A critical review of large language model on software engineering: An example from chatgpt and automated program repair
Quanjun Zhang1, Tongke Zhang1, Juan Zhai2, Chunrong Fang1, Bowen Yu1, Weisong Sun1, Zhenyu Chen1
1State Key Laboratory for Novel Software Technology, Nanjing University, China
2Manning College of Information &Computer Sciences, University of Massachusetts China, United States
引用
Zhang Q, Zhang T, Zhai J, et al. A critical review of large language model on software engineering: An example from chatgpt and automated program repair[J]. arxiv preprint arxiv:2310.08879, 2023.
论文:https://arxiv.org/pdf/2310.08879
摘要
大型语言模型(LLM)越来越受到关注,并在各种软件工程(SE)任务中表现出了良好的性能,如自动程序修复(APR)、代码摘要和代码完成。本文试图在具有不同研究目标的干净APR基准上审查ChatGPT的错误修复能力。在ChatGPT的训练截止点之后,本文首先介绍EvalGPTFix,一个新的带有bug的基准测试,以及从2023年开始针对竞争性编程问题的相应固定程序。EvalGPTFix上的结果显示,ChatGPT能够在35轮独立的测试中使用基本提示修复151个有缺陷的程序中的109个,比最先进的LLMs CodeT5和PLBART的预测准确率分别高27.5%和62.4%。本文还调查三种类型的提示的影响,即问题描述、错误反馈和错误定位,导致另外34个已修复的错误。此外,本研究还从ChatGPT的交互性质提供额外的讨论,以说明具有9个额外修复错误的基于对话框的修复工作流的能力。
1 引言
近年来,现代软件系统规模不断扩大,导致其中的错误数量显著增加。为了降低修复这些错误的成本,人们提出了自动程序修复(APR)方法,旨在自动生成正确的补丁,减少人为参与的手动调试过程。现有的APR技术可以分为传统和基于学习的两种。传统技术中,基于模板的APR被认为是最先进的,它依赖于预定义的修复模板将有缺陷的代码转换为正确的代码。然而,修复超出预定义模板范围的未知错误具有挑战性。另一方面,基于学习的APR能够自动学习错误修复模式,利用深度学习的进步。基于学习的APR通常使用神经机器翻译(NMT)模型将有缺陷的代码片段翻译为正确的代码片段。尽管基于学习的APR解决了传统方法的局限性并展现了有希望的结果,但其性能取决于训练数据的质量和数量。
最近,由于其在各种软件工程(SE)任务中强大的编程语言处理能力,大型语言模型(LLMs)引起广泛关注。这些LLMs通常通过预训练和微调机制进行训练,即在大规模未标记的语料库上通过自监督训练来获得通用知识,并通过有监督训练在有限的标记语料库上进行微调以利于特定的下游任务。在现有的LLMs中,ChatGPT被广泛认为是当今最流行的语言模型之一,并且被来自许多领域的研究人员所研究,例如代码摘要、代码生成和测试生成。在APR领域,研究人员尝试直接利用ChatGPT生成正确的补丁,并取得不错的结果。
尽管ChatGPT表现出色,但其在评估中存在数据泄露的担忧。由于ChatGPT是在互联网上的大量数据上进行训练的,因此可能已经接触到了APR常用的数据集,如Defects4J和QuixBugs。因此,使用ChatGPT来修复来自这些数据集的Bug可能无法真实反映其修复能力,因为它可能已经知道了这些Bug的修复方案。类似的问题也可能存在于其他LLMs和代码相关任务中。此外,对于某些黑箱LLMs,例如GPT-4和Codex,其性能受到了内置记忆和缺乏透明的训练数据的影响,这在评估其在SE任务中的表现时是一个重要问题。
