈基于先进AI能力给广告商家打造的AI数字员工,作为个性化的推广管家帮助商家在淘宝平台更好地进行营销推广。它通过对话方式对客户的精准意图进行识别,辅助多轮会话及总结能力,在投放的各个环节给广告主带来个性化建议,比如依托全局营销知识库的知识问答功能,基于自然语言表达的数据快查功能,面向推广提效的诊断调优、AI巡检、早晚报、图表速成功能,面向投放过程辅助的AI选词及悉语文案功能等,目前小万支持的功能如下图所示。(延展阅读:揭秘阿里妈妈『AI小万』背后的AI Native工程能力)

内容风控
阿里妈妈内容风控团队作为广告业务的“守门员”,承担着管控百亿级广告内容安全生产、投放的重担,维护着电商生态的和谐、稳定发展。在海量内容中识别风险,犹如大海捞针,我们需要建设各个模态(图、文、音、视等),各个风险形式(色情、政治、禁限售等)上的防控能力。且风险不断变异,有非常强的对抗性,导致风险外漏是个必然事件,外漏 Case 怎样在百亿级全量数据中快速定位清理也是我们的必修课。在这个没有硝烟的战场上,我们需要以“数据+AI”驱动、通过强有力的算力武装,才能抵御住风险入侵。
2)主要优化工作LLM (Large Language Model) 在阿里妈妈的落地场景也相当广泛,包括上面介绍的AI小万、创意智能文案、内容风控等多个场景,对于性能优化的需求非常强烈。HighService对于LLM类模型的支持也越来越完善:
从支持模型的角度,目前支持的模型包括:Qwen系列模型,TBStars系列模型,其他主流开源模型。
从推理框架角度,支持了vLLM、TensorRT-LLM等,一键直达SOTA加速效果。从服务的角度,支持流式、非流式两种,适应不同的场景。从推理优化的角度,支持了当前大部分通用方案,例如:TP/PP加速,投机采样,前缀缓存,量化,Continuous Batching。3.3.3 常规小模型推理加速为了解决Python GIL锁带来的GPU利用率低的问题,详细介绍参见之前的公众号文章《广告深度学习计算:多媒体AI推理服务加速利器HighService》。
四、总结
经过多年的发展,HighService支持业务范围从传统小模型,逐步丰富为包括StableDiffusion、LLM在内的大模型;系统功能也从仅支持单机单卡推理加速,逐步扩展为支持单机多卡、集群动态调度、分布式推理等众多能力。随着近期DeepSeek爆火,更大模型(671b及以上)的推理加速,也是接下来HighService团队的工作重点,期待能够与更多优秀的伙伴合作,不断发展和完善HighService!
