数学能力的评估对于理解和发展大语言模型(LLMs)至关重要。数学问题不仅涉及对数字的理解和操作,还包括了抽象概念化、逻辑推理等核心能力的考察。因此,一个高质量的数学评估基准对于全面评估LLMs的能力具有重大意义。
传统的数学问题数据集,如AddSub和MultiArith(下图),提供了基础的数学词汇问题库,但这些通常只能评估模型在特定数学问题上的准确性。随着中文LLMs的迅速发展,相应的中文数学评估数据集也应运而生。然而,简单的准确率评估并不能充分揭示模型掌握了哪些数学概念或技能。因此,迫切需要一个更全面的测试集,能够细致地评估LLMs在不同难度级别的数学问题上的推理能力。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
▲FineMath能够从三个方面评估LLMs的数学能力:理解抽象数学概念的准确性、推理的准确性以及整体的准确性。

为了解决这一问题,我们提出了FineMath,这是一个针对中文LLMs的细粒度数学评估基准数据集(参见上图)。该数据集包含小学数学的核心概念,分为17类数学词汇问题,用以深入分析LLMs的数学推理能力。所有数学词汇问题均经手工标注,按解决难度(推理步骤数)分级。通过在FineMath上对多个LLMs进行实验,我们发现中文LLMs在数学推理上还有进步空间。我们还深入分析了评估过程和方法,发现它们对模型结果和理解其数学推理能力有重大影响。FineMath数据集即将公开。
论文标题: FineMath: A Fine-Grained Mathematical Evaluation Benchmark for Chinese Large Language Models
FineMath基准的构建与目标:细粒度评估中文LLMs的数学推理能力1. 数据集概述与关键数学概念的覆盖
FineMath基准旨在全面评估中文LLMs的数学推理能力。该基准涵盖了小学数学中的主要关键数学概念,并进一步细分为17类数学应用题(Math Word Problems, MWPs),使得能够深入分析LLMs的数学推理能力。这些关键概念和技能包括数字与运算、代数、几何、测量、数据分析与概率、问题解决和推理等。
2. 17个数学问题类别的详细介绍
FineMath包含17种类型的MWPs(见下表),这些类型基于中国教育部制定的数学课程标准以及美国国家数学教师委员会(NCTM)设定的原则和标准。这些类别包括百分比、小数、分数、因数与倍数、计数、比例和混合运算等。每种类型的MWPs都包含三个难度级别,以促进详细的推理能力分析。
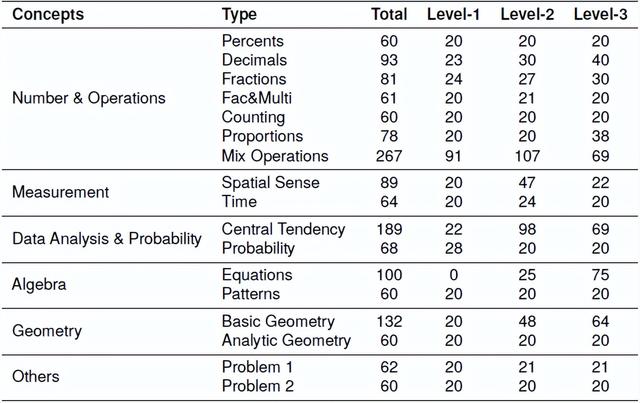
3. 难度分级与推理步骤的标注
FineMath中的每个数学问题都根据解决问题所需的推理步骤数量手动注释难度级别。问题被分为三个难度级别:一步推理的问题为一级难度,两步推理的问题为二级难度,三步或更多步推理的问题为三级难度。这种分类不仅反映了问题的难度,还代表了推理过程。
数据收集与注释过程1. MWP分类与问题标准化
在数据收集过程中,我们将收集到的问题分类为17种类型,每种类型对应一个关键或基本概念。我们将多个查询的问题标准化,确保每个问题只包含一个查询,并重新表述模糊查询,以便模型能够生成唯一的答案。
2. 数学推理与答案标准化
我们手动进行MWPs的回答过程,并由人工双重检查真实答案。我们要求注释者提供回答每个MWP的步骤,每个步骤应该是原子的、不可分割的。对于使用固定解决公式的计算,例如计算圆的面积,我们将其视为单步MWPs。
3. 多项选择题的转换
为了便于自动评估,我们还将原始的MWPs转换为多项选择题形式,手动提供额外的对比答案选项,类似于AQUA数据集。
FineMath数据统计与分析1. 数据集的整体统计信息
FineMath数据集旨在评估中文LLMs的数学推理能力,涵盖了小学数学中的主要概念,并进一步细分为17类数学应用题。这些类别的题目都经过手动注释,根据解决问题所需的推理步骤数量来标注难度等级。数据集包含1584个问题,每个数学概念至少包含60个问题,每个难度等级至少包含20个问题。FineMath的数据统计显示,所有问题被分为五个主要数学概念和两种经典类型的数学应用题,确保了数据集的多样性和全面性。
2. 数据集污染分析及其对模型性能的影响
FineMath数据集的一个关键考量是测试数据污染问题,即测试数据可能无意中被包含在模型的训练数据中。这种污染可能导致模型性能的高估,从而误导我们对模型泛化能力的理解。为了评估污染情况,研究人员采用了与GPT-3相同的方法来计算FineMath与Ape210K(一个公开的大规模中文数学应用题数据集)之间的n-gram重叠情况(下图)。通过这种方法,研究人员发现某些问题类型的重叠率明显高于其他类型,例如基础几何和比例问题。