该研究旨在提高对数据泄露的重视,尤其是在将黑箱LLMs应用于某些与代码相关任务时。选择ChatGPT和APR作为LLMs和SE任务的代表性示例。他们构建了一个新数据集EvalGPTFix,包含来自Atcoder竞争性编程网站的有缺陷和正确的代码片段,爬取了2023年的竞赛用户提交。由于ChatGPT的知识截止日期为2021年9月,因此确认它无法访问EvalGPTFix中的样本。总的来说,研究证实了ChatGPT在修复EvalGPTFix数据集中的错误方面表现出色。在提供基本提示的情况下,ChatGPT修复了151个错误中的109个。当编程问题描述、错误消息和错误位置添加到提示中时,分别修复了额外的18个、25个和10个错误。此外,通过进行对话,ChatGPT修复了9个无法通过基本提示或包含错误信息的提示修复的错误。结果显示,ChatGPT的修复能力可以从更详细和更深入的提示中受益。
总的来说,本文的主要贡献如下:
揭示一个重要的问题,即在评估最近的ChatGPT修复软件错误时存在数据泄露问题。该问题一直被软件工程社区忽视,可能会导致之前采用黑箱LLMs(如ChatGPT和Codex)进行研究工作的显著偏见,而不考虑任何训练细节,比如预训练数据集和模型架构。构建了一个新的APR基准测试EvalGPTFix,来自竞争性编程网站Atcoder。EvalGPTFix包含151对Java中的错误和修复对,这些错误和修复对来自于2023年的编程提交中的失败和已接受的编程提交,以确保ChatGPT没有见过此数据集中呈现的特定代码片段。进行了深入的实证研究,探讨如何将ChatGPT应用于自动程序修复。具体来说,研究涉及三个方面:(1)ChatGPT与最先进的LLMs之间的系统比较,表明ChatGPT可以胜过CodeT5和PLBART;(2)对不同提示对结果的影响进行了广泛的评估分析;(3)对基于对话的修复工作流程对ChatGPT的影响进行了进一步的讨论。讨论将来应用ChatGPT和更先进的黑箱LLMs进行未来程序修复和其他SE研究时的当前紧迫挑战和前瞻性方向。2 研究设计
2.1 研究问题
在本文中,我们研究以下研究问题:
RQ1:ChatGPT在修复EvalGPTFix中的有缺陷程序方面的表现如何?
RQ2:不同的提示以及额外的程序信息如何影响ChatGPT的表现?
RQ3:与动态执行反馈的交互如何影响ChatGPT的表现?
2.2 EvalGPTFix建设
研究发现,ChatGPT已经掌握当前APR技术广泛使用的流行数据集(例如Defects4J和Quixbugs)的知识。因此,基于这些数据集研究ChatGPT的程序修复能力似乎不够严谨,因为ChatGPT可能会从其训练数据中找到给定错误的正确补丁,而不是自行修复错误。为解决此问题,本文构建了一个新的数据集。数据来自AtCoder,一个用于编程竞赛的平台。本文从2023年的比赛中提取编程问题,并获得用户提交的这些问题作为源数据。
(1) 原始数据收集:首先爬取从2023年开始的AtCoder编程比赛中所有Java语言提交。专注于APR社区中最受关注的Java语言。提交的在线判定结果可以分为六种类型:1)通过(AC);2)错误答案(WA);3)超时(TLE);4)编译错误(CE);5)运行时错误(RE);以及6)内存超限(MLE)。
(2) Bug修复对构建:对于同一问题上用户的所有提交,未通过的提交视为有缺陷的程序,通过的提交视为相应的正确程序。然后计算每对有缺陷和正确程序之间的标记差异,并仅保留那些差异小于6个标记的对。此差异通过将每个程序标记化为标记序列,并计算两个程序之间的标记级差异(包括替换、删除和插入),来计算。
(3) 测试案例挖掘:对于每个问题,HTML网站中的问题描述包含一些示例输入输出对。然而,这些测试用例不足以验证生成的补丁的正确性,因为在APR中存在过拟合问题[59]。本文进一步从AtCoder问题的专用数据库2中下载我们数据集中所有问题的所有可能的公共测试用例。
(4) 静态过滤:此外删除重复的提交以及代码标记超过500个的提交,考虑到修复模型处理长代码片段的能力的限制。还删除代码中的注释,因为注释可以提供有关有缺陷代码功能的信息,并且可能会影响APR工具在没有其他提示的情况下修复代码的判断。一些程序仅因类名未写为“Main”而导致编译错误。这与代码本身的逻辑无关,因此我们从数据集中删除此类数据。
(5) 动态过滤。对所有剩余提交与相应问题关联的每个测试案例进行执行。测试案例的运行时间限制和内存限制分别设置为10秒和1MB。在一对(s1,s2)中,其中s1代表有缺陷的代码,s2代表修复后的代码,如果发生以下三种情况之一,则将删除该对:(1)s1通过其相应问题的所有测试案例;(2)s1的错误类型与AtCoder网站上给出的类型不匹配(例如,通过运行测试案例发现s1产生“错误答案”错误,但在AtCoder上被标记为“编译错误”);以及(3)s2未通过其相应问题的任何测试案例。另外,由于我们本地设备和AtCoder平台环境之间存在差异,我们排除了MLE类型的错误,导致EvalGPTFix中有四种错误类型(即WA、TLE、CE和RE)。
(6) 基准统计。在所有预处理阶段之后,从进行工作时的两个最新编程竞赛(即初学者竞赛297和298)中,针对15个编程问题,获得了151对Java程序的Bug修复对。
2.3 ChatGPT 设置
本研究基于OpenAI发布的gpt-3.5-turbo模型的ChatGPT API进行实验。考虑到ChatGPT在多次查询相同输入时会生成不同的响应,对每个提示重复发送请求到ChatGPT,以提高生成更多正确补丁的可能性。
2.4 评价指标
本研究通过运行生成的补丁对测试套件进行评估,所有的测试案例都从AtCoder的网站下载,用于在编程竞赛期间评判用户的提交。每个编程问题平均有38个测试案例,足以判断程序是否能正确解决问题。我们对每个候选修复方案在问题的测试案例上运行,如果它通过了所有的测试案例,就被视为是一个正确的修复。对于每个有提示的Bug,在一个循环中连续向ChatGPT询问修复方案,如果在任何一轮中,ChatGPT能够为Bug生成一个正确的补丁,本文就认为ChatGPT能够成功修复该Bug,并退出循环。
2.5 对比技术
本文将以下两种最先进的LLMs视为基线技术。
CodeT5. 一种基于T5架构的预训练语言模型(即CodeT5),通过整合标记类型信息。CodeT5考虑了四个预训练任务的单模态(仅代码)和双模态(代码-文本对)数据,即遮蔽跨度预测、遮蔽标识符预测、标识符标记和双模态对生成。PLBART. 一种基于BERT架构的预训练编码器-解码器模型(即PLBART),用于执行程序和语言理解以及生成任务。PLBART考虑了三种去噪自编码策略,在预训练中通过重建由噪声函数损坏的输入文本,即标记遮蔽、标记删除和标记填充。3 结果分析
3.1 RQ1:ChatGPT的有效性
设计:在这个研究问题中,我们通过向ChatGPT呈现有缺陷的程序并要求它对其进行修复来探索ChatGPT的修复能力。我们只提供有缺陷的代码,没有提供任何其他关于错误的信息,以便了解ChatGPT在没有额外提示的情况下能够定位和修复错误的程度。RQ1的基本提示设计为“在下面的程序中有一个错误。尝试修复它,并以标记代码块的形式返回代码的完整修复。[CODE]”,其中[CODE]代表待修复的有缺陷程序。
由于ChatGPT即使在收到相同的句子提示时也会生成不同的回复,因此如果它无法为某个漏洞返回正确的修补程序,则有可能在再次查询时修复该漏洞。因此,仅询问ChatGPT一次来修复漏洞不能很好地反映其实际的修复能力。为了解决这个问题,对于每个漏洞,我们重复向ChatGPT发送相同的请求。如果某个漏洞的修补程序能够通过所有的测试用例,我们就不再继续要求ChatGPT修复该漏洞。在每一轮查询中,我们会检查是否相对于上一轮有任何新的漏洞被修复,如果连续三轮都没有修复更多的漏洞,那么整个过程就会停止。
结果:图1显示ChatGPT在每一轮请求中能够修复的漏洞数量。本研究最终查询ChatGPT共35轮,其中第33至35轮没有发现任何新修复的漏洞。在AtCoder的最近两场编程比赛中,共有151个漏洞,其中109个成功修复。总体上,随着轮次的增加,额外修复的数量呈下降趋势。在前三轮中,分别生成了51、19和5个额外的正确修补程序,这是一个显著的减少。之后,数量开始缓慢下降,在第11轮以后在0到2之间波动。这种减少趋势直到第35轮才停止,表明了ChatGPT的随机性质。

图1:对ChatGPT的每一轮查询中完全修复和新修复的bug的数量