为了深入了解这些重叠示例对模型性能的影响,研究人员将测试示例分为两个数据集:一个包含重叠示例的污染数据集和一个与Ape210k训练集没有重叠的干净数据集。在对比GPT-4和MathGLM-10B在这两个数据集上的表现时(下表),发现MathGLM-10B在污染数据集上的表现显著优于干净数据集。相比之下,GPT-4在两个数据集上的表现相当。这表明MathGLM-10B可能对重叠示例过拟合,而污染确实可以提高模型的性能。因此,为了确保模型之间的公平比较,并从FineMath基准测试中得出准确的结论,建议过滤掉训练集和FineMath基准测试之间的重叠示例。
 实验设计与评估的LLMs
实验设计与评估的LLMs1. 评估的LLMs类别与特点
在FineMath上进行的实验评估了多种LLMs,包括OpenAI开发的GPT-4和GPT-3.5-Turbo,以及专门为中文开发的LLMs和使用中文数学数据微调的LLMs。这些模型的参数范围从数十亿到数千亿不等,训练数据量从数十亿到数万亿不等(下表),这些因素都对模型的问题解决和推理能力至关重要。

2. 实验中使用的提示(Prompts)
实验在零样本设置下进行,研究人员尝试了多种提示来进行评估和分析。这些提示包括不提供任何额外信息,只输入问题到模型中;不解释原因,只提供问题答案;以及提供问题答案并解释原因等(下表)。

3. 主要结果与不同类别的表现分析
在17个数学应用题类别中,GPT-4在所有模型中表现最佳(下图),其准确率在不同类别中的表现差异显著(下表)。例如,在“混合运算”类别中,GPT-4的准确率最高,达到89%,而在“计数”类别中,准确率最低,为38%。GPT-4在概率和解析几何类别中的表现超过其他所有模型,提高了超过25%。GPT-3.5-Turbo在不同的数学应用题类别中的表现与GPT-4相似,但在概率、基础几何和解析几何上有超过20%的显著差异。


在数学推理步骤数量方面,LLMs的表现随着推理步骤的增加而降低(下图)。GPT-4在所有难度级别上保持了超过60%的准确率,对于只需要一个推理步骤的数学应用题,其准确率高达82%。而GPT-3.5-Turbo的准确率平均比GPT-4低10%。其他模型在不同的数学应用题类别和推理步骤数量上的表现也有所不同,显示出模型在数学推理能力上的差异。
 分析:评估过程中的关键因素
分析:评估过程中的关键因素1. 提示(Prompts)对模型准确性的影响
在评估过程中,提示(Prompts)的使用对模型产生的答案准确性有显著影响。例如,GPT-4在不同提示下的整体准确率分别为73%,59%,和58%(下表),这表明即使是简单的提示变化也可能导致模型性能的显著差异。

提示如“Answer:”可能会促使模型跳过推理过程,直接输出答案,从而增加了生成错误答案的可能性。下表是示例。

2. 生成式评估与选择题评估方法的比较
在初步实验中发现,一些新开发的LLMs不总是遵循指令,经常生成与答案无关的大量文本。因此,将数据转换为选择题形式,模型可以从中选择正确的答案。通过比较(下表),我们发现生成式评估与选择题评估方法在准确性上存在显著差异,差距可能超过10%。值得注意的是,将任务结构化为选择题形式似乎降低了高性能模型的准确性,同时提高了性能较差模型的准确性。选择题选项本身可能作为一种提示,影响模型的性能。

3. 模型响应长度与“信心”的关联
对模型生成的响应长度进行统计分析时,发现两个现象(下表)。首先,如GPT-4和GPT-3.5-Turbo这样的模型倾向于生成紧密围绕问题的响应,文本较短,这可能表明了高准确性模型的特点。其次,数学问题需要的推理步骤越多,模型生成的响应往往越长。我们推测,模型在回答问题时的“信心”影响了其响应的长度。在某些情况下,即使在指示模型只提供答案而不解释的情况下,模型仍会为难度较大的问题生成逻辑推理。
 结论与展望
结论与展望FineMath作为一个细粒度的基准测试集,为全面评估中文LLMs的数学能力提供了重要工具。通过对多个LLMs的评估,我们不仅关注模型的准确性,还深入分析了评估过程和方法,揭示了这些经常被忽视的因素对评估结果和我们对模型数学推理能力理解的显著影响。
FineMath的贡献在于它提供了一个综合性的基准,覆盖了中国小学数学的主要概念,并将数学问题分为17个类别,使得对LLMs的数学推理能力进行深入分析成为可能。此外,FineMath的污染分析使研究人员能够检查训练数据是否影响评估结果,从而确保了评估的公平性和有效性。
未来的研究方向可以包括进一步提高评估方法的公平性和有效性,例如通过更复杂的提示和任务形式来测试模型的推理和理解能力。此外,可以探索如何减少训练数据中的污染,以及如何提高模型在处理更复杂数学问题时的性能。随着LLMs的不断进步,FineMath及其后续版本有望成为评估和提升中文LLMs数学推理能力的重要工具。