随后,本文调查ChatGPT修复的漏洞类型。在EvalGPTFix中的151个漏洞中,有4种类型CE、TLE、RE和WA的漏洞,分别有23、4、22和102个。ChatGPT能够修复其中的22、4、11和72个,修复率分别为96%、100%、50%和71%。实验发现ChatGPT在定位和修复编译错误(CE)方面表现出色,这通常是由语法错误引起的。只要ChatGPT了解Java语法,就很容易识别这种错误,因此它可以在不考虑程序操作逻辑的情况下修复该漏洞,而这可能会更加复杂。图2显示了三个模型修复的bug的重叠,表明ChatGPT显著修复了其他两个模型无法修复的bug(即55个独特的bug)(即CodeT5存在13个独特的bugs,PLBART的没有)。结果表明,ChatGPT在修复编程问题方面明显优于现有的LLM。

图2:由三个模型修复的bug的重叠
回答RQ1:EvalGPTFix中ChatGPT的性能显示:(1)ChatGPT存在显著的随机性问题,例如,需要35轮独立的查询才能获得稳定的结果;(2)ChatGPT在修复不同类型的漏洞方面有效,例如,CE、TLE、RE和WA漏洞分别有96%、100%、50%和71%的正确修复率;(3)ChatGPT能够在EvalGPTFix中修复109个漏洞,召回率为72.19%,比CodeT5和PLBART分别多修复了30个和68个漏洞。
3.2 RQ2:提示符的影响
设计。本文进一步向ChatGPT的提示中添加有关漏洞的更多细节,期望ChatGPT能够从提示中获得更多有用的信息,以便能够修复更多的漏洞。本研究要求ChatGPT修复在仅提供基本提示时未修复的漏洞,如RQ1所述。本文考虑了三种额外的漏洞信息,问题描述、错误信息和漏洞位置。针对这三种漏洞信息分别设计三种基于原始提示的提示,如下所述。
1)问题描述指编程问题的解决目标。以下是具有问题描述的提示示例,“在下面的程序中有一个错误。尝试修复它,并以标记代码块的形式返回代码的完整修复。[CODE];该程序旨在解决这个问题:[PROBLEM]”。其中[CODE]代表有缺陷的程序,[PROBLEM]代表代码提交的编码问题。所有问题描述都来自AtCoder网站,包括问题的背景、程序的输入以及输出应该是什么样的。
2)错误信息通知ChatGPT错误的类型,触发错误的输入,期望的正确输出以及有缺陷程序的实际错误输出。对于四种类型的错误(即CE、TLE、RE和WA),提示略有不同,如下所示。
编译错误(CE)不会在编译时被任何输入触发,只告诉ChatGPT在代码中有一个编译错误。“在下面的程序中有一个错误。尝试修复它,并以标记代码块的形式返回代码的完整修复。[CODE];在代码中有一个编译错误。”超过时间限制(TLE)或运行时错误(RE),导致错误的输入以及预期输出被添加到提示中。提示符描述为“在下面的程序中有一个错误。尝试修复它,并以标记代码块的形式返回代码的完整修复。□[CODE]以下输入触发超过时间限制/运行时错误:□[INPUT]预期的输出是:□[EXPECT]”,其中[INPUT]表示导致测试用例失败的输入和[pade]表示应该由正确程序打印的输出。对于带有错误答案(WA)错误的bug,除了输入和预期输出外,提示符还包含buggry程序的实际输出。提示符描述为“以下程序中存在一个错误。请尝试修复它,并以Markdown代码块的形式返回完整的修复代码。[CODE];触发"Wrong Answer"错误的输入如下:[INPUT];期望的输出是:[EXPECT]”,“[OUTPUT]”表示给定填写“[INPUT]”输入的bug程序的输出。结果:在RQ1中未修复的42个错误中,分别向基本提示中添加错误信息、问题描述和错误位置时,分别修复了25、18和10个额外的错误。与RQ1类似,通过多次查询ChatGPT,直到连续三轮没有新的错误被修复。图3显示每一轮额外修复的错误数量。提示问题和错误位置仅需12和13轮,但提供错误信息时需要执行27轮,明显多于其他两个提示。可能的原因是前两个提示帮助ChatGPT专注于代码的较小范围,因此每轮生成的补丁相对更加稳定。相比之下,当提供错误消息时,补丁存在波动,因为错误可能由代码的不同部分引起。
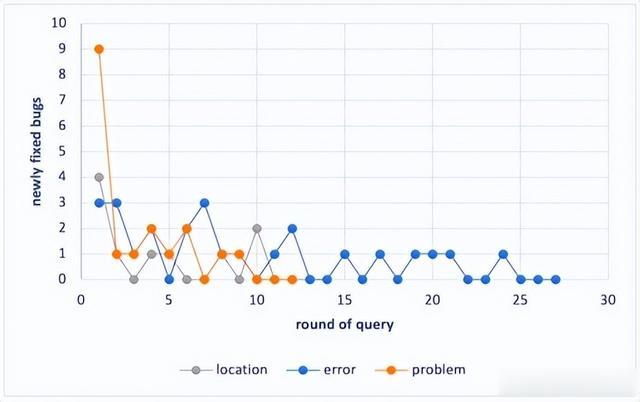
图3:每一轮中通过三种提示新修复的错误数量
图4展示了三种类型提示修复的错误之间的重叠关系。总共修复了34个错误,其中只有5个错误被三种提示都修复了。每个提示修复了另外两种提示无法修复的11、7和2个错误,表明不同的提示对成功修复错误的贡献不同。

图4:三种类型的提示修复的错误的重叠部分
问题描述的案例研究。ChatGPT通过问题描述获取关于程序目的的知识,因此它可以找出代码中与编码人员实际尝试做的事情不一致的部分。图5是一个编程问题和一个由ChatGPT修复的有缺陷提交。

图4:编程问题及ChatGPT缺陷修复提交
使用错误信息的案例研究。根据错误类型的信息以及程序失败的输入,ChatGPT还可以推断出bug的位置。列表4呈现了一个只有通过错误信息才能修复的bug。为了修复以下bug,ChatGPT被告知对于输入"9737738327422964222",期望的输出是"81970925269218254",但程序实际输出为"1251275726"。从提示中,ChatGPT可能推断出输出变量"cnt"发生了溢出,因此它将变量类型从int改为long。

图5:列表4
使用错误定位的案例研究。与其他两种类型的提示相比,带有错误位置的提示修复的错误较少。这可能归因于仅有有缺陷代码行提供的信息较少。然而,在某些情况下,bug位置会有所帮助。列表5呈现了一个只有在提示中提供错误位置时才被正确修复的bug。在尝试根据编程问题或错误消息修复时,ChatGPT犯了同样的错误:它不仅将方法"nextInt()"更改为"nextLong()",而且还在程序末尾将输出"sum - 1"修改为"sum"。提示中包含有缺陷位置在某种程度上缩小了ChatGPT尝试编辑的代码范围,从而阻止ChatGPT修改最初的正确行。

图6:列表5
回答RQ2:不同提示下的性能表明,ChatGPT可以从提供额外信息的更高级提示中受益。例如,与基本提示相比,通过错误信息、问题描述和有缺陷的代码行,可以修复25、18和10个更多的bug。
3.3 RQ3:对话研究
设计。在与ChatGPT的对话过程中,它能够意识到先前的对话,而其响应取决于当前提示和对话的上下文。根据现有研究发现通过进行更多的对话,ChatGPT可以修复更多的程序故障。本研究将重点放在给予ChatGPT基本提示或带有错误信息的高级提示时未修复的bug上。首先,采用用原始bug以及它所具有的错误类型提示ChatGPT,并获得一个补丁,然后将其测试在测试用例上。如果再次无法通过任何测试用例,将继续进行下一轮对话,在其中告诉ChatGPT由补丁引发的失败。特别是,在不同类型的bug中,对话提示也不同。提示为:“你的代码仍然存在编译错误/超时错误/运行时错误/错误答案错误,由输入触发:[INPUT];期望的输出是:[EXPECT];实际输出是:[OUTPUT];尝试再次修复它,并返回代码的完整修复。”对话将持续进行,直到ChatGPT成功修复bug或对话轮次达到五轮。ChatGPT的API具有有限的输入长度,当对话过长而无法处理时,简单地删除第二轮对话(第一轮包含了基本和必要的bug信息)。以上过程将重复,直到连续三次不再修复新的bug。
结果。通过对话,当仅提供单个提示时未修复的17个bug中,ChatGPT修复了其中的9个bug,证明了对话可以积极帮助ChatGPT修复bug。这可能是因为,尽管ChatGPT在第一次错误地修复了bug,但当我们通过告知补丁存在的问题来回应时,对正确修复的知识是累积的。通过这种方式,ChatGPT可以从先前的错误中学习,并被引导到bug的真实位置,从而提高了生成正确补丁的概率。
ChatGPT可以通过对话纠正错误的补丁主要有三种情况:(1) ChatGPT错误地确定了bug的位置,因此补丁面临与有缺陷代码相同的问题。在通知ChatGPT问题仍然存在之后,可能会找到一个新的行,这可能是bug真正所在的地方。(2) ChatGPT修复了最初的问题,但代码中还存在另一个bug,ChatGPT没有注意到。这通常发生在代码的不同位置存在多个bug时。例如,在对话的第一轮中,我们给出了一个由语法问题引起的编译错误的bug。ChatGPT纠正了语法,但出现了错误答案的问题。在这种情况下,ChatGPT被告知了错误的答案,并设法找到了另一个bug。(3) ChatGPT找到了多个可疑的代码片段,其中只有一部分是bug。在修复bug的同时,ChatGPT还将一些原本正确的代码变成了错误的代码。通过进一步的对话,ChatGPT可以意识到它以前的错误并生成正确的补丁。
对RQ3的回答:对话研究下的表现表明,ChatGPT可以通过与动态执行反馈的交互方式修复更难修复的bug,例如成功修复了之前提示中未修复的9个bug。
转述:石孟雨
